Command Palette
Search for a command to run...
GeneralVLA-2: Geometry-Aware Reconstruction and Governed Memory for Robot Planning
GeneralVLA-2: Geometry-Aware Reconstruction and Governed Memory for Robot Planning
Haoyu Wang Guoqing Ma Zeyu Zhang Yandong Guo Boxin Shi Hao Tang
Abstract
Generalist vision-language-action systems need object-centric 3D evidence and reusable manipulation experience to plan reliable robot trajectories. GeneralVLA provides a hierarchical interface for converting language and RGB-D observations into 3D end-effector paths, but two bottlenecks remain. First, monocular SAM3D-style object reconstruction can hallucinate pose and unseen geometry, while manipulation benefits from stable object shape when calibrated multi-view observations are available. Second, the original KnowledgeBank mainly retrieves semantically similar snippets and appends new knowledge, which makes it difficult to control memory quality, conflicts, confidence, and geometric relevance. To address the first challenge, we introduce GeoFuse-MV3D, a geometry-prior-guided MV-SAM3D reconstruction branch that verifies external geometry cues with input-view masks, applies soft visual-hull support, performs axis-wise refinement, and fuses only geometry while preserving appearance. To address the second challenge, we upgrade KnowledgeBank into a governed long-term memory system with explicit quality, confidence, lifecycle, verifier, and conflict metadata, together with precision-oriented retrieval. Finally, we evaluate the reconstruction branch on GSO-30 and the memory module on Terminal-Bench 2.0 and SWE-Bench Verified; GeoFuse-MV3D improves over the MV-SAM3D baseline by reducing CD and LPIPS by 2.20% and 2.02% while increasing PSNR and SSIM by 2.36% and 1.03%, and KnowledgeBank improves over ReasoningBank by 4.53% on Terminal-Bench SR and 3.73% on SWE-Bench resolve rate, while reducing AS by 4.95% and 5.65%, respectively. Code: https://github.com/AIGeeksGroup/GeneralVLA-2. Website: https://aigeeksgroup.github.io/GeneralVLA-2.
One-sentence Summary
GeneralVLA-2 integrates GeoFuse-MV3D, a geometry-prior-guided multi-view reconstruction branch that reduces object hallucination through visual-hull support and axis-wise refinement, with a governed long-term memory system that upgrades KnowledgeBank using quality, confidence, and conflict metadata for precision-oriented retrieval, achieving improved reconstruction fidelity on GSO-30 and higher task success rates on Terminal-Bench 2.0 and SWE-Bench Verified.
Key Contributions
- GeoFuse-MV3D extends MV-SAM3D by treating external 3D estimates as geometry priors, validating them against input masks, and applying soft visual-hull support, axis-wise refinement, and geometry-only fusion while preserving fixed-view appearance. On the GSO-30 benchmark, this method reduces Chamfer Distance by 2.20% and LPIPS by 2.02% while increasing PSNR by 2.36% and SSIM by 1.03% over the MV-SAM3D baseline.
- KnowledgeBank is upgraded into a governed long-term memory system where records store quality, confidence, lifecycle state, verifier metadata, and conflict links, enabling precision-oriented retrieval instead of purely semantic matching. On Terminal-Bench 2.0, this governed memory improves success rate by 4.53% and reduces action steps by 4.95% over ReasoningBank; on SWE-Bench Verified, it lifts resolve rate by 3.73% and lowers steps by 5.65%.
- An experimental evaluation benchmarks the GeoFuse-MV3D reconstruction branch on GSO-30 and the governed memory module on Terminal-Bench 2.0 and SWE-Bench Verified, confirming consistent improvements in reconstruction fidelity and agent planning performance.
Introduction
Robot manipulation planners like GeneralVLA decompose the problem into perception, 3D reasoning, and trajectory execution, relying on object‑centric geometry and reusable experience to produce safe, interpretable end‑effector paths. Prior work suffers from two weaknesses: monocular SAM3D‑style reconstruction often hallucinates unseen backside structure and pose, which can corrupt grasp clearance and collision checks, and the original KnowledgeBank retrieves past episodes by semantic similarity alone, making it unable to manage memory quality, staleness, conflicts, or geometric relevance to the current scene. The authors address both gaps in GeneralVLA‑2. They introduce GeoFuse‑MV3D, a multi‑view reconstruction branch that treats external geometry estimates as priors, verifies them against input masks, applies soft visual‑hull and axis‑wise refinement, and performs conservative geometry‑only fusion to supply stable shape evidence. In parallel, they upgrade the memory module into a governed long‑term system where each record carries confidence, lifecycle, verifier, and conflict metadata, enabling precision‑oriented retrieval that filters unsafe or inapplicable experience before it reaches the planner.
Method
The authors present GeneralVLA-2, a system designed for tabletop manipulation tasks that decomposes the problem into affordance perception, 3D trajectory planning, and low-level execution. As shown in the figure below, the pipeline builds object-centric 3D evidence from calibrated observations, conditions a 3D-capable planning agent on both refined object geometry and a governed KnowledgeBank, and finally executes the planned trajectory through a robot grasping and motion module.
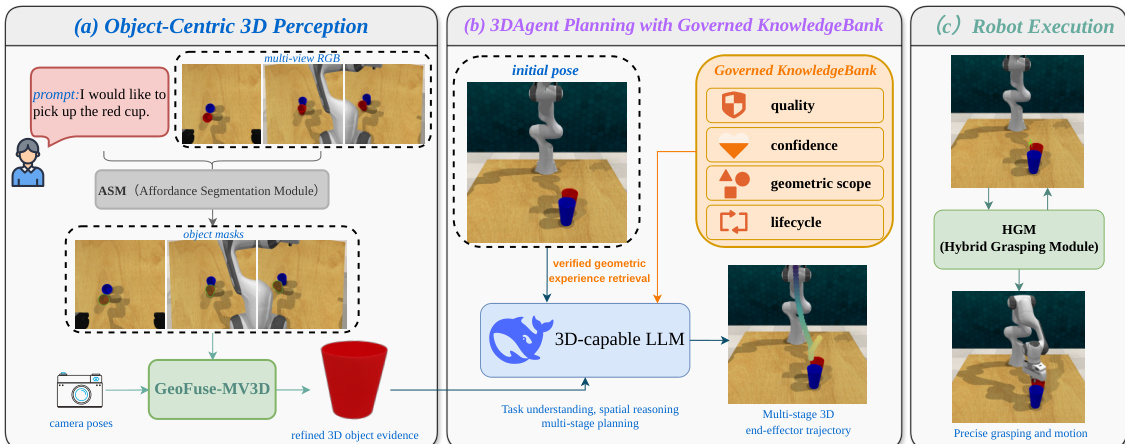
To complement the original affordance segmentation, the authors introduce GeoFuse-MV3D, a conservative multi-view reconstruction branch. When calibrated multi-view RGB-D observations are available, this branch reduces monocular hallucination by using fixed input views and masks to regularize geometry. Refer to the framework diagram for the detailed architecture of this branch. The process begins with multi-view inputs, including RGB observations, object masks, camera intrinsics, and poses. An initial Gaussian object is produced via a baseline multi-view reconstruction method.
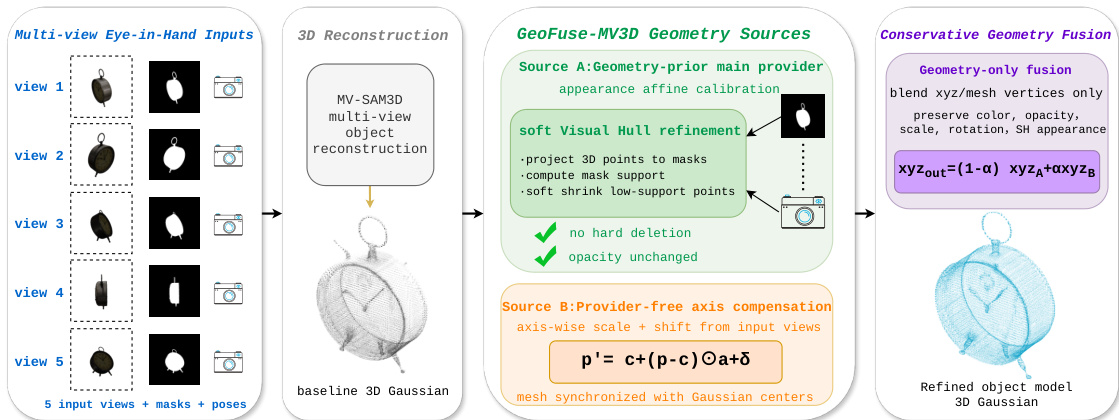
GeoFuse-MV3D utilizes two complementary geometry sources. Source A incorporates an external geometry-prior provider and applies lightweight appearance affine calibration. Source B is an input-view axis-compensation branch that operates without an external provider. Both sources are checked against input masks to compute a mask-consistency score s(p). Instead of deleting low-support points, the system converts low support into a small inward geometry correction p′=c+(p−c)(1−λ(p)), where c is the object center and λ(p) is bounded by a small maximum shrink ratio. A low-dimensional axis-wise correction is then applied to the Gaussian centers, and the same transform is synchronized to mesh vertices. Finally, the system blends only the geometry coordinates of the two sources while preserving color, opacity, scale, rotation, and spherical-harmonic appearance fields from the trusted source.
The authors also replace the original append-oriented memory with a governed KnowledgeBank to improve the mid-level planner. As shown in the figure below, this memory subsystem writes verifier-labeled memories, retrieves high-quality records, and manages their lifecycle before conditioning the 3DAgent planner.
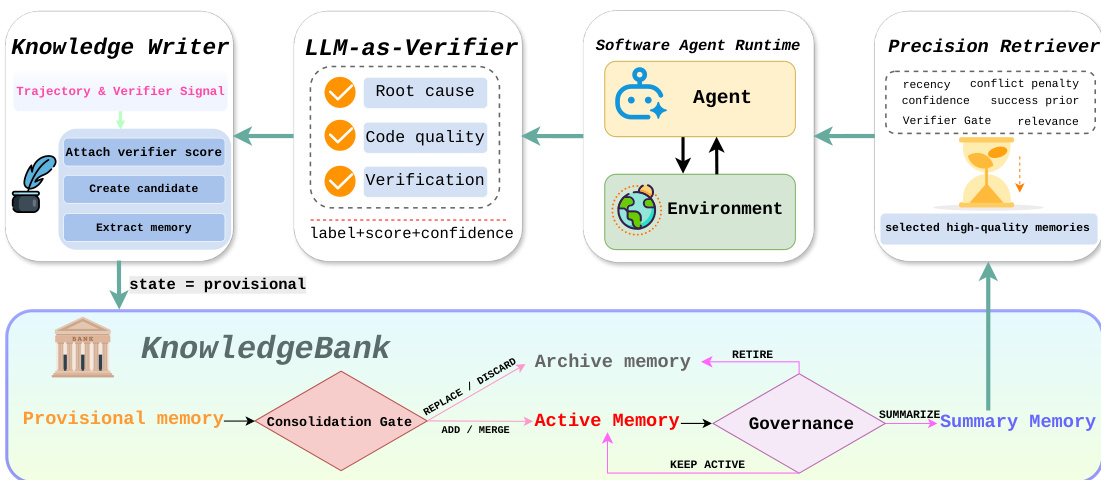
Each reusable manipulation lesson is stored as a structured record m=(q,c,y,z,κ,R,L,v), where q is the source query, c is the reusable content, y is the memory type, z is the lifecycle state, κ is confidence, R is a verifier-derived quality score, L stores conflict or supersession links, and v stores verifier metadata. After a task, a verifier scores candidate knowledge using criteria such as task completion, spatial consistency, and collision safety. Retrieval is precision-oriented, combining text relevance, confidence, success priors, and recency while penalizing conflicts and staleness. The retrieved records are rendered as bounded planning context for the 3DAgent, where procedural memories serve as optional hints and failure memories act as constraints. Consolidation operations, including add, merge, replace, discard, summarization, and archival, are performed under a fixed active-memory budget.
At inference time, the 3DAgent receives the language instruction, the current 3D scene representation, the refined object evidence from GeoFuse-MV3D when available, and the structured KnowledgeBank block. It then outputs a multi-stage end-effector trajectory expected by the low-level policy. This separation ensures compatibility with the original robot stack while significantly improving the geometry and memory evidence used for planning.
Experiment
The evaluation first validates GeoFuse-MV3D on the GSO-30 multi-view benchmark under identical input conditions to the MV-SAM3D baseline, showing consistent improvements across all reconstruction metrics through geometry-prior guidance and conservative fusion. The KnowledgeBank module is then tested in isolation on Terminal-Bench and SWE-Bench, where governed memory admission, verification, and lifecycle management yield higher success rates and lower average steps than append-only retrieval across multiple backbones. In robotic planning, the full system achieves training-free success on all 14 RLBench tasks, outperforming prior methods and demonstrating that removing KnowledgeBank degrades performance, while real-world experiments confirm reliable execution on four manipulation tasks with varying object poses. Overall, the results indicate that hierarchical visual-language-action systems benefit from more faithful object geometry and controlled long-term memory, though performance remains dependent on calibrated inputs and the method is intentionally conservative.
The authors evaluate GeoFuse-MV3D on the GSO-30 benchmark against the MV-SAM3D baseline using identical input views and configurations. Results show that GeoFuse-MV3D consistently improves all four reconstruction metrics, demonstrating better geometric and appearance quality through geometry-prior guidance and mask verification. GeoFuse-MV3D outperforms the MV-SAM3D baseline across all evaluated reconstruction metrics. The method achieves lower Chamfer Distance and LPIPS scores, indicating improved geometric accuracy and perceptual quality. PSNR and SSIM scores are higher for GeoFuse-MV3D, reflecting enhanced image fidelity and structural similarity.

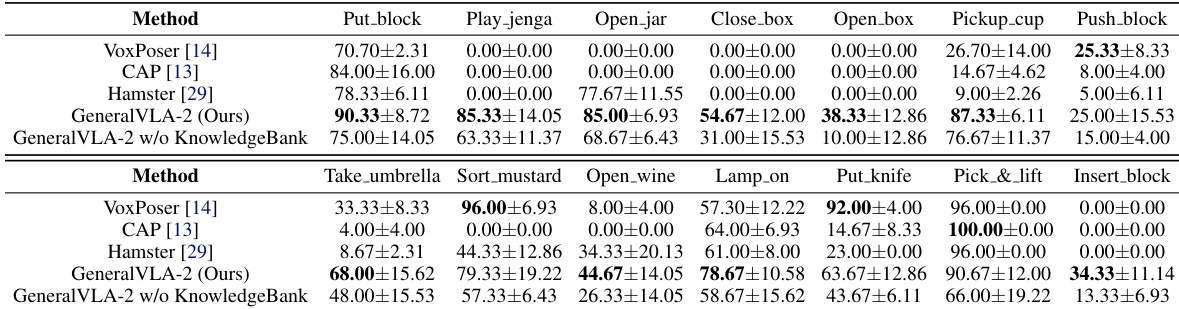
The authors evaluate GeneralVLA-2 on a set of robotic planning tasks in simulation, comparing it against baselines like VoxPoser, CAP, and Hamster. Results show that GeneralVLA-2 achieves the highest success rates across the majority of tasks and is the only method to successfully generate trajectories for all evaluated tasks. Additionally, an ablation study removing the KnowledgeBank module demonstrates a consistent drop in performance, highlighting the importance of governed experience reuse for trajectory planning. GeneralVLA-2 outperforms baseline methods in success rate across most of the simulation tasks. GeneralVLA-2 is the only method capable of generating successful trajectories for all evaluated tasks, whereas baselines cover fewer tasks. Removing the KnowledgeBank module consistently lowers the success rate, indicating that retrieved experience guidance improves planning performance.
The authors evaluate the KnowledgeBank module on long-horizon agent benchmarks using four different model backbones. Results show that the full configuration consistently achieves the highest success and resolve rates while requiring the fewest average steps compared to ablated variants. This supports the conclusion that explicitly governing memory admission, retrieval, and lifecycle is more effective than simple semantic retrieval. The full KnowledgeBank variant outperforms all ablated versions across all metrics and model backbones. Removing specific governance components like admission or lifecycle management consistently degrades performance and increases the steps required to solve tasks. The semantic retrieval baseline performs the worst, indicating that governed memory management significantly improves experience reuse and efficiency.
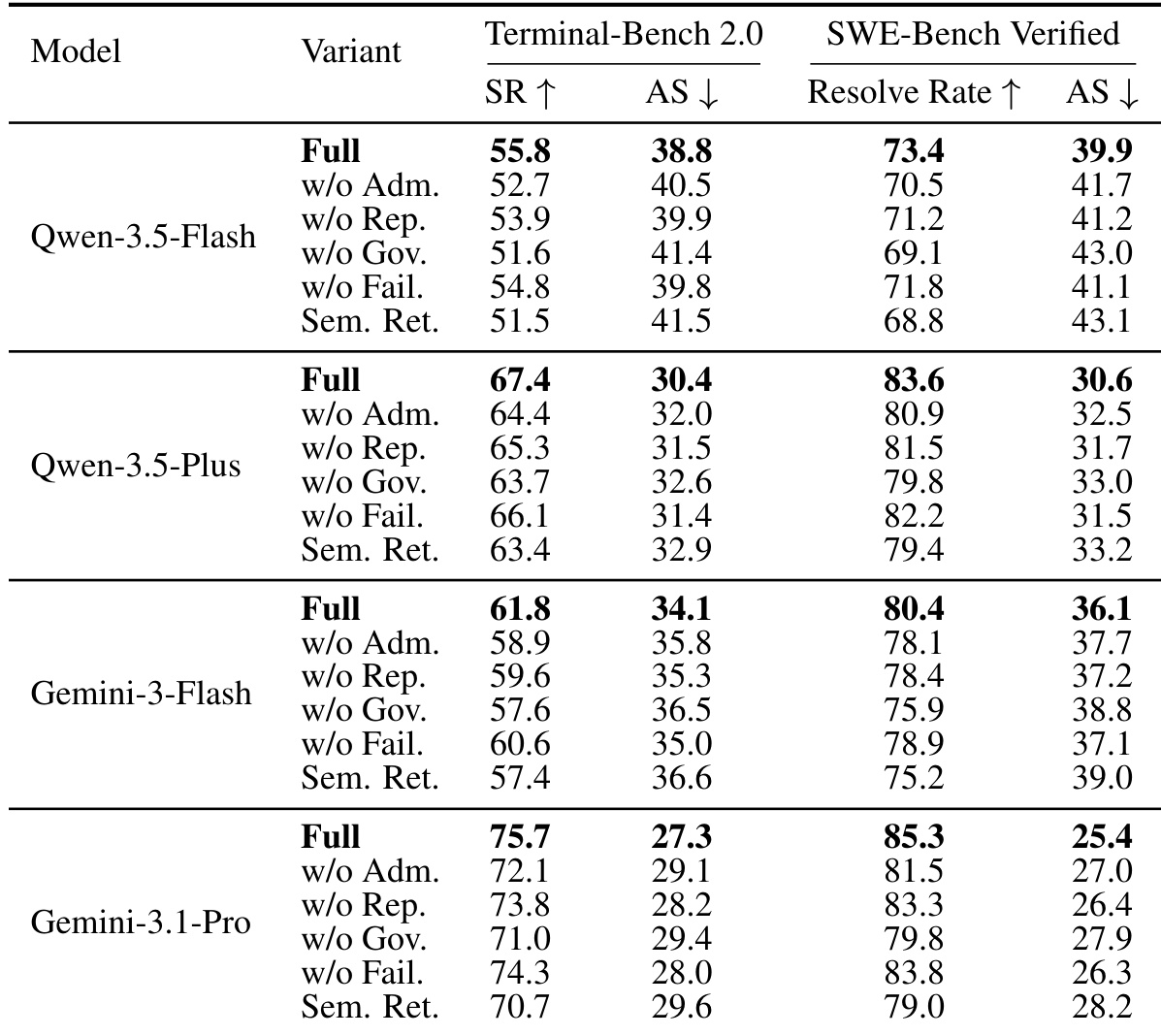
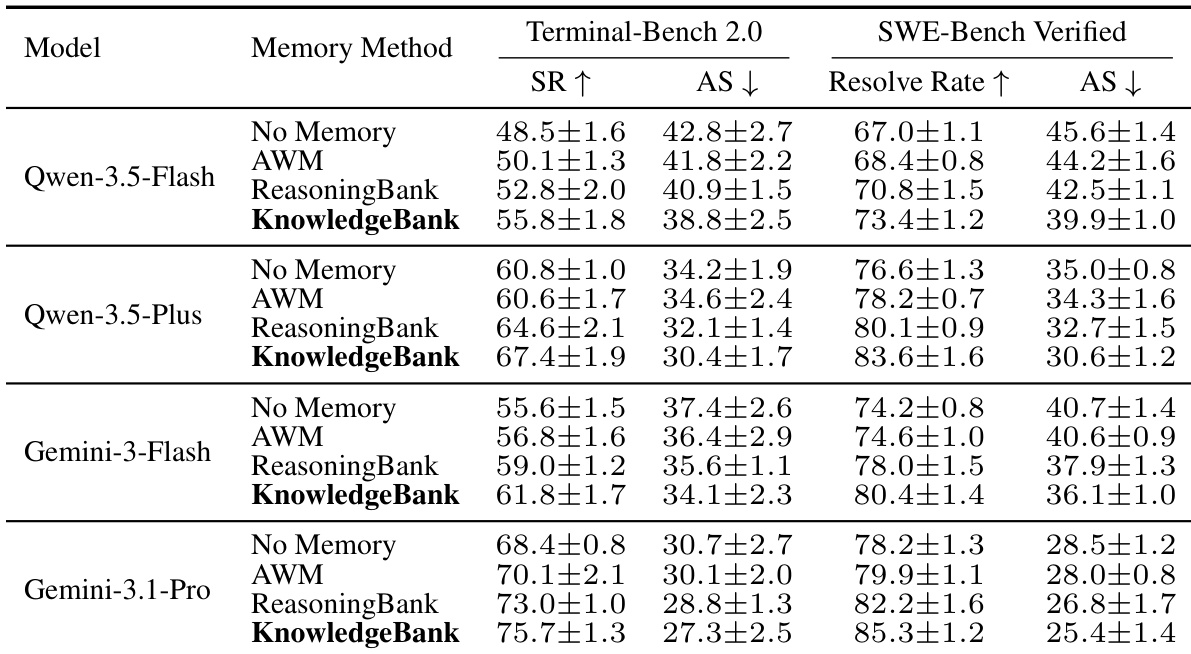
The authors evaluate the KnowledgeBank memory-governance module on Terminal-Bench 2.0 and SWE-Bench Verified across four model backbones. Results indicate that KnowledgeBank consistently outperforms baseline methods like ReasoningBank and AWM in terms of success rates and efficiency. This supports the design choice that explicitly governed memory admission and retrieval improves experience reuse. KnowledgeBank achieves the highest success and resolve rates across all tested models compared to other memory methods. The approach consistently reduces the average steps required for problem solving, indicating greater efficiency. Performance improvements are observed across multiple model backbones, validating the robustness of the memory governance approach.
The authors evaluate GeneralVLA-2 on real-world robotic manipulation tasks in a training-free setting, comparing it against CAP and RoboPoint baselines. Results indicate that GeneralVLA-2 achieves the highest success rates across all four tested tasks, significantly outperforming the baseline methods which struggle with certain actions like opening drawers. GeneralVLA-2 consistently outperforms the zero-shot baselines CAP and RoboPoint across all evaluated real-world manipulation tasks. The method demonstrates robust performance in tasks where baseline models achieve zero success, such as opening a drawer and moving a spray bottle. GeneralVLA-2 maintains a leading success rate in complex manipulation tasks like sorting objects and opening jars compared to the baselines.

GeoFuse-MV3D is evaluated on the GSO-30 benchmark against MV-SAM3D using identical inputs, where it consistently improves all reconstruction metrics by leveraging geometry-prior guidance and mask verification for better geometric and appearance quality. GeneralVLA-2 is tested on simulated robotic planning tasks and real-world manipulation, outperforming baselines like VoxPoser, CAP, and RoboPoint, and is the only method to generate successful trajectories across all simulation tasks while excelling on challenging real-world actions such as drawer opening. The KnowledgeBank module is assessed on long-horizon agent benchmarks and software engineering benchmarks across multiple backbones, with the full governed memory configuration consistently achieving the highest success rates and fewest steps compared to ablated variants and simple semantic retrieval baselines. Across all experiments, the findings validate that explicit governance of memory admission, retrieval, and lifecycle, along with geometry-prior integration, substantially improves performance, robustness, and efficiency over baseline approaches.