Command Palette
Search for a command to run...
Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
Memory is Reconstructed, Not Retrieved: Graph Memory for LLM Agents
Shuo Ji Yibo Li Bryan Hooi
Abstract
Despite recent progress, LLM agents still struggle with reasoning over long interaction histories. While current memory-augmented agents rely on a static retrieve-then-reason paradigm, this rigid pipeline design prevents them from dynamically adapting memory access to intermediate evidence discovered during inference. To bridge this gap, we propose MRAgent, a framework that combines an associative memory graph with an active reconstruction mechanism. We represent memory as a Cue-Tag-Content graph, where associative tags serve as semantic bridges connecting fine-grained cues to memory contents. Operating on this structure, our active reconstruction mechanism integrates LLM reasoning directly into memory access, allowing the agent to iteratively explore and prune retrieval paths based on accumulated evidence. This ensures that memory retrieval is dynamically adapted to the reasoning context while avoiding combinatorial explosion caused by unconstrained expansion. Experiments on the LoCoMo benchmark and LongMemEval benchmark demonstrate significant improvements over strong baselines (up to 23%), while substantially reducing token and runtime cost, highlighting the effectiveness of active and associative reconstruction for long-horizon memory reasoning.
One-sentence Summary
MRAgent replaces static retrieval pipelines with a Cue-Tag-Content memory graph and an active reconstruction mechanism that integrates reasoning directly into memory access to iteratively prune retrieval paths based on accumulated evidence, yielding up to 23% performance gains on the LoCOMO and LONG-MEMEVAL benchmarks while reducing token and runtime costs.
Key Contributions
- The MRAgent framework introduces an active memory reconstruction paradigm that integrates LLM reasoning directly into the retrieval process, enabling dynamic adaptation of search strategies based on accumulated intermediate evidence.
- A Cue-Tag-Content memory graph structure explicitly encodes semantic associations between fine-grained cues and memory contents, allowing the agent to identify promising retrieval paths and prune irrelevant branches.
- Theoretical analysis proves that active retrieval policies are strictly more expressive than passive alternatives. Evaluations on the LoCOMO and LONG-MEMEVAL benchmarks demonstrate up to 23% performance gains alongside substantial reductions in token and runtime costs.
Introduction
Long-horizon LLM applications like interactive assistants require retaining extensive interaction histories, but fixed context windows fundamentally limit sustained reasoning over extended tasks. External memory systems are therefore essential for maintaining continuity, yet prior approaches rely on a static retrieve-then-reason pipeline that treats memory as a passive database. These systems depend on fixed top-k selection or predefined graph traversal, preventing agents from dynamically adapting their search strategy as new evidence emerges during inference. The authors leverage a Cue-Tag-Content memory graph to transform memory access into an active, multi-step reconstruction process. By embedding associative tags that bridge contextual cues to detailed content, they enable the LLM to iteratively explore and prune retrieval paths based on intermediate reasoning. This approach dynamically aligns memory access with the evolving reasoning context, significantly improving long-horizon performance while reducing computational overhead.
Dataset
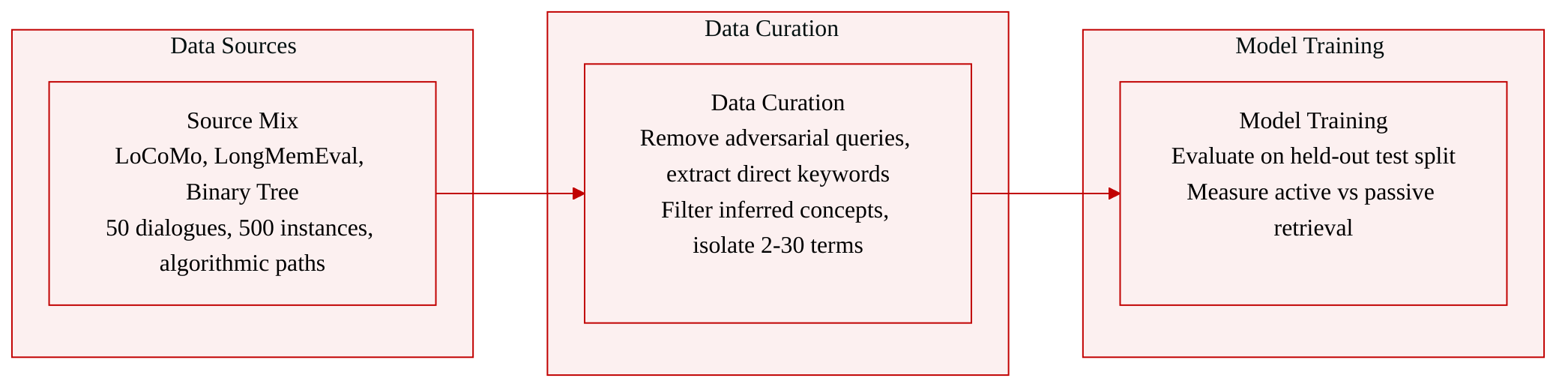
- Dataset Composition and Sources: The authors assemble a hybrid evaluation suite that pairs two established conversational memory benchmarks with a synthetic retrieval distribution. LoCoMo originates from a human and LLM generation pipeline, LongMemEval provides timestamped chat sessions, and the Binary Tree Needle in a Haystack task is algorithmically generated to isolate retrieval mechanics.
- Subset Details: LoCoMo comprises 50 extended dialogues that span up to 35 sessions, average 300 turns per conversation, and include roughly 200 question answer pairs. LongMemEval offers approximately 500 evaluation instances from the LongMemEval S setting, each paired with a chat history of about 115K tokens. The synthetic Binary Tree distribution constructs a complete binary tree of depth d = T - 1 containing n = 2^{d+1} - 1 nodes, with a uniformly sampled target leaf index and an answer label y drawn from P_Y.
- Data Usage: The paper utilizes these collections strictly for evaluation rather than training. The authors apply LoCoMo and LongMemEval to assess how models handle multi hop reasoning, temporal tracking, and preference retention across sustained interactions. The Binary Tree distribution measures the performance gap between active navigation and passive guessing by requiring the model to follow a deterministic path to uncover the answer.
- Processing and Metadata Construction: The team removes adversarial questions from LoCoMo to match baseline constraints and prioritize memory reconstruction over unanswerable query detection. For the synthetic tree, they engineer node payloads to explicitly store the next path bit for every prefix node while reserving the target leaf payload for the final answer, ensuring all non target information remains independent of y. Additionally, the authors employ a strict keyword extraction prompt to isolate 2 to 30 explicit terms per sentence, filtering out inferred concepts and enforcing direct text matching for entities, topics, and temporal markers.
Method
The authors propose a reconstructive memory agent that frames memory access as a sequential, stateful decision process rather than a static lookup. This paradigm shift moves beyond traditional passive retrieval, which relies on fixed similarity scores or predefined graph expansions. Refer to the framework diagram for a high-level comparison of these retrieval strategies.
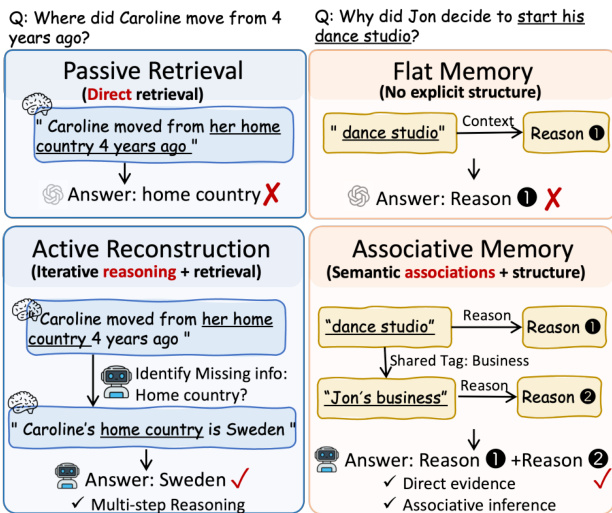
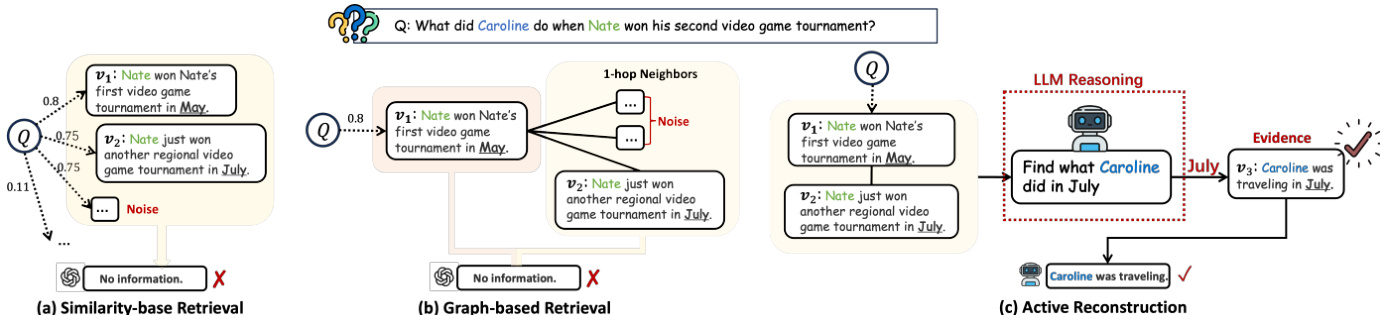
Existing memory systems typically employ similarity-based retrieval or graph-based neighbor expansion. Similarity-based methods compute a relevance score between the query and memory units, selecting the top-k matches. Graph-based approaches extend this by retrieving seed nodes and their predefined neighbors. However, both paradigms suffer from noise accumulation and an inability to adapt to intermediate findings. As shown in the figure below, passive retrieval often retrieves irrelevant events or fails to uncover information that is not directly linked in a static structure.
To overcome these limitations, the authors draw inspiration from cognitive neuroscience, where human recall unfolds sequentially through cue-activated memory indices that bias subsequent retrieval. This biological mechanism motivates the design of a Cue-Tag-Content architecture. The figure below illustrates the functional correspondence between human memory reconstruction and the proposed model.
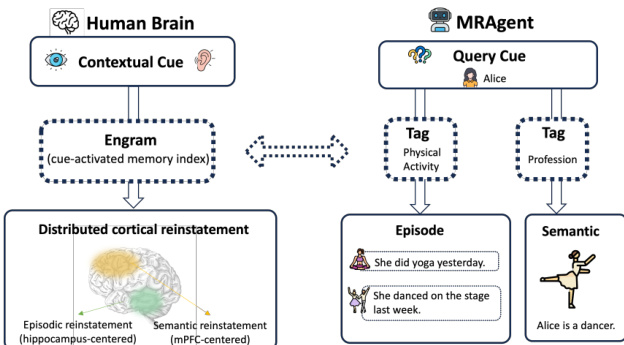
The memory system is organized as a heterogeneous graph containing fine-grained cues, associative tags, and memory contents. Tags serve as intermediate structures that summarize relational patterns between cues and contents, decoupling associative reasoning from content-level retrieval. The memory graph is further partitioned into multi-granular layers, including an episodic layer for concrete events, a semantic layer for stable knowledge, and an abstraction layer for topic-level patterns. Refer to the architecture overview for a detailed breakdown of the memory construction and reconstruction pipeline.
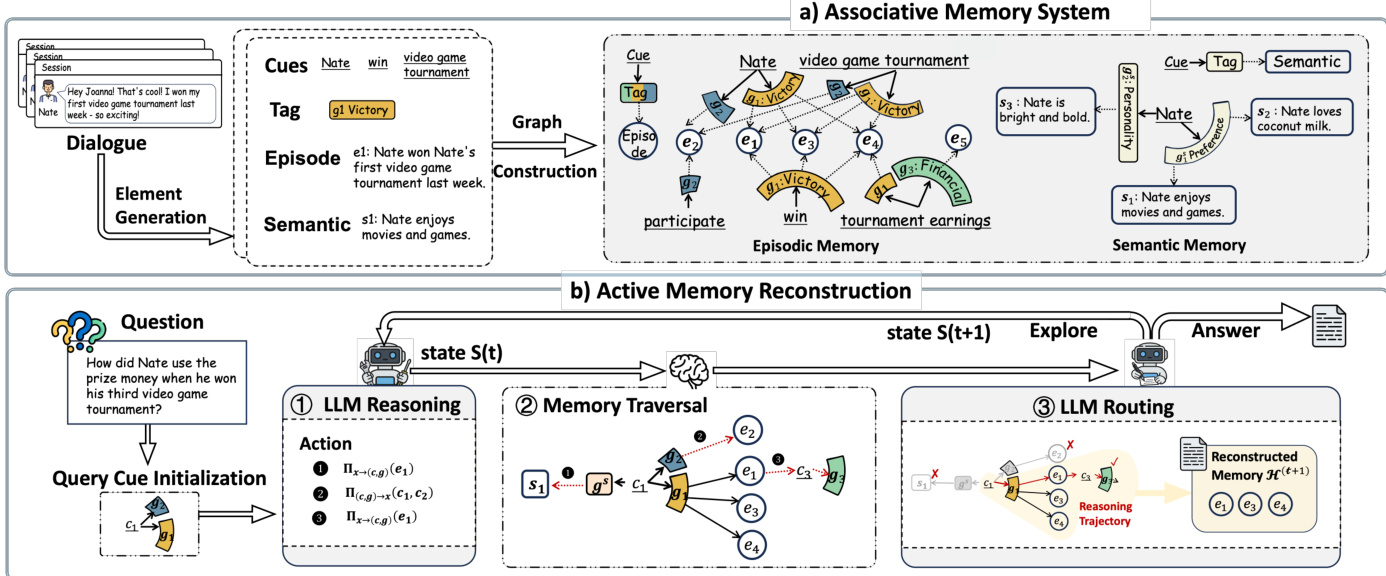
Memory access is formalized as an iterative reconstruction process that maintains an explicit state comprising an active set of candidate nodes and an accumulated context of evidence. At each step, a large language model reasons over the current state to select traversal actions, which include forward expansion along cue-tag-content relations and reverse traversal to activate new cues from retrieved content. The model then executes these actions to generate a candidate set, followed by an LLM-guided routing step that prunes irrelevant branches and updates the reconstruction state. This closed-loop mechanism allows the agent to dynamically adjust its reasoning trajectory based on intermediate evidence.
The step-by-step execution of this process is detailed in the accompanying algorithm. Given a query, the system initializes the active set by matching fine-grained cues against the memory graph. The agent then enters a loop where it selects traversal actions, applies controlled memory traversal to expand the candidate set, and performs routing to update the active set and accumulated context. The figure below demonstrates a concrete example of this iterative reconstruction, showing how the agent progressively gathers evidence across multiple reasoning turns to answer a complex multi-hop query.

The mathematical formulation of this process defines the reconstruction state at step t as a pair of the active set and the reconstructed context. The active set serves as candidates for the next traversal step, while the context conditions subsequent directions. The agent selects a subset of traversal actions based on a state-dependent function, applies the corresponding operators to generate new candidates, and updates the state through a routing function that evaluates semantic associations. This iterative procedure continues until a stopping condition is met or the maximum step limit is reached, at which point the accumulated context is used to generate the final answer.
Experiment
For each question i, let Ei∗ denote the set of annotated ground-truth evidence items. and let E^i denote the set of evidence items retrieved by the agent. Evidence Recall is computed as:
Recall=N1i=1∑N∣Ei∗∣∣E^i∩Ei∗∣,where N is the total number of evaluation questions. This metric reflects the effectiveness of the retrieval process in recovering relevant supporting evidence, independent of final answer generation.
- D.4. Implementation
the paper use GPT-4o-mini as the LLM judge with temperature set to 0.0. Each method is evaluated three independent times, and the paper report the mean and standard deviation of the judge scores across runs. To ensure comparable compute budgets across methods, the paper cap the agent's reasoning to at most 8 turns per query, and allow up to 10 tool invocations per turn. Agents may terminate early if a stopping condition is met before exhausting the budget.
- D.5. Detailed Results on LONGMEMEVAL
the table presents detailed results on LONGMEMEVAL under different evaluation settings, evaluated by F1 and LLM-Judge.
- D.6. Budget Sensitivity Analysis of Multi-step Reconstruction
the figure analyzes the trade-off between the number of reasoning turns and per-turn parallel retrieval on multi-hop questions in LoCoMo. the paper vary the per-turn retrieval budget (K), corresponding to the maximum number of parallel tool calls allowed within a single reasoning turn, and the maximum number of reasoning turns (T), while keeping other settings fixed
the table. Performance on LONGMEMEVAL evaluated by F1 and LLM-Judge ↑. Best and second-best results among Gemini-backbone methods are marked in bold and underline, respectively. MRAgent* uses Claude for retrieval while memories are constructed by Gemini.

the figure. Performance on multi-hop queries in LOCOMO as a function of the number of reasoning turns (T) and the per-round retrieval budget (K), evaluated under the Claude backbone using LLM-Judge (J).
Reconstruction depth cannot be substituted by increased parallel exploration. As the number of reasoning turns T increases, accuracy improves steadily and monotonically across all values of K, with deeper reconstruction yielding substantially higher performance. In contrast, increasing the per-turn retrieval budget K leads to only limited gains that quickly saturate. These results indicate that while parallel exploration increases retrieval breadth within a single reasoning turn, it cannot replace the sequential composition of evidence enabled by multi-turn reconstruction.
- D.7. Evidence Coverage by Retrieval Operators
To analyze how different retrieval operators contribute to memory reconstruction, the paper examine the evidence coverage of each tool on Locomo, aggregated by question category. the table reports the coverage rates of individual operators, reflecting their functional roles during reconstruction.
Different retrieval operators specialize in distinct query structures. Temporal questions are predominantly resolved through query_conversation_time, which accounts for the majority of temporally grounded evidence. Multi-hop questions rely heavily on query_tag_events and query_topic_events, indicating that associative expansion over tags and topics is essential for recovering evidence distributed across multiple episodes. In contrast, open-domain questions exhibit more balanced coverage across multiple operators, reflecting the need to integrate episodic, semantic and contextual information. Overall, these results demonstrate that MRAgent performs structured, operator-dependent memory reconstruction. Rather than relying on uniform or similarity-driven retrieval, the agent selectively activates different operators based on query structure, resulting in differentiated evidence acquisition patterns.
The the the table illustrates the evidence coverage rates of different retrieval operators across various question categories. It demonstrates that retrieval strategies are specialized, with temporal queries relying heavily on conversation time tools. In contrast, open-domain questions show a more balanced utilization of multiple operators to integrate diverse information. Temporal queries are predominantly addressed by the conversation time retrieval operator, which shows the highest coverage for this category. Multi-hop questions rely heavily on associative tools like tag and topic event queries to recover distributed evidence. Open-domain questions exhibit a more uniform distribution of retrieval operator usage compared to the specialized patterns observed in other query types.
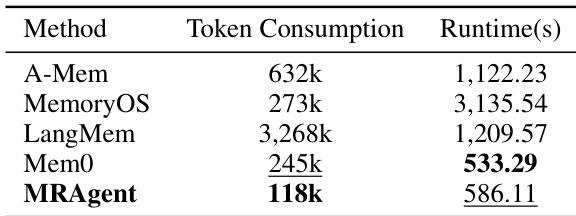
The the the table presents a comparison of computational costs, specifically token consumption and runtime, between MRAgent and several memory-augmented baselines on the LONGMEMEVAL benchmark. MRAgent demonstrates superior information efficiency, requiring the lowest token count and maintaining a competitive execution speed compared to most existing methods. MRAgent achieves the lowest token consumption among all compared methods, significantly reducing the prompt size required for memory access. The method exhibits a substantially shorter runtime than MemoryOS and LangMem, indicating faster execution despite its complex reasoning capabilities. This efficiency is attributed to a lightweight memory construction phase and selective retrieval that prunes irrelevant paths, unlike baselines that repeatedly summarize history.
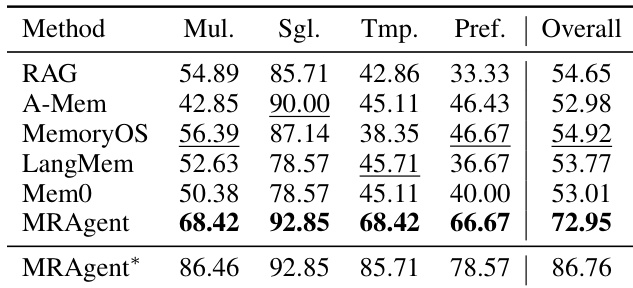
The authors evaluate MRAgent on the LONGMEMEVAL benchmark, comparing it against baselines such as RAG, A-Mem, MemoryOS, LangMem, and Mem0. Results indicate that MRAgent consistently outperforms these competitors across all question types, including multi-session, single-session, temporal reasoning, and preference queries. Additionally, the MRAgent* variant achieves the highest performance scores across the board. MRAgent achieves the best results among the primary baselines in all evaluated categories. The MRAgent* variant secures the highest scores in multi-session, temporal reasoning, and preference tasks. Both MRAgent and MRAgent* demonstrate superior capability in single-session user queries compared to other methods.
The authors analyze the average number of reasoning turns required for different query types to assess the efficiency of multi-turn memory reconstruction. The findings indicate that query complexity correlates with the depth of reasoning needed, with multi-hop questions requiring the most iterative steps to converge compared to simpler categories. Multi-hop queries require the highest average number of reasoning turns among the tested categories. Single-hop queries demonstrate the lowest average reasoning turns, indicating simpler retrieval paths. Open domain queries require more turns on average than temporal queries.
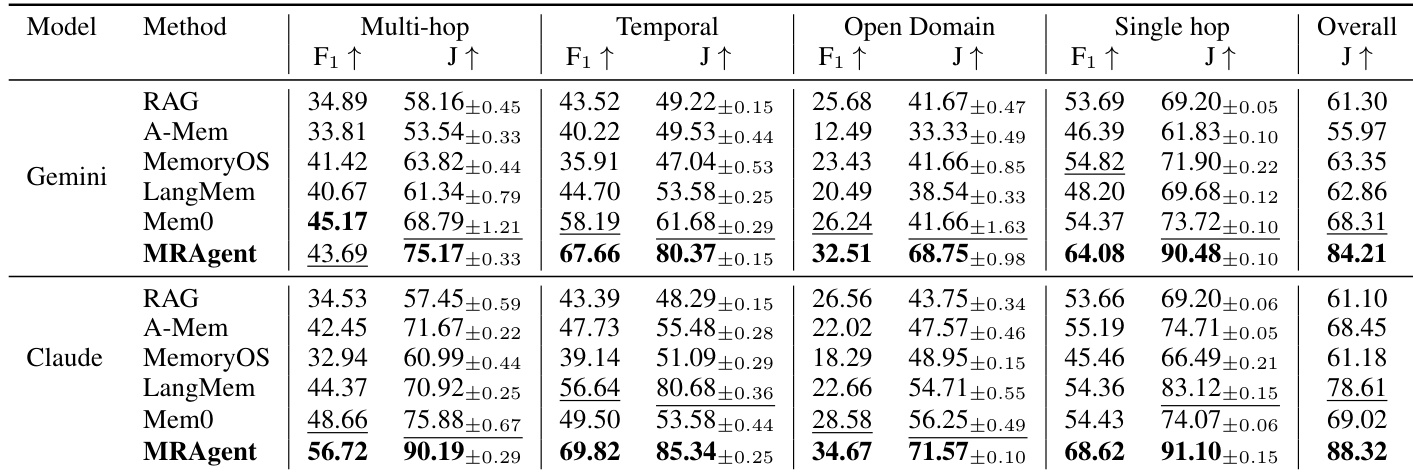
The authors evaluate MRAgent against representative memory-augmented baselines on the LoCoMo benchmark using Gemini and Claude backbones. Results demonstrate that MRAgent consistently achieves superior performance across various question types, including multi-hop, temporal, open domain, and single-hop queries, significantly outperforming existing methods in overall scores. MRAgent consistently achieves the highest performance scores across different question categories and LLM backbones compared to baseline methods. The method demonstrates significant relative improvements in overall evaluation metrics, particularly excelling in complex queries requiring multi-hop reasoning. The performance gains are attributed to the Cue-Tag-Content memory structure and multi-turn reasoning, which allow for more effective evidence retrieval and semantic guidance.
Evaluated across the LONGMEMEVAL and LoCoMo benchmarks against multiple memory-augmented baselines and LLM backbones, the experiments validate MRAgent’s retrieval efficiency, reasoning dynamics, and overall performance. Analysis of evidence coverage and reasoning depth reveals that query complexity directly dictates retrieval specialization and iterative steps, with temporal, multi-hop, and open-domain questions requiring distinct operator distributions and convergence paths. Computational assessments demonstrate that the system achieves superior information efficiency and faster execution through lightweight memory construction and selective retrieval. Ultimately, MRAgent consistently outperforms existing methods across all evaluated categories, with its advanced capabilities primarily attributed to an effective Cue-Tag-Content memory structure and robust multi-turn reasoning.