Command Palette
Search for a command to run...
A Local Perturbation Theory for Cross-Domain Interference and Recovery in Multi-Domain RL
A Local Perturbation Theory for Cross-Domain Interference and Recovery in Multi-Domain RL
Lei Yang Siyu Ding Deyi Xiong
Abstract
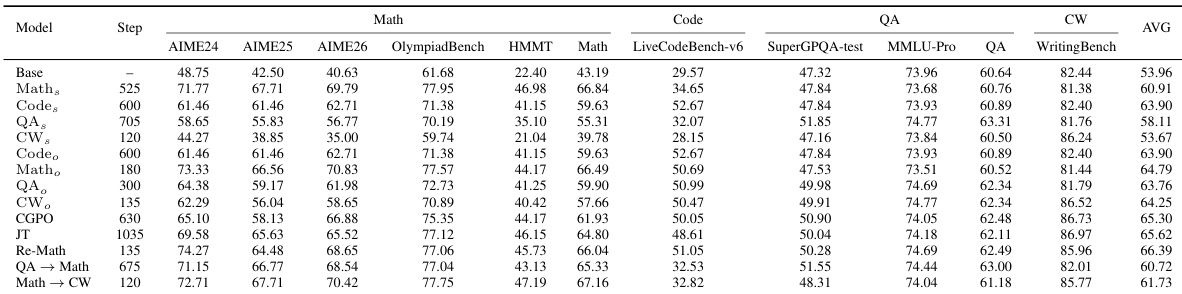
Reinforcement learning (RL) post-training improves large language models (LLMs) on individual domains such as mathematical reasoning, code generation, question answering, and creative writing (CW), but training on one domain often degrades performance on others. Existing explanations based on catastrophic forgetting or global gradient conflict are incomplete: substantial interference can occur even when full-model gradients are nearly orthogonal. We show that single-domain RL produces sparse, small-magnitude parameter edits with weak overlap among top-changed neurons, while different domains still share substantial active computation routes on which update directions determine whether they act synergistically or conflict. Guided by this observation, we prove under a local perturbation model of multi-domain RL that later-domain training harms an earlier domain mainly through a second-order damage term, which under the observed sparse route structure concentrates in a low-dimensional shared conflict subspace. Moreover, a short domain refresh contracts the harmful component on this subspace, enabling selective recovery with limited collateral damage. Consistent with the theory, a brief Re-Math refresh after Code rightarrow Math rightarrow QA rightarrow CW recovers Math from 57.66 to 66.04 while largely preserving performance on the other domains, yielding the best average score of 66.39. Beyond refresh, a training-free rollback on a sparse proxy conflict coordinate set for the Math-QA pair partially restores Math, providing direct proxy-level evidence for localized damage. These results provide a localized mechanistic account of interference and recovery in multi-domain RL.
One-sentence Summary
The authors develop a local perturbation theory for large language models that explains cross-domain interference as a second-order damage term concentrated in a low-dimensional shared conflict subspace, and introduce a brief domain refresh that selectively recovers earlier-task performance, demonstrated by a Re-Math refresh that raises mathematical reasoning scores from 57.66 to 66 after sequential training on code, math, QA, and creative writing.
Key Contributions
- Single-domain reinforcement learning generates sparse, low-magnitude parameter updates with minimal overlap among top-changed neurons, demonstrating that cross-domain interference stems from conflicting update directions along shared active computation routes.
- A local perturbation model proves that sequential domain training degrades earlier capabilities primarily through a second-order damage term that concentrates within a low-dimensional shared conflict subspace.
- A targeted Re-Math refresh selectively contracts harmful updates within this subspace, empirically recovering mathematical reasoning performance from 57.66 to 66 while preserving other domain capabilities.
Introduction
Reinforcement learning post-training is critical for equipping large language models with diverse capabilities, yet sequential multi-domain training frequently induces asymmetric degradation where optimizing one task harms performance on others. Prior explanations based on catastrophic forgetting or global gradient conflict are insufficient because significant interference can occur even when full-model gradients are nearly orthogonal, rendering localized damage invisible at the aggregate level. The authors propose a local perturbation theory that attributes cross-domain interference to a second-order damage term concentrated in a low-dimensional shared conflict subspace, demonstrating that sparse parameter edits interact destructively through overlapping active computation routes despite weak neuron-level overlap. They further show that a short domain refresh geometrically contracts these harmful components, enabling selective recovery of degraded skills with limited collateral damage, as demonstrated by substantial mathematical reasoning restoration while preserving gains in code, question answering, and creative writing.
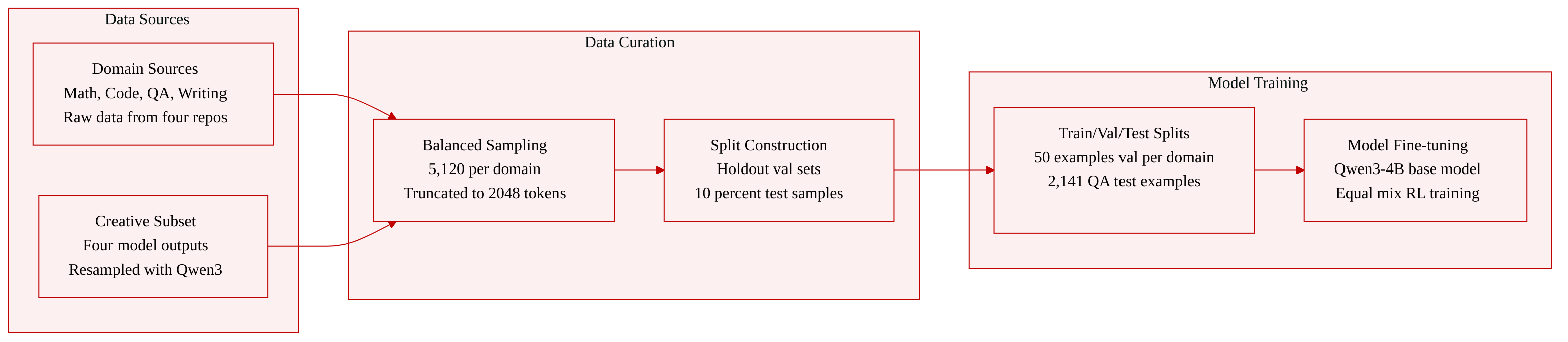
Dataset
-
Dataset Composition and Sources: The authors assemble a balanced multi-domain reinforcement learning dataset covering mathematical reasoning, code generation, question answering, and creative writing. The data is drawn from OpenR1-math, KlearReasoner-CodeSub-15K, SuperGPQA, and the crownelius/Creative-Writing series.
-
Subset Details: Each domain contains exactly 5,120 training examples. The Math subset is sampled directly from OpenR1-math, the Code subset comes from KlearReasoner-CodeSub-15K, and the QA subset is stratified by subfield and difficulty from SuperGPQA. The Creative Writing subset combines examples from four source subsets (Sonnet4.6-800x, Gemini3Pro-2700x, Reasoning-KimiK2.5-600x, and Qwen3.5Plus-2000x), with 2,560 responses resampled using Qwen3-235B-A22B-Instruct-2507 to create updated reference answers. Validation sets include 30 AIME25 problems for Math and 50 held-out examples for each remaining domain. Test sets comprise 2,141 QA examples and 1,203 MMLU-Pro examples sampled from non-training SuperGPQA and MMLU-Pro data.
-
Usage and Mixture Strategy: The authors apply an equal mixture ratio across all four domains, allocating 5,120 examples per task to maintain balanced domain exposure during multi-domain reinforcement learning. The combined dataset serves as the training corpus for fine-tuning the Qwen3-4B-Thinking-2507 base model.
-
Processing and Cropping: All training prompts are truncated to a maximum length of 2,048 tokens. The authors construct validation and evaluation splits by explicitly removing training data from the original sources, then sampling 10 percent of the remaining QA and MMLU-Pro records to ensure unbiased test sets.
Method
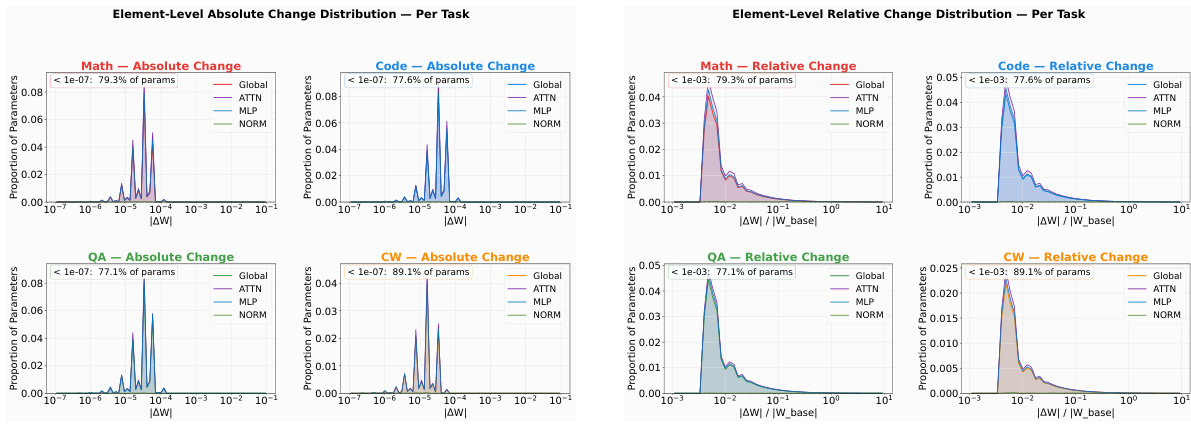
The authors investigate cross-domain interference in multi-domain reinforcement learning (RL) by analyzing the structural mechanisms that lead to performance degradation when training sequentially on different domains. The core insight is that interference arises not from global parameter conflicts, but from localized interactions within shared active computation routes. The framework begins with the observation that domain-specific RL updates are sparse, small, and exhibit weak overlap across domains, as shown in the analysis of parameter changes relative to a base model. Specifically, across single-domain experts, approximately 77% to 89% of parameters have absolute changes below 10−7 and relative changes below 10−3, indicating that domain RL acts as a mild perturbation rather than a global rewrite. This sparsity is further examined at the neuron level, where the authors define an MLP intermediate channel as a neuron and aggregate parameter changes across its gate, up, and down projections to compute an edit magnitude. For each domain, the top 10% of neurons with the largest edit magnitudes are selected, and pairwise overlap between domains is measured using the Jaccard coefficient. As shown in the figure below, these overlaps are consistently low, with average coefficients below 0.19 across all domain pairs, suggesting that different domains modify largely non-overlapping neuron subsets. 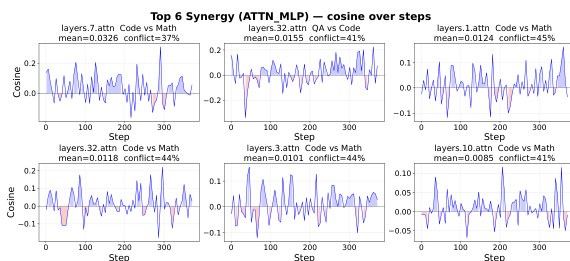
Despite this weak edit overlap, the authors demonstrate that cross-domain interference can still occur due to directional misalignment along shared active computation paths. To model this, they introduce a low-dimensional shared active conflict subspace SA,B, which captures the directions in parameter space where updates from a later domain B can affect the earlier domain A's objective. This subspace is motivated by the observation that while domain RL updates are sparse and distinct, they may still interact through shared functional units. The interference from domain B to domain A is quantified as the increase in the earlier-domain objective LA(θA∗+δB)−LA(θA∗), where θA∗ is the checkpoint after training on domain A and δB is the local update induced by domain B. Under standard local smoothness assumptions, the authors derive that the interference is governed by the second-order curvature of LA in the direction of δB. Specifically, the leading term in the interference is given by 21δB⊤HA(θA∗)δB, where HA(θA∗) is the Hessian of LA at θA∗. This result shows that even small or sparse updates can cause significant degradation if they align with high-curvature directions of the earlier domain's objective.
The analysis further localizes this second-order damage by projecting the update δB onto the shared active conflict subspace SA,B. Proposition 2 formalizes this by showing that the interference is primarily determined by the projection PSδB, with the leading term given by 21(PSδB)⊤HA(θA∗)(PSδB), up to controlled residual terms. This decomposition reveals that interference depends on the component of the later-domain update that lies within the shared conflict subspace, rather than the full update. Consequently, low parameter overlap does not imply low interference; a later-domain update can still harm an earlier domain if its projection onto SA,B is large. This also explains how global gradient near-orthogonality can coexist with selective degradation: while full-model gradients may be nearly orthogonal, localized second-order displacement along shared curvature-sensitive directions can still dominate the damage.
The authors then propose a short refresh mechanism to recover performance on the affected domain. Starting from the degraded checkpoint θ0=θA∗+δB, a short refresh on domain A performs gradient descent updates θt+1=θt−αgA(θt). Under the assumption of positive curvature of LA restricted to SA,B and weak coupling from the orthogonal complement back into this subspace, the harmful component within SA,B contracts geometrically. Theorem 1 quantifies this decay, showing that ∥PS(θt−θA∗)∥2≤(1−αμA)t∥PSδB∥2, where μA>0 is the local curvature lower bound. This geometric contraction implies that early refresh steps can rapidly remove the component responsible for earlier-domain degradation without requiring full retraining. The recovery is selective because the refresh mainly contracts the component to which domain A is sensitive, while the effect on other domains is bounded due to global near-orthogonality. The authors further extend this analysis to alternating refresh, showing that one cycle of alternating refresh approximates a descent step on a weighted multi-domain objective, which can lead to a local Pareto-stationary compromise among domains. This framework provides a local explanation for both selective interference and recovery, emphasizing that controlling localized route-level interactions is key to achieving stable and scalable multi-domain RL.
Experiment
The evaluation utilizes sequential multi-domain reinforcement learning across reasoning and creative tasks to investigate cross-domain interference during model training. Gradient and activation analyses validate that performance degradation stems not from global gradient conflicts or direct parameter overlap, but from sparse updates interacting along shared active computation routes, which creates localized and directional damage. Task-level recovery experiments and training-free weight-space interventions further confirm that this interference is highly selective and can be efficiently mitigated through brief domain refreshes or targeted rollback on conflict proxies, ultimately demonstrating that multi-domain degradation arises from second-order damage on low-dimensional shared subspaces that permit effective localized correction.
The authors examine cross-domain interference in sequential reinforcement learning, showing that degradation is not due to global gradient conflicts or widespread neuron edits but results from sparse updates interacting along shared active computation routes. Results demonstrate that short refreshes can selectively recover performance in one domain with minimal impact on others, and targeted rollback on a conflict subspace proxy significantly recovers lost performance without retraining. Cross-domain degradation arises from sparse updates on shared active computation routes rather than global gradient conflicts. Short refreshes selectively recover domain performance with limited side effects on other domains. Targeted rollback on a conflict subspace proxy recovers a substantial portion of performance loss without retraining.
The authors analyze cross-domain interference in multi-domain reinforcement learning by examining gradient interactions, active computation routes, and directional alignment of parameter updates. Results show that interference is not driven by global gradient conflict but by sparse updates affecting shared computation paths, with directional alignment determining whether the effect is synergistic or conflicting. These findings are supported by task-level recovery through short refresh and targeted rollback experiments that selectively restore performance with minimal side effects. Cross-domain interference arises from sparse updates on shared active computation routes rather than global gradient conflict. Directional alignment of updates on shared neurons determines whether interference is synergistic or conflicting, with asymmetric effects observed across domain pairs. Short refresh and targeted rollback experiments demonstrate selective recovery of performance with limited impact on other domains.
The authors examine cross-domain interference in multi-domain reinforcement learning, focusing on how sparse updates interact along shared computation routes. Results show that while global gradients are nearly orthogonal and parameter changes are sparse, domains like Math, Code, and QA share active computation paths, leading to directional interference. A short refresh or targeted rollback on a conflict subspace proxy can selectively recover performance with limited side effects. The findings support a localized conflict mechanism rather than global gradient antagonism. Cross-domain interference is driven by sparse updates along shared active computation routes rather than global gradient conflict. A short refresh or targeted rollback can selectively recover performance with minimal impact on other domains. Interference is directional and asymmetric, with later domain training affecting earlier domains more significantly.
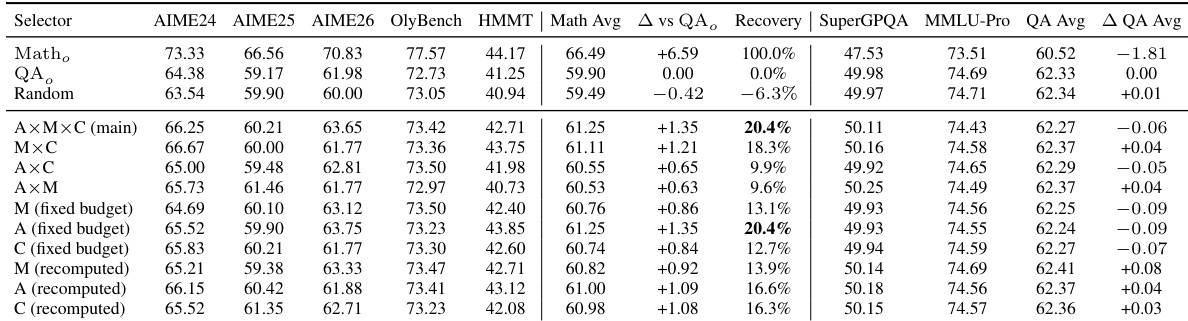
The authors analyze cross-domain interference in multi-domain reinforcement learning, showing that degradation is not due to global gradient conflict or direct neuron overlap but rather to sparse updates affecting shared active computation routes. They demonstrate that short refreshes can selectively recover performance on one domain with minimal impact on others, and a targeted rollback on a proxy for the conflict subspace recovers substantial damage without retraining. Results indicate that interference is directional and localized, with performance changes being selective and asymmetric across domains. Cross-domain degradation arises from sparse updates on shared active computation routes rather than global gradient conflict or neuron overlap. Short refreshes selectively recover performance on a target domain with limited side effects on other domains. A targeted rollback on a conflict subspace proxy recovers substantial damage without retraining, supporting the localization of interference.

The authors investigate cross-domain interference in multi-domain reinforcement learning, focusing on how sparse updates interact along shared computation routes. Results show that interference is not due to global gradient conflicts but arises from localized updates on shared active pathways, with directional alignment determining synergy or conflict. The study validates this through selective recovery via short refreshes and targeted rollback on conflict coordinates, demonstrating that damage can be mitigated without retraining. Interference arises from localized updates on shared computation routes rather than global gradient conflicts. Short refreshes selectively recover performance with minimal side effects on other domains. Targeted rollback on conflict coordinates recovers substantial damage without retraining.
The experiments evaluate cross-domain interference in sequential reinforcement learning by analyzing gradient interactions, directional alignment, and active computation pathways across multiple knowledge domains. The analysis reveals that performance degradation stems from sparse parameter updates interacting along shared computational routes rather than global gradient conflicts or widespread neuron overlap. Validation through short refresh cycles and targeted rollback procedures confirms that interference is highly localized and asymmetric, with the former selectively restoring domain performance and the latter recovering substantial damage without retraining. These findings establish that mitigating cross-domain degradation requires addressing sparse pathway interactions rather than applying broad gradient corrections.