Command Palette
Search for a command to run...
Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
Crafter: A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs
Haozhe Zhao Shuzheng Si Zhenhailong Wang Zheng Wang Liang Chen Xiaotong Li Zhixiang Liang Maosong Sun Minjia Zhang
Abstract
Scientific figures are among the most effective means of communicating complex research ideas, yet producing publication-quality illustrations remains one of the most labor-intensive parts of paper preparation. Existing automated systems each target a single figure type under text-only input, leaving the diversity of types and conditions researchers actually use unaddressed; their raster outputs further cannot be locally revised. Because scientific figures are structured compositions of discrete semantic components, the localized errors generators produce on such layouts demand not a stronger backbone but a harness. We instantiate this harness in two complementary systems: Crafter, a multi-agent harness for figure generation that generalizes across figure types and input conditions without architectural changes, and CraftEditor, which applies the same pattern to convert raster outputs into editable SVGs. Moreover, we introduce CraftBench, a benchmark spanning three figure types and four input conditions with human quality annotation. Experiments show that Crafter substantially outperforms both standalone generators and the agentic baseline on PaperBanana-Bench and CraftBench, with ablations confirming each component's independent contribution; CraftEditor faithfully converts outputs into editable SVGs that surpass all baselines. Our code and benchmark are available at https://github.com/HaozheZhao/Crafter.
One-sentence Summary
The authors propose CRAFTER, a multi-agent harness that generates publication-quality scientific figures across diverse types and input conditions, and CRAFTEDITOR, which converts raster outputs into editable SVGs, with both systems substantially outperforming existing baselines on the PaperBanana-Bench and CRAFTBENCH evaluations.
Key Contributions
- CRAFTER is a multi-agent harness for scientific figure generation that generalizes across diverse figure types and input conditions without architectural modifications. It operates through three core mechanisms: parallel diversity-driven plan exploration, a structured corrective layer for typed edits, and a verify-then-refine loop driven by a directive critic.
- CRAFTEDITOR converts raster figure outputs into editable SVGs through a three-phase pipeline comprising asset extraction, vector or raster classification, and iterative composition. A hybrid critic guides the refinement process to ensure faithful structural conversion.
- CRAFTBENCH is a 279-sample benchmark spanning three figure types and four input conditions, curated from published research and annotated for human quality. Evaluations on this benchmark and PaperBanana-Bench demonstrate that both systems substantially outperform existing baselines, while ablation studies confirm the independent contribution of each architectural component.
Introduction
Scientific figures are essential for conveying complex research findings, yet generating publication-quality illustrations remains a labor-intensive bottleneck for researchers. Existing automated systems are constrained by narrow scope, typically supporting only a single figure type and text-only inputs while producing raster outputs that prevent local revisions of labels, colors, or components. These prior approaches also fail to address the structured nature of scientific diagrams, where localized errors in semantic layouts require targeted correction rather than global regeneration. The authors leverage a multi-agent orchestration framework to overcome these limitations, introducing CRAFTER, a harness that generalizes across figure types and diverse input conditions using a shared evolving specification to enable iterative refinement. They complement this with CRAFTEDITOR for converting raster outputs into editable SVGs and release CRAFTBENCH, a benchmark spanning multiple figure types and input conditions to evaluate cross-type generalization and structural editability.
Dataset

-
Dataset Composition and Sources: The authors compile CRAFTBENCH, a 279-sample benchmark sourced from five pools including arXiv preprints across 18 disciplines, award-tier conference posters, and long-form research blogs. The arXiv collection relies on two targeted crawls: a broad-domain crawl for general method figures and a specialized crawl focused on architecture and pipeline diagrams using specific caption keywords.
-
Subset Details and Filtering Rules: The dataset spans three visual styles (academic figures, posters, and infographics) and four generation tasks. Text-to-image generation comprises the largest subset with 179 samples, followed by sketch-conditioned generation (40), mask-completion (30), and key-element composition (30). All samples originate from an initial pool of 553 candidates that pass a seven-stage quality pipeline. This pipeline applies caption keyword filtering, vision-language classification to accept only diagrams and illustrations, complexity scoring requiring at least eight distinct components and a design richness rating of 4 out of 5, and alignment verification to ensure strong consistency between captions and visual claims. Unwanted elements like watermarks, low resolution, and cropping artifacts are filtered out during two vision-language quality assurance passes, with final acceptance requiring unanimous agreement from three graduate-level annotators.
-
Data Usage and Processing: The authors use CRAFTBENCH as a standardized evaluation benchmark rather than a training set. The dataset is structured to test model performance across text-to-image generation and three reference-conditioned tasks, with the task distribution serving as the evaluation mixture. Processing focuses on maintaining high-fidelity conditioning inputs and ensuring each sample accurately represents its source domain without domain leakage or synthetic contamination.
-
Metadata Construction and Additional Processing: Annotation pairs each text-to-image sample with its original caption and source paper text. For reference-conditioned tasks, the pipeline constructs specific conditioning inputs tailored to mask completion, sketch guidance, and key element placement. Every reference input is validated through a dedicated interface where disagreements trigger iterative revisions until consensus is reached, ensuring reliable conditioning data for benchmark testing.
Method
The authors leverage a multi-agent harness framework to address the challenges of generating reliable scientific figures, which include high output variance, prompt degradation from free-text corrections, and the lack of structured feedback. This framework, instantiated as CRAFTER for figure generation and CRAFTEDITOR for raster-to-vector conversion, operates as an orchestration layer around an executor, enabling planning, verification, and revision without modifying the underlying generator. The core of this approach is a four-role loop over a shared, evolving specification S, which accumulates the current plan, revision history, and diagnostics (Figure 1). At each round t, a designer D produces an actionable plan pt, an executor E renders it into an artifact at, a verifier V emits a directive diagnostic dt containing per-dimension scores, identified defects, and suggested corrections, and a reviser R applies typed edits to St−1 (e.g., adding layout constraints or resizing elements), which modifies the specification in place rather than appending free text. The loop terminates when the verifier accepts the artifact or a round budget T is reached, returning the highest-scoring artifact a∗. This structure ensures that all task-specific behavior resides in the prompts of the roles, and the specification remains internally consistent.
The CRAFTER system, as depicted in the first diagram, implements this harness using five cooperating agents. An intent reasoner analyzes the input context and instruction to infer the figure's communicative role and required elements, seeding the initial specification S0. The plan generator D proposes K candidate visual plans, each with a distinct framing, which the image-generation backend E renders in parallel. The critic V evaluates all candidates against the specification and original input, and the specification refiner R writes typed edits back into S. A convergence judge governs the loop, deciding to accept, continue refining, or revert to the best artifact. Three key mechanisms are employed to address the identified failure modes. First, diversity-driven plan exploration treats the high variance of modern image generators as a search problem. The plan generator proposes multiple intent-conditioned candidate plans, and the convergence judge selects the best initial candidate, allowing the system to escape fundamentally unsuitable compositional choices before any rendering budget is spent.
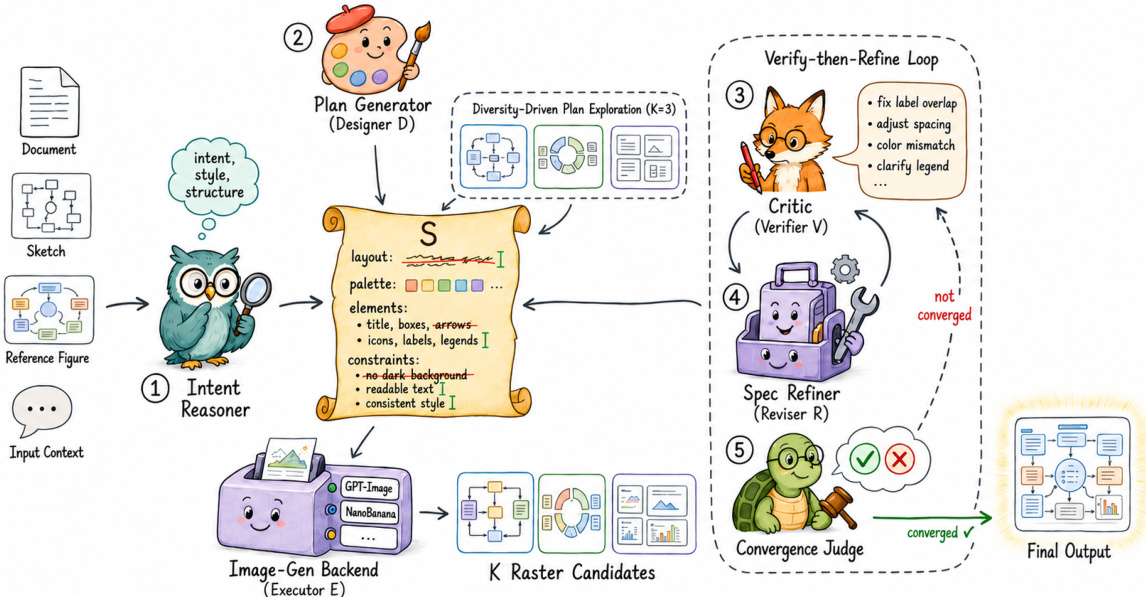
Second, the structured corrective layer replaces free-text revision with typed edits on the specification. The reviser R converts the diagnostic dt into a set of structured operations that modify S in place, ensuring that the next round's prompt is built from a coherent, consistent record rather than a growing stack of potentially conflicting amendments. Third, a verify-then-refine loop with a directive critic addresses localized errors in first-generation outputs. The critic emits a detailed diagnostic dt with per-dimension scores, identified defects, and suggestions. The refinement loop runs for up to T=3 rounds, with a best-so-far checkpoint that reverts to the highest-scoring artifact if the current round regresses, guarding against the non-monotonic behavior common in language-model-driven editing.
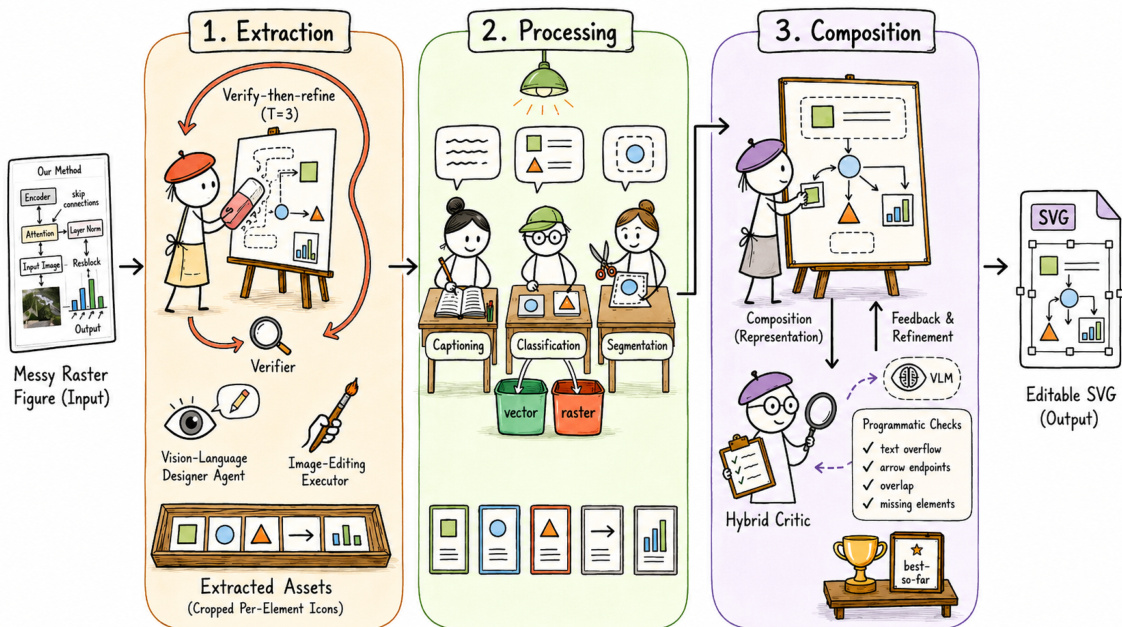
CRAFTEDITOR, illustrated in the second diagram, reuses the same harness pattern for raster-to-vector conversion. It operates in three phases: extraction, processing, and composition. The extraction phase uses an instruction-driven loop where a vision-language designer agent D authors a keep/delete plan, an image-editing executor E executes it, and a verifier V inspects the result, refining it over up to T=3 iterations. The processing phase captions, grounds, and classifies each extracted element. The composition phase assembles the assets into an SVG using a full harness loop, where a designer D generates candidate SVG skeletons, an executor E splices the assets, and a hybrid critic V—combining a vision-language model and programmatic checkers—evaluates the output, driving iterative refinement for up to T=4 rounds. The entire system relies on a shared specification S, with all agents reading and writing to it, and no direct free-text addenda between agents. The image-generation backend is called once per plan for text-to-image samples, and via a multimodal interface for reference-conditioned tasks, with new tasks requiring only minor pipeline changes. The revision process is governed by a convergence judge that applies hard rules and a vision-language acceptance call, selecting the highest-scoring artifact after a post-correction pass.
Experiment
The evaluation utilizes two benchmarks scored through a referenced VLM-as-judge protocol validated by human preference studies, enabling assessment across diverse figure types and input conditions. Main experiments demonstrate that the proposed framework consistently outperforms existing baselines, establishing broad generalization capabilities that remain robust regardless of the underlying image generator. Ablation studies confirm that each architectural component, including plan exploration and iterative refinement, independently enhances structural accuracy and content faithfulness. Finally, the raster-to-SVG editor successfully produces editable outputs by leveraging instruction-driven extraction and critic-guided composition, effectively bridging the gap between initial generation and precise post-processing.
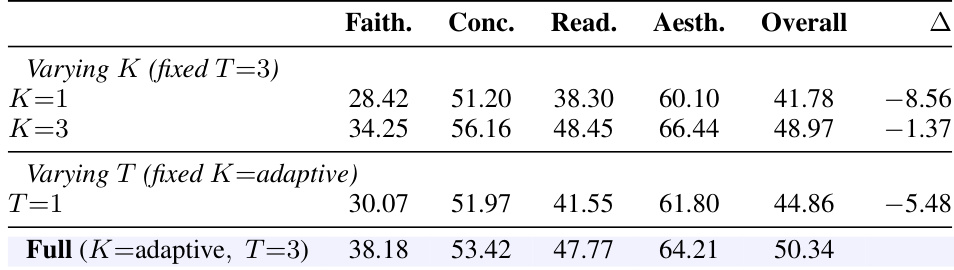
{"summary": "The the the table presents an ablation study on the effects of varying the number of candidate plans and refinement rounds in the CRAFTER framework. Results show that increasing the number of candidate plans and the number of refinement rounds improves performance across all quality dimensions, with the full configuration achieving the highest overall score. The adaptive strategy for planning and iterative refinement contribute complementary gains, enhancing both structural correctness and overall quality.", "highlights": ["Increasing the number of candidate plans improves structural and overall quality, with adaptive planning providing additional gains on complex inputs.", "Iterative refinement enhances performance across all quality dimensions, with more rounds leading to better results.", "The full configuration combining adaptive planning and iterative refinement achieves the highest scores, demonstrating complementary benefits of both mechanisms."]
The authors present a cost analysis of their system components, showing that CRAFTER and CRAFTEDITOR incur higher per-figure inference costs compared to baseline methods due to their multi-step generation and refinement processes. The cost of CRAFTER varies depending on the image-generation backbone used, with a modest increase for the more advanced version. CRAFTEDITOR adds a small additional cost per raster-to-SVG conversion, primarily from iterative refinement steps. CRAFTER and CRAFTEDITOR have higher per-figure inference costs than baseline methods due to their multi-step processes. The cost of CRAFTER increases with the complexity of the image-generation backbone used. CRAFTEDITOR adds a consistent, low additional cost per raster-to-SVG conversion.

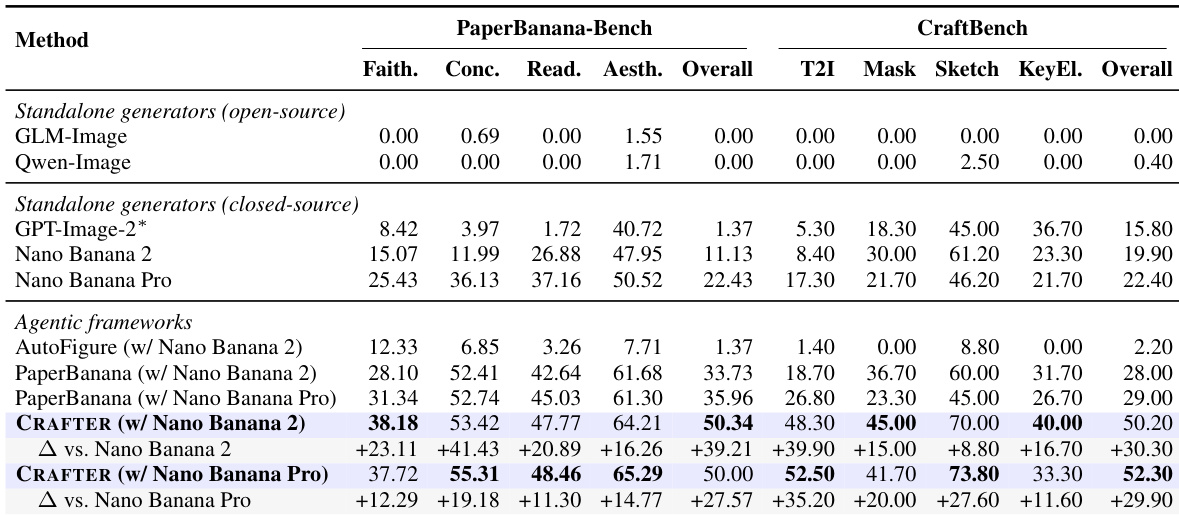
The authors evaluate a framework for scientific figure generation and editing across two benchmarks, demonstrating that their proposed system outperforms standalone generators and other agentic frameworks in both overall score and per-task performance. Results show that the framework consistently improves over its underlying generator across all quality dimensions and tasks, indicating robust generalization to diverse input conditions and figure types. The performance gains are attributed to key mechanisms such as plan exploration, iterative refinement, and corrective editing, which are shown to contribute independently to the overall improvement. CRAFTER achieves the highest overall score on both benchmarks, outperforming all baselines and its standalone generator across all tasks and quality dimensions. The framework improves uniformly over its backbone across every task and dimension, demonstrating broad generalization beyond single-condition settings. Ablation studies confirm that each mechanism in the framework contributes independently to performance, with plan exploration and iterative refinement being particularly impactful.
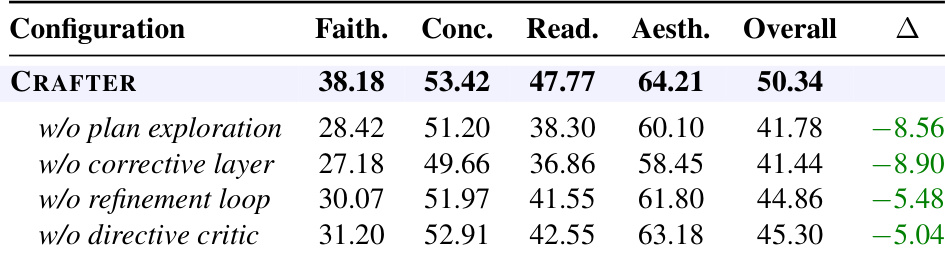
The authors conduct an ablation study to evaluate the contribution of each mechanism in the CRAFTER framework, comparing the full pipeline against versions missing one component at a time. Results show that removing any mechanism leads to a decrease in overall performance, with the most significant drops occurring when plan exploration or the corrective layer is omitted, indicating their essential roles in maintaining content faithfulness and structural accuracy. The verify-then-refine loop and directive critic also contribute substantially, highlighting the importance of iterative correction and targeted diagnostics. Removing any component from the CRAFTER pipeline reduces overall performance, with the largest drops seen when plan exploration or the corrective layer is removed. The verify-then-refine loop and directive critic contribute significantly to performance, underscoring the value of iterative correction and targeted diagnostics. The full CRAFTER framework outperforms all ablated versions across all quality dimensions, demonstrating the complementary roles of its mechanisms.
The authors evaluate a VLM-based judge for assessing scientific figure generation, comparing its performance against human judgments. Results show that the judge achieves moderate agreement with human preferences, with a majority of cases aligning with human verdicts and a moderate level of inter-annotator consistency. This supports the use of the automated judge as a reliable proxy for human evaluation in the benchmark setting. The automated judge achieves 72% agreement with human majority verdicts on a blind pairwise evaluation. The judge demonstrates moderate inter-annotator consistency with Cohen's kappa of 0.58. The results confirm the automated metric tracks human preference across diverse figure types and input conditions.

The framework was evaluated across two scientific figure generation benchmarks against standalone generators and agentic baselines, with an automated VLM-based judge validated against human preferences to ensure reliable assessment. Ablation studies validate that plan exploration, iterative refinement, and corrective editing function synergistically to enhance structural accuracy and content faithfulness, while a separate cost analysis confirms that the multi-step pipeline incurs higher inference overhead. Despite the increased computational requirements, the complete system consistently outperforms all baselines and ablated configurations across diverse inputs. Ultimately, the experiments demonstrate that integrating adaptive planning with iterative correction yields a robust and high-quality solution for scientific figure synthesis.