Command Palette
Search for a command to run...
YoCausal: How Far is Video Generation from World Model? A Causality Perspective
YoCausal: How Far is Video Generation from World Model? A Causality Perspective
You-Zhe Xie Yu-Hsuan Li Jie-Ying Lee Kaipeng Zhang Yu-Lun Liu Zhixiang Wang
Abstract
As video diffusion models (VDMs) advance toward world models, a key question arises: do they truly understand causality, or merely overfit to statistical temporal patterns? Existing benchmarks mostly rely on synthetic data, limiting real-world generalization due to the sim-to-real gap. We present YoCausal, a two-level benchmark inspired by the Violation of Expectation (VoE) paradigm from cognitive science. By temporally reversing real-world videos at zero cost as natural counterfactual samples, YoCausal establishes an arbitrarily extensible evaluation protocol. Level 1 introduces the Reverse Surprise Index (RSI), quantifying arrow-of-time perception via denoising loss. Level 2 introduces the Causality Cognition Index (CCI), which leverages a VLM to stratify datasets into causal and non-causal subsets, disentangling genuine causal reasoning from temporal bias. Evaluation of 13 state-of-the-art VDMs reveals that perceiving the arrow of time does not imply understanding causality, and a significant gap persists relative to human-level causal cognition.
One-sentence Summary
YoCausal establishes a two-level benchmark that evaluates thirteen state-of-the-art video diffusion models by treating temporally reversed real-world videos as natural counterfactuals, employing the Reverse Surprise Index to quantify arrow-of-time perception and the Causality Cognition Index, derived via vision-language model stratification, to disentangle genuine causal reasoning from temporal bias and expose a significant gap between current generative systems and human-level causal cognition.
Key Contributions
- This work introduces YoCausal, a two-level benchmark that evaluates causal cognition in video diffusion models by treating temporally reversed real-world videos as natural counterfactual samples, thereby eliminating the sim-to-real gap inherent in synthetic datasets.
- The framework defines the Reverse Surprise Index to quantify arrow-of-time perception through denoising loss and the Causality Cognition Index to stratify datasets via a vision-language model, effectively disentangling genuine causal reasoning from temporal bias.
- Evaluations across 13 state-of-the-art video diffusion models demonstrate that temporal perception does not equate to causal understanding, revealing a substantial performance gap relative to human cognition while confirming that causal capabilities scale with model architecture independently of aesthetic quality.
Introduction
As video diffusion models advance toward world modeling capabilities, understanding genuine cause-and-effect relationships rather than merely learning statistical temporal patterns has become critical for applications like robotics and autonomous simulation. Prior evaluation methods, however, rely heavily on synthetic datasets or controlled laboratory recordings, creating a sim-to-real gap that limits real-world generalization and often focuses on discriminative tasks rather than generative priors. To address this, the authors introduce YoCausal, a scalable two-level benchmark inspired by the cognitive science Violation of Expectation paradigm. They leverage temporally reversed real-world videos as natural counterfactual samples to compute a Reverse Surprise Index that measures arrow-of-time perception, and a Causality Cognition Index that uses a vision-language model to isolate true causal reasoning from simple temporal bias. Comprehensive testing reveals that while current models detect temporal directionality, they fall significantly short of human-level causal understanding.
Dataset

- Dataset Composition & Sources: The authors construct an extensible evaluation benchmark called YoCausal entirely from existing real-world video archives. This approach eliminates the need for synthetic rendering or controlled setups, allowing the benchmark to scale arbitrarily across diverse everyday scenes at zero cost.
- Subset Breakdown: The final collection contains 1,232 videos divided into four thematic domains:
- General: 500 clips sourced from Moments in Time, preserved at their original 3-second duration to capture unconstrained daily events.
- Physics: 132 clips from Physics IQ, restricted to the first 5 seconds per scene to emphasize mechanical, optical, and thermodynamic phenomena.
- Human Action: 400 clips sampled from Kinetics-400, each trimmed to 3 seconds to represent a wide range of goal-directed human activities.
- Animal Action: 200 clips from Animal Kingdom, truncated to 3 seconds to cover diverse non-human behaviors across multiple species.
- Data Usage & Evaluation Strategy: The authors deploy this dataset strictly for model evaluation rather than training. They generate natural counterfactual pairs by applying zero-cost temporal reversal to every clip. The collection is then partitioned into causal and non-causal subsets based on the presence of obvious cause-effect interactions, which enables the calculation of the Causality Cognition Index. Model performance is quantified using the Reverse Surprise Index, a metric that compares denoising losses between forward and reversed sequences to measure temporal perception.
- Preprocessing & Annotation Pipeline: To guarantee consistent evaluation across different model architectures, the authors implement a standardized preprocessing routine. This includes resolution adaptation via center cropping or automatic aspect-ratio bucket selection, frame rate resampling with FFmpeg, and temporal windowing for long videos where partial segments are padded with contextual frames from preceding clips. The authors also conduct human annotation on all 1,232 samples to establish a performance upper bound, marking approximately 20 percent as unknown due to ambiguous directional cues and assigning them a neutral win rate during final scoring.
Method
The authors leverage a two-level evaluation framework to assess causal cognition in video diffusion models (VDMs), structured around quantifying a model's perception of temporal direction and its sensitivity to causal violations. The overall architecture, as illustrated in the figure below, consists of three main stages: dataset construction, Level-1 temporal perception measurement, and Level-2 causality disentanglement.
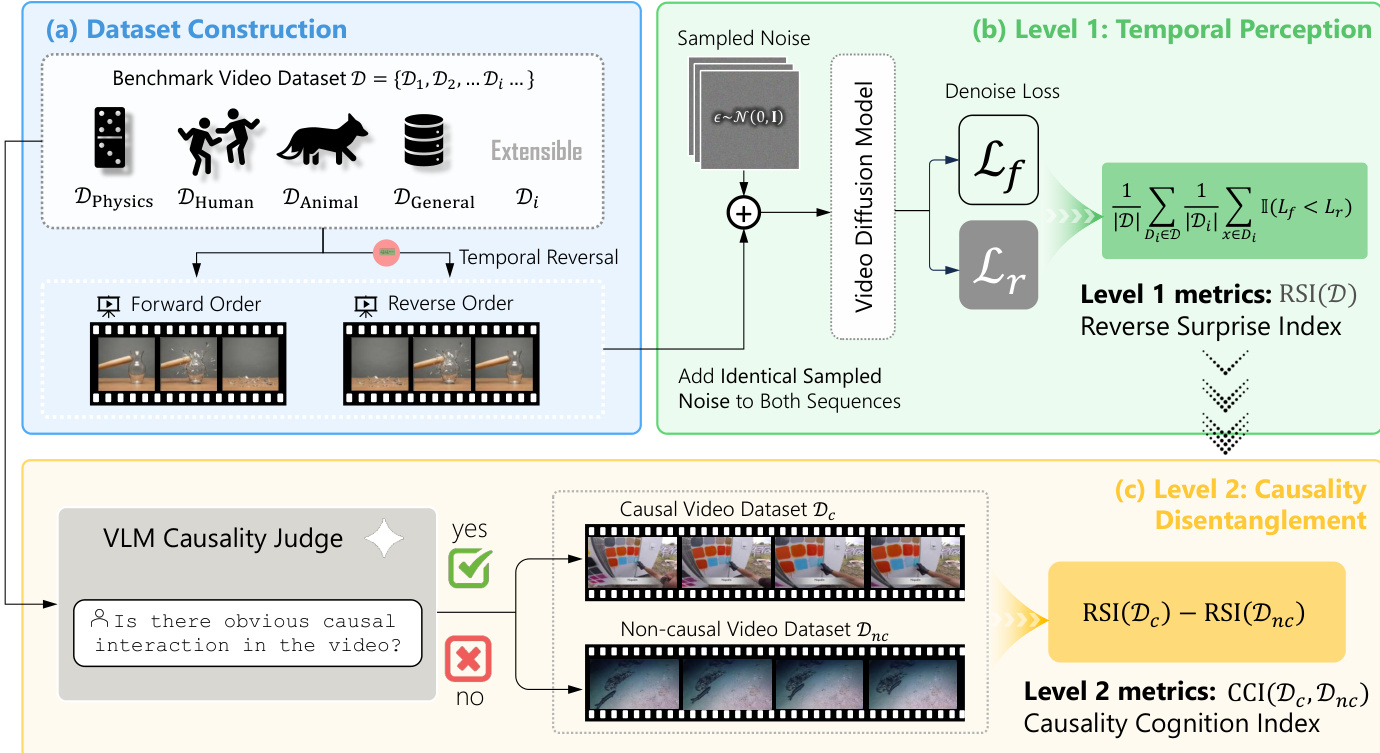
The framework begins with an extensible dataset construction process, where a benchmark dataset D is composed of multiple sub-datasets {Di}, each representing a distinct domain such as physics, human actions, or animals. For each video in the dataset, a temporally reversed version is generated, creating pairs of forward (xf) and reversed (xr) sequences. This forms the basis for the first level of evaluation.
The core of the evaluation is the use of the denoising loss as a proxy for model surprise, a concept formalized in Section 3.2. The authors adopt the Violation of Expectation (VoE) paradigm, where a model's surprise is measured by the likelihood it assigns to a given video sequence. In the context of VDMs, the denoising loss, defined as the expected squared error between the true noise and the model's prediction, serves as this proxy. A higher denoising loss corresponds to a lower assigned probability, indicating greater surprise. This loss is computed for both forward and reversed sequences.
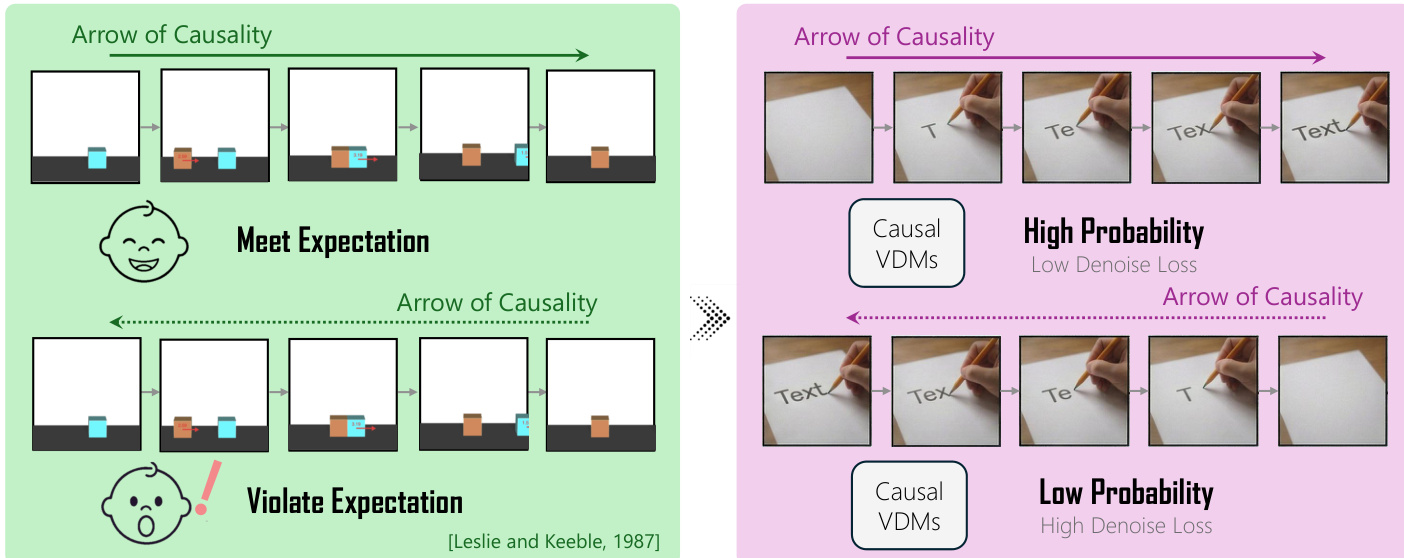
Level-1 of the framework measures the model's perception of the arrow of time using the Reverse Surprise Index (RSI). As shown in the figure, RSI is computed by comparing the denoising loss of the forward sequence (Lf) against that of the reversed sequence (Lr) for each video. The index is defined as the proportion of videos for which the model assigns a lower loss to the forward sequence, i.e., Lf<Lr. This is calculated by sampling K=10 timesteps uniformly from the diffusion process and applying identical Gaussian noise to both sequences at each timestep to ensure a fair comparison. The RSI provides a measure of the model's ability to distinguish the correct temporal order.
Level-2 of the framework aims to disentangle genuine causal understanding from mere statistical temporal patterns. The authors identify that a model's surprise at a reversed video can stem from two sources: the reversed arrow of time and the reversed causality. To isolate the causal signal, the dataset is partitioned into a causal subset Dc and a non-causal subset Dnc, based on the presence of obvious cause-and-effect interactions. This partitioning is automated using a Vision-Language Model (VLM) that classifies videos as containing causality or not, guided by a carefully designed prompt.

The Causality Cognition Index (CCI) is then defined as the difference between the RSI of the causal and non-causal subsets: CCI(D)=RSI(Dc)−RSI(Dnc). This differential measure cancels out the shared confounding factor of arrow-of-time sensitivity, isolating the model's independent sensitivity to causal violations. A positive CCI indicates that the model perceives the reversed causal video as more abnormal than the reversed non-causal video, suggesting it has captured genuine causal cognition.
The complete evaluation procedure, as detailed in Algorithm 1, orchestrates these steps. It first computes the denoising losses for all videos and their reversals (Stage 1), then calculates the RSI for the entire dataset (Stage 2). Next, it uses the VLM to stratify the dataset into causal and non-causal subsets (Stage 3). Finally, it computes the RSI for each subset and derives the CCI (Stage 4). This two-level approach provides a robust and scalable method for evaluating causal cognition in VDMs.
Experiment
The evaluation employs the YoCausal benchmark to assess causal cognition across thirteen state-of-the-art open-source video diffusion models, utilizing Reverse Sequence Identification to measure temporal arrow perception and the Causal Cognition Index to evaluate causal understanding. Ablation studies and cross-metric analyses validate that performance stems from internalized temporal and causal reasoning rather than low-level entropy dynamics or text-video misalignment, while also confirming that causal awareness is a distinct capability separate from visual quality. Qualitative findings indicate that current models possess only preliminary causal understanding that significantly lags behind human performance, yet this capability consistently improves with increased model scale and architectural evolution. Ultimately, the study establishes a robust framework for disentangling causal cognition from basic temporal perception and demonstrates that scaling laws effectively drive progress in higher-level cognitive capabilities for video generation.
The authors evaluate the causal cognition of 13 open-source text-to-video diffusion models using a two-level framework that assesses both temporal direction perception and causal understanding. Results show that higher-fidelity models tend to perform better on both metrics, with a clear gap remaining between model performance and human-level causality. The evaluation reveals that causal cognition improves with model scale and release date, and is not driven by text-video misalignment or low-level entropy cues. Higher-fidelity models achieve better performance on both temporal direction and causal understanding metrics compared to lower-fidelity models. Causal cognition improves with model scale and release date, indicating scaling laws extend to higher-level cognitive capabilities. The evaluation framework is robust to VLM choice and not confounded by text-video misalignment or low-level entropy dynamics.

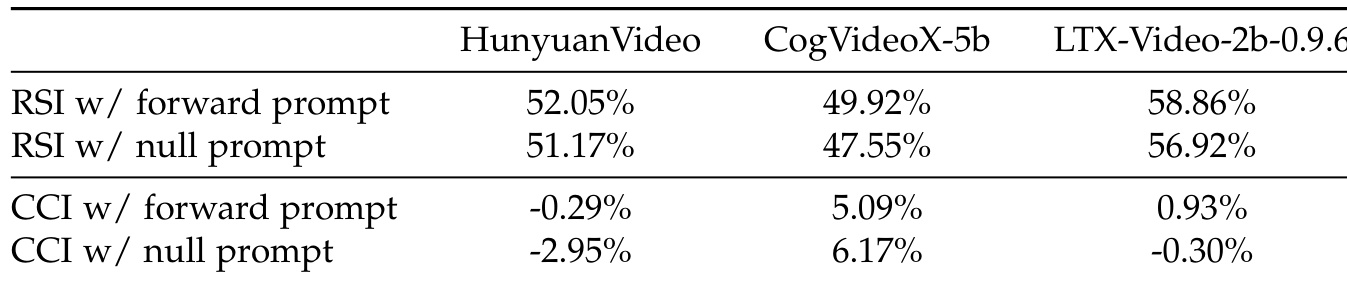
The authors evaluate the causal cognition of video diffusion models using two metrics, RSI and CCI, under both forward and null prompt conditions. Results show that models exhibit consistent performance across prompt types, with RSI values indicating temporal perception and CCI reflecting causal understanding. The stability of these metrics under different prompt settings supports the claim that the measured signals stem from internalized cognition rather than text-video misalignment. RSI and CCI metrics remain consistent under forward and null prompt conditions, indicating robustness to prompt conditioning. Models show varying levels of temporal and causal perception, with some achieving higher RSI scores and others demonstrating positive CCI values. The persistence of discriminative patterns under null prompts suggests that the measured signals originate from internalized cognition rather than text-video misalignment.
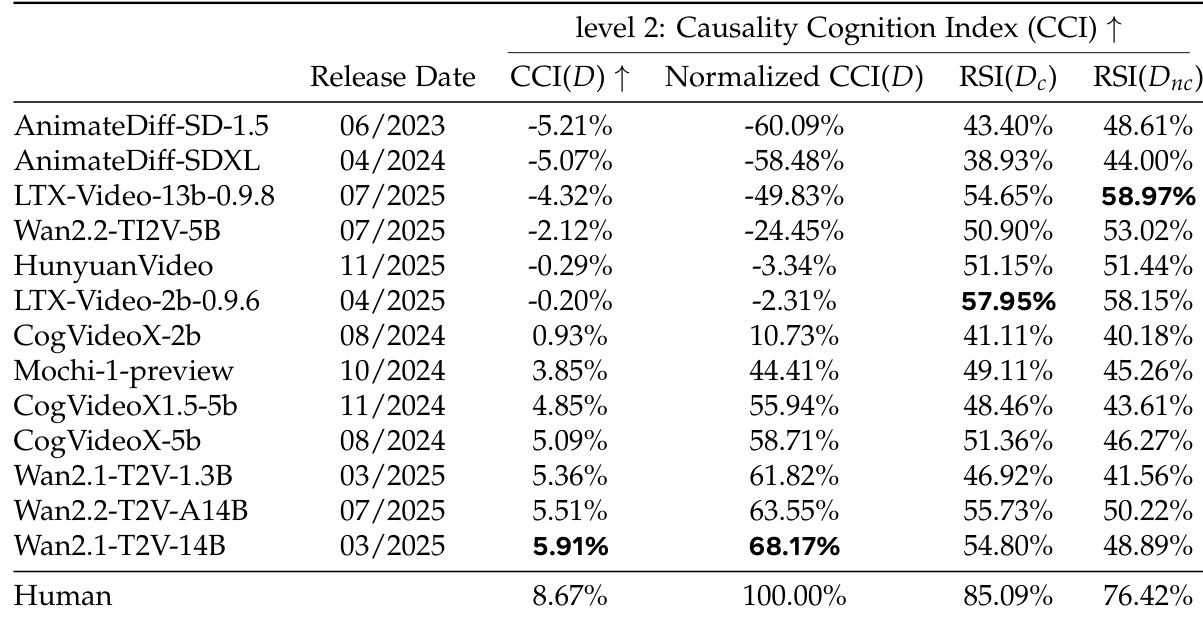
The authors analyze the causal cognition of video diffusion models using a two-level framework, evaluating both temporal direction perception and causal understanding across diverse subsets. Results show that higher-fidelity models perform better on temporal perception, while causal cognition correlates with model size and release date, indicating scaling effects. The benchmark is robust to different evaluators and not confounded by visual quality or prompt misalignment. Higher-fidelity models demonstrate stronger temporal perception compared to lower-fidelity ones. Causal cognition correlates with model size and release date, suggesting scaling laws apply to higher-level cognitive abilities. The benchmark is robust to different evaluators and not influenced by visual quality or prompt misalignment.

The authors evaluate the causal cognition of 13 open-source video diffusion models using a two-level framework that assesses both temporal direction perception and causal understanding. Results show that higher-fidelity models tend to perform better on both metrics, with human performance serving as the upper bound. The framework reveals that causal cognition is distinct from mere temporal perception and is influenced by model architecture and scale, as evidenced by correlations with release date and parameter count. Higher-fidelity models demonstrate superior performance on both temporal direction and causal cognition metrics compared to lower-fidelity models. Human performance consistently outperforms all models, serving as the benchmark for causal cognition. Causal cognition is distinct from temporal perception, as models excelling in one metric may perform poorly in the other, indicating separate cognitive capabilities.
The authors evaluate a set of open-source video diffusion models using a two-level framework to assess causal cognition, measuring both temporal direction perception and causal understanding. Results show that higher-fidelity models tend to perform better on temporal perception, while causal cognition varies across models and is influenced by architectural and scale factors. The evaluation framework is validated through cross-metric analysis, entropy-controlled subsets, and ablation studies, demonstrating robustness and alignment with human causal preferences. Higher-fidelity models generally exhibit stronger temporal perception and causal cognition compared to lower-fidelity ones. The evaluation framework distinguishes causal cognition from mere arrow-of-time perception, showing that models can score well on one metric but poorly on the other. Causal cognition correlates with model size and release date, indicating scaling laws extend to higher-level cognitive capabilities.
The study employs a two-level evaluation framework to assess temporal direction perception and causal understanding across multiple open-source video diffusion models. Qualitative analysis reveals that higher-fidelity models consistently demonstrate superior performance in both domains, while causal reasoning scales predictably with model size and release date. Importantly, the framework successfully isolates causal cognition from basic temporal perception and remains robust against prompt variations, evaluator differences, and low-level visual artifacts. Despite these advancements, human performance remains the definitive upper bound, highlighting a persistent gap in artificial causal reasoning.