Command Palette
Search for a command to run...
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Abstract
Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
One-sentence Summary
Qwen-VLA unifies embodied decision-making across tasks, environments, and robot embodiments by extending Qwen’s vision-language modeling stack to continuous action and trajectory generation via a DiT-based decoder and embodiment-aware prompt conditioning, delivering consistent multi-task performance and out-of-distribution generalization across manipulation, navigation, and trajectory benchmarks including LIBERO, R2R, RxR, and real-world ALOHA and DOMINO platforms.
Key Contributions
- Qwen-VLA is a unified embodied foundation model that extends a vision-language backbone to continuous action and trajectory generation through a DiT-based action decoder. This architecture reframes manipulation, navigation, and trajectory prediction as a shared action-and-trajectory prediction problem, enabling transferable visual grounding and spatial reasoning across diverse robot morphologies and task families.
- A staged training recipe resolves optimization asymmetry between a pretrained language backbone and a randomly initialized decoder by first teaching the decoder to decompress language instructions into action priors before visual grounding. The framework additionally employs embodiment-aware prompt conditioning, where robot-specific textual descriptions are prepended to align the shared model with platform-specific control conventions.
- Evaluations across manipulation, navigation, and trajectory-centric benchmarks demonstrate that large-scale joint pretraining yields robust multi-task performance and out-of-distribution generalization. The unified policy achieves high success rates on LIBERO, Simpler-WidowX, RoboTwin, R2R, and RxR, while maintaining competitive zero-shot performance in real-world ALOHA and DOMINO dynamic manipulation tasks.
Introduction
Embodied intelligence requires robots to perceive environments, interpret language, and execute physical tasks, yet current systems remain fragmented across narrow tasks and specific robot designs. This specialization limits cross-domain transfer and prevents scalable learning across diverse real-world scenarios. To address this, the authors introduce Qwen-VLA, a unified vision-language-action model that reformulates manipulation, navigation, and trajectory prediction as a single action-and-trajectory generation problem. They leverage a DiT-based action decoder attached to a pretrained multimodal backbone and employ embodiment-aware textual prompts to adapt the architecture to different robot platforms without structural changes. Through large-scale joint pretraining on heterogeneous datasets and a staged optimization pipeline that first establishes language-conditioned action priors before visual grounding, the model achieves robust multi-task performance and strong out-of-distribution generalization across varying environments and morphologies.
Dataset
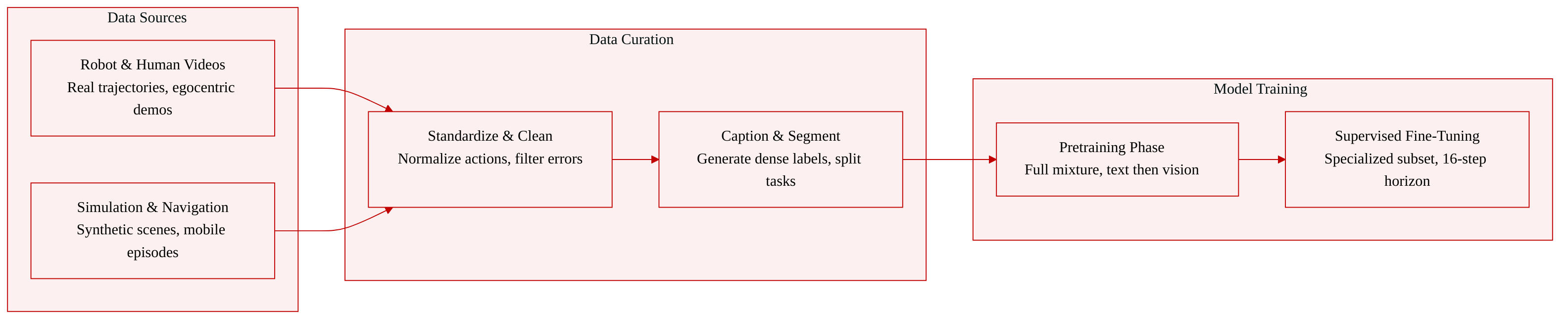
-
Dataset Composition and Sources The authors assemble a large-scale, heterogeneous pretraining corpus designed to unify vision, language, and action modeling. The mixture integrates five core data families: real and simulated robot manipulation trajectories, human egocentric demonstrations, synthetic simulation environments, mobile navigation episodes, and auxiliary vision-language datasets. Sources range from over a dozen public robotics benchmarks and large-scale human video corpora to proprietary in-house collections and internally generated simulation pipelines.
-
Key Details for Each Subset
- Robotics manipulation trajectories dominate the corpus at approximately 74.2 percent, combining public datasets like DROID and RT-1, simulated data from InternData and GR00T, proprietary teleoperation recordings exceeding 1,000 hours, and roughly 8 million synthetic simulation trajectories.
- Egocentric human demonstrations account for 6.0 percent and are drawn from Ego4D, EPIC-KITCHENS, EgoDex, EgoVerse, and Xperience to provide scalable, real-world manipulation priors.
- Synthetic simulation data is split into vision-conditioned and text-only components, generating over 359,000 VLA trajectories across randomized tabletop scenes and approximately 7.2 million text-only kinematic trajectories across six robot morphologies.
- Navigation data comprises 7.5 percent of the mixture, featuring long-horizon mobile robot episodes for instruction following, object searching, and target tracking.
- Auxiliary vision-language data makes up the remaining 8.5 percent, incorporating fine-grained action captions, autonomous driving VQA benchmarks, 2D spatial grounding samples, and general multimodal reasoning corpora.
-
Training Usage and Mixture Ratios The authors utilize the curated mixture for two distinct training phases. During pretraining, the model learns from the full heterogeneous blend with the specified sampling weights, gradually introducing visual grounding after initial language-action alignment on text-only simulation data. For multi-task supervised fine-tuning, the authors curate a specialized subset containing general vision-language samples, simulation manipulation demonstrations with a 16-step action prediction horizon, and successfully completed navigation episodes with an 8-step horizon. The fine-tuning objective balances next-token prediction with flow matching, weighting vision-language tokens at 0.1 and action tokens at 1.0 to prioritize motor policy refinement while preserving foundational visual understanding.
-
Processing, Metadata, and Cropping Strategies The authors implement extensive preprocessing to standardize heterogeneous inputs. Action dimensions are normalized per dataset using 1st and 99th percentile quantile mapping clipped to a negative one to one range, while preserving original control conventions. Embodiment-specific metadata is injected via textual prompts specifying platform type, arm configuration, and control frequency. Multi-camera observations are explicitly labeled using boundary tokens to guide selective attention. Language instructions undergo strict consistency filtering to discard misaligned annotations, and dense action captions are generated through a two-stage vision-language model pipeline followed by human verification. The authors also apply multi-stage trajectory cleaning to remove corrupted frames, static recordings, and anomalous episodes, while reconstructing missing action labels via finite differences on proprioceptive states. Full trajectories are additionally segmented into subtask sequences to provide multi-granularity supervision, and egocentric videos are densely sampled to capture fine-grained motion details.
Method
The Qwen-VLA model is designed to unify vision, language, and action generation within a single framework, enabling embodied control across diverse tasks and robot platforms. The overall architecture consists of a vision-language backbone and a flow-matching action expert. The backbone, based on Qwen3.5, processes multimodal inputs through early fusion of visual tokens with text tokens in a transformer, allowing joint reasoning over images, videos, and language. This backbone is complemented by a DiT-style flow-matching policy head that generates continuous action sequences. The action expert operates as a single-stream decoder that takes the hidden states from the backbone and a noisy action chunk as input, processing them through joint self-attention with AdaLN timestep conditioning and multi-section RoPE alignment. This decoupled design allows the action expert to specialize in fine-grained action prediction while preserving the backbone's pretrained perception and reasoning capabilities. The model is trained end-to-end using a joint objective that combines a flow-matching loss for action prediction and a standard next-token prediction loss for vision-language understanding.
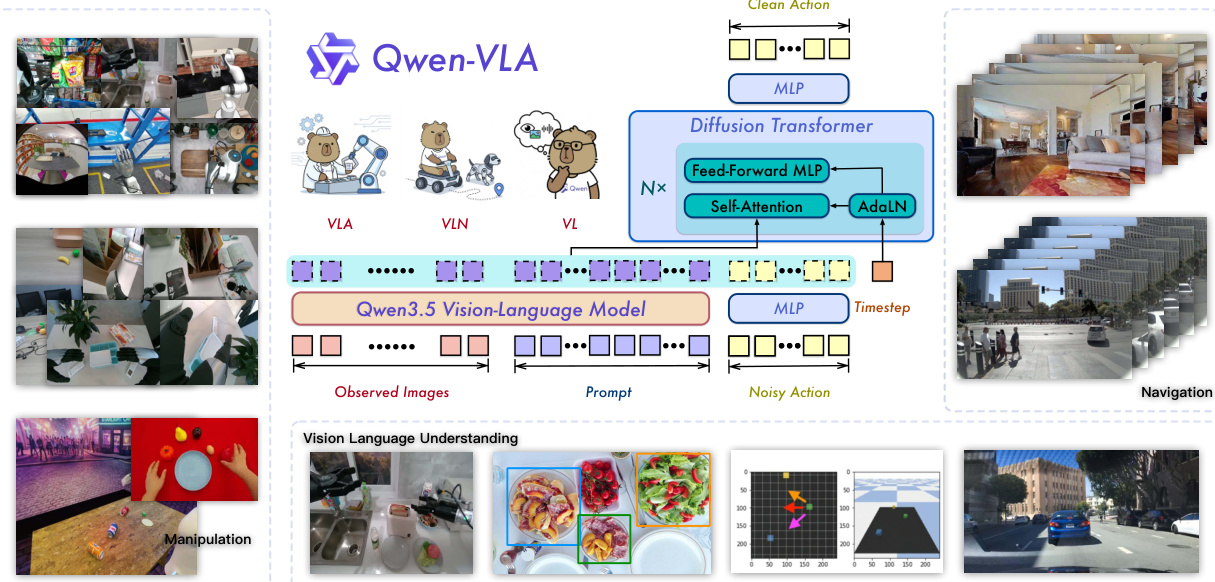
The model supports multiple embodied tasks through a unified conditional prediction framework. At each time step, the model receives a visual context ot, a language instruction x, an embodiment description e, and an optional task identifier z. It is trained to predict a target sequence yt:t+H−1 over a fixed prediction horizon H, where the sequence represents actions or trajectories in a shared action-and-trajectory space. For manipulation, this includes robot actions such as end-effector positions; for navigation, it comprises waypoints; for trajectory prediction, it denotes continuous spatial paths; and for egocentric data, it captures human motion in structured pose spaces. This unified formulation enables joint optimization across heterogeneous datasets.
To handle diverse robot embodiments, the model employs embodiment-aware prompt conditioning. Each training example is prefixed with a textual prompt that specifies the robot platform, arm configuration, and control convention, following a standardized template. This prompt is processed by the backbone and used to condition the action expert, allowing a single model to handle multiple control conventions without separate policy heads. The unified action representation further supports this by treating all control signals as sequences of real-valued vectors in a shared tensor interface. Each sample contributes a target tensor Y∈RH×K with a fixed prediction horizon H and channel dimension K, where only the relevant c channels are active and the rest are zero-padded. A per-channel binary mask M ensures that only valid entries contribute to the loss gradient, enabling a single set of DiT parameters to handle all control modes.
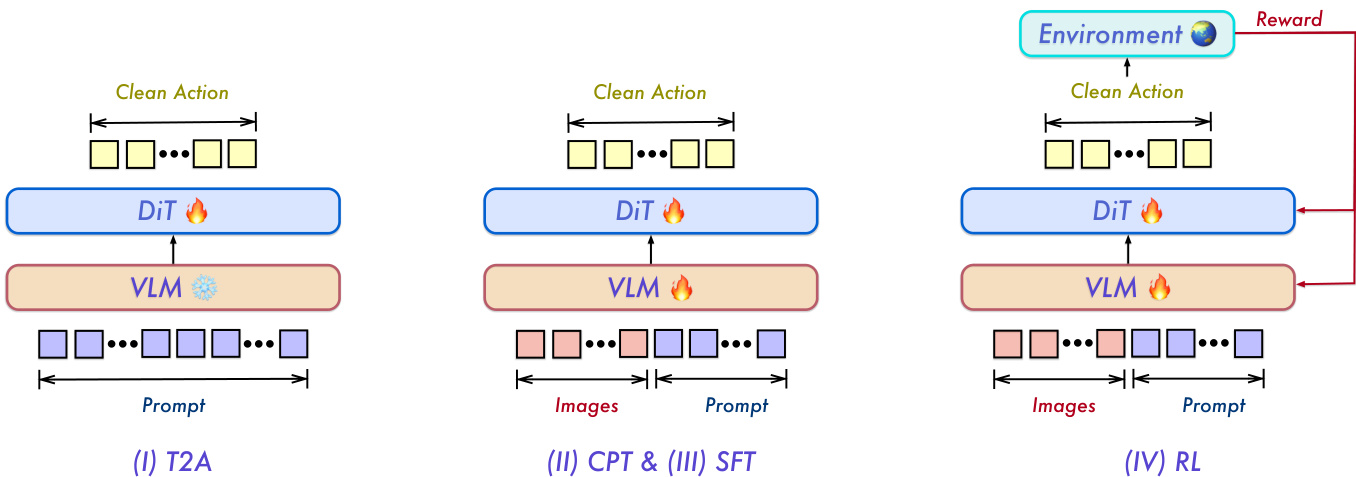
The training process follows a four-stage progressive recipe to stabilize learning and bridge the gap between discrete vision-language tokens and continuous action trajectories. Stage I, text-to-action (T2A) pretraining, freezes the backbone and trains only the DiT action decoder on language and embodiment prompts, without visual input. This forces the decoder to learn a structured prior over action spaces indexed by language and embodiment. Stage II, continued pretraining (CPT), unfreezes both modules and trains on a heterogeneous mixture of data, grounding the action prior in visual observations. Stage III, supervised fine-tuning (SFT), branches into multi-task and real-robot tracks to align the model with curated demonstrations. Finally, Stage IV, reinforcement learning (RL), optimizes the policy directly for task success using sparse binary rewards in simulation. This staged approach ensures that the decoder learns a structured action prior before being exposed to visual input, preventing instability during joint training.
Experiment
Extensive evaluations across simulation, real-world robotic platforms, and continuous navigation benchmarks validate that Qwen-VLA operates as a highly capable generalist model, matching or surpassing embodiment-specific specialists through joint multi-embodiment pretraining and instruction tuning. These experiments demonstrate that large-scale pretraining establishes robust spatial and kinematic priors, enabling strong zero-shot generalization to unseen objects, varied visual conditions, and dynamic moving targets without requiring task-specific adaptation. Complementary ablation studies confirm that strategically designed text-to-action pretraining, vision-language co-training, and reinforcement learning refinement collectively enhance policy decisiveness and closed-loop success while preserving performance on held-out tasks. Ultimately, the results establish that a unified architecture with minimal architectural overhead can achieve reliable, transferable manipulation and navigation across diverse embodied settings.
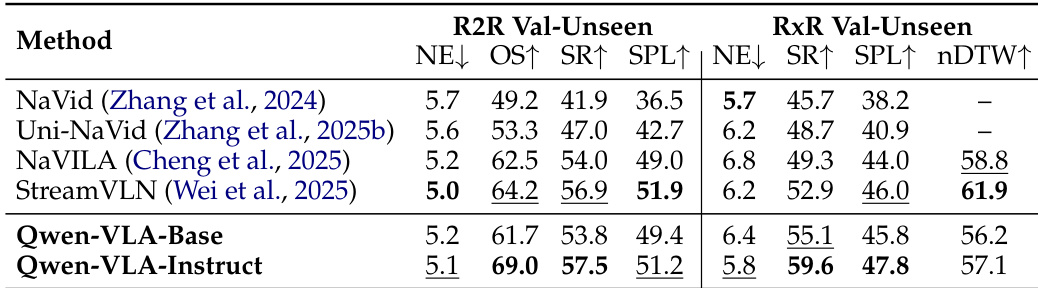
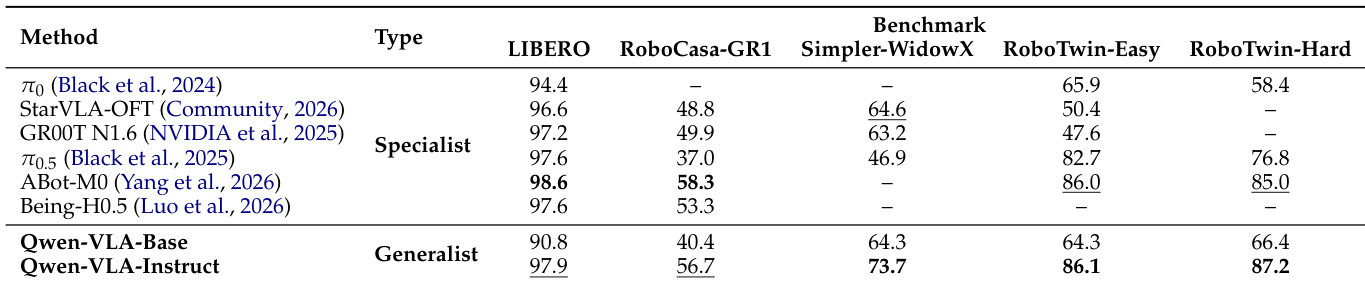
The authors evaluate the navigation capabilities of Qwen-VLA on vision-and-language navigation benchmarks, comparing the Base and Instruct variants against open-source baselines. Results show that Qwen-VLA-Instruct achieves the best performance on most metrics across both R2R and RxR benchmarks, outperforming existing methods in success rate and success-weighted path length. Qwen-VLA-Instruct achieves the highest success rate on both R2R and RxR benchmarks. Qwen-VLA-Instruct outperforms existing baselines in success-weighted path length on both R2R and RxR. The model maintains competitive performance on both R2R and RxR benchmarks with joint training on VLA and VLN data.
The authors evaluate a generalist model, Qwen-VLA, across multiple robotic manipulation benchmarks and compare its performance to specialist models trained on individual tasks. Results show that the generalist model achieves competitive or superior success rates on various benchmarks, demonstrating effective transfer learning across different robotic embodiments without per-task adaptation. Instruction tuning further improves performance, particularly on more complex tasks, and the model exhibits strong generalization to out-of-distribution scenarios in both simulation and real-world settings. A single generalist model achieves competitive or better performance than specialist models across multiple robotic manipulation benchmarks. Instruction tuning significantly improves performance, especially on complex tasks and out-of-distribution settings. The model demonstrates strong generalization to unseen visual conditions, object instances, and language instructions in real-world manipulation tasks.
The authors evaluate the impact of state conditioning on robotic manipulation performance by comparing three strategies: no state, state in VLM prompt, and state in DiT. The results show minimal performance differences across all strategies, with only marginal gains observed when incorporating proprioceptive information. The flow-matching action decoder's reliance on relative displacements and sufficient visual information from multi-view cameras likely reduces the need for explicit state inputs. Incorporating proprioceptive state yields only marginal performance gains across all conditioning strategies. The flow-matching action decoder reduces the need for explicit state conditioning by focusing on relative action displacements. Multi-view visual observations provide sufficient information about the robot's configuration, minimizing the benefit of state inputs.

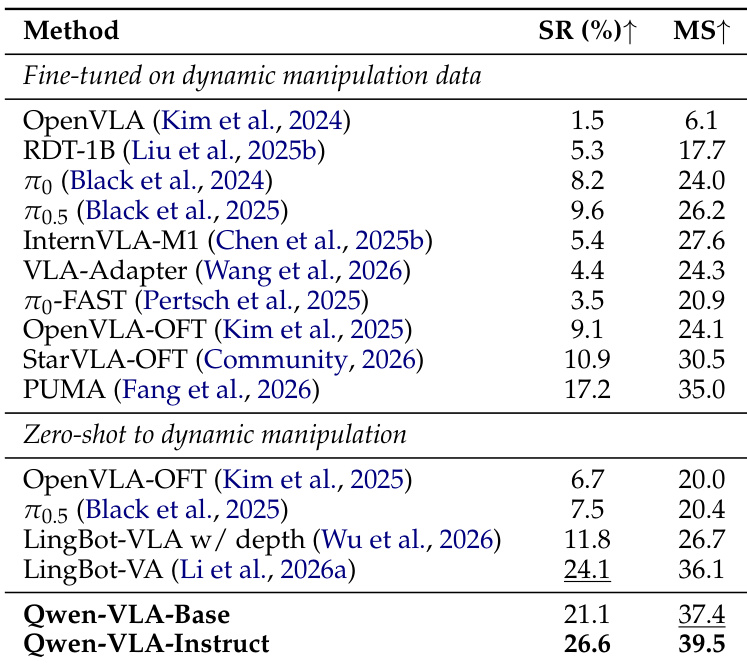
The authors evaluate the performance of Qwen-VLA in dynamic manipulation tasks, comparing it against various baselines on the DOMINO benchmark. The results show that Qwen-VLA-Instruct achieves the highest success rate and manipulation score, outperforming both zero-shot and fine-tuned methods. The model demonstrates strong zero-shot generalization to moving objects despite not being trained on dynamic manipulation data. Qwen-VLA-Instruct achieves the best performance on the DOMINO benchmark, outperforming all other methods. The model shows significant gains in success rate and manipulation score compared to zero-shot and fine-tuned baselines. Qwen-VLA-Instruct demonstrates strong zero-shot generalization to dynamic manipulation tasks without any dynamic manipulation fine-tuning.
{"summary": "The authors evaluate the performance of Qwen-VLA on real-world manipulation tasks using the ALOHA robot, focusing on in-domain and out-of-distribution generalization. The results show that the model fine-tuned from a pretrained base achieves significantly higher success rates across all evaluation categories compared to a model trained from scratch, demonstrating the effectiveness of large-scale pretraining for real-world deployment.", "highlights": ["Fine-tuning from a pretrained base model significantly improves performance on both in-domain and out-of-distribution tasks compared to training from scratch.", "The pretrained model achieves the highest success rates across all out-of-distribution generalization categories, including color, instance, position, background, and instruction variations.", "The model demonstrates strong generalization to unseen visual conditions, object instances, and instruction variations, indicating robust transfer from pretraining to real-world settings."]

The experiments evaluate Qwen-VLA across vision-and-language navigation and diverse robotic manipulation benchmarks to assess its generalization, instruction-following capabilities, and real-world applicability. Results indicate that the instruction-tuned generalist model consistently outperforms specialized baselines without requiring per-task adaptation, while large-scale pretraining proves essential for robust in-domain and out-of-distribution generalization. Additionally, the model demonstrates strong zero-shot adaptability to dynamic scenarios and complex visual variations, with explicit proprioceptive state inputs providing only marginal benefits due to the sufficiency of multi-view visual feedback. Overall, these findings highlight the model's versatile reasoning, effective transfer learning, and practical readiness for complex robotic deployment.