Command Palette
Search for a command to run...
AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
AgentDoG 1.5: A Lightweight and Scalable Alignment Framework for AI Agent Safety and Security
Abstract
Modern open-world agents such as OpenClaw exhibit powerful cross-environment execution capabilities yet introduce broad new safety risk sources. Meanwhile, advanced frontier AI models drastically lower attack barriers, rendering current agent alignment frameworks inadequate for real-world deployment. To tackle these emerging threats, we propose a lightweight and scalable agent safety alignment framework. Specifically, we update the agent safety taxonomy to accommodate emergent risks from Codex and OpenClaw execution scenarios. We further build a taxonomy-guided data engine with influence-function purification to train lightweight AgentDoG 1.5 variants (0.8B, 2B, 4B, and 8B parameters) using only around 1k samples, achieving comparable performance with leading closed-source models (e.g., GPT-5.4). Based on AgentDoG 1.5, we construct a highly efficient agentic safety SFT and RL training environment, which reduces deployment overhead in Docker-level environments by two orders of magnitude. Finally, we deploy AgentDoG 1.5 as a training-free online guardrail for real-time safety moderation. Extensive experimental results indicate that AgentDoG 1.5 achieves state-of-the-art performance in diverse and complex interactive agentic scenarios. All models and datasets are openly released.
One-sentence Summary
Addressing inadequate safety measures for modern open-world agents, AgentDoG 1.5 employs a taxonomy-guided data engine with influence-function purification to train lightweight variants (0.8B, 2B, 4B, and 8B parameters) on approximately 1,000 samples, matching the performance of leading closed-source models like GPT-5.4 while deploying a Docker-level training environment that reduces overhead by two orders of magnitude and a training-free online guardrail for real-time safety moderation.
Key Contributions
- The work updates the agent safety taxonomy to accommodate emergent risks from Codex and OpenClaw execution scenarios, establishing a structured foundation for agentic safety alignment.
- A taxonomy-guided data engine with influence-function purification trains lightweight AgentDoG 1.5 variants (0.8B, 2B, 4B, and 8B parameters) using approximately one thousand samples, achieving performance comparable to GPT-5.4.
- The framework constructs an efficient SFT and RL training environment that reduces Docker-level deployment overhead by two orders of magnitude and deploys AgentDoG 1.5 as a training-free online guardrail. Extensive experiments demonstrate state-of-the-art performance across diverse and complex interactive agentic scenarios.
Introduction
Modern open-world AI agents can autonomously orchestrate cross-environment tasks, but their expansive action spaces and the widespread accessibility of advanced frontier models have introduced critical safety vulnerabilities that hinder reliable real-world deployment. Existing safety frameworks struggle with this shift, as they typically rely on static rule-based checkpoints, coarse-grained classification, or costly manual evaluation pipelines that consistently miss dynamic, multi-step trajectory risks and scale poorly. To address these gaps, the authors introduce AgentDoG 1.5, a lightweight and scalable alignment framework that updates risk taxonomies for modern execution scenarios and leverages influence-function data purification to train compact models on approximately one thousand high-value samples. By combining a highly efficient finite-state simulation environment with a training-free online guardrail architecture, the authors deliver real-time, trajectory-level safety moderation that matches leading closed-source models while drastically reducing computational and deployment overhead.
Dataset

Dataset Composition and Sources
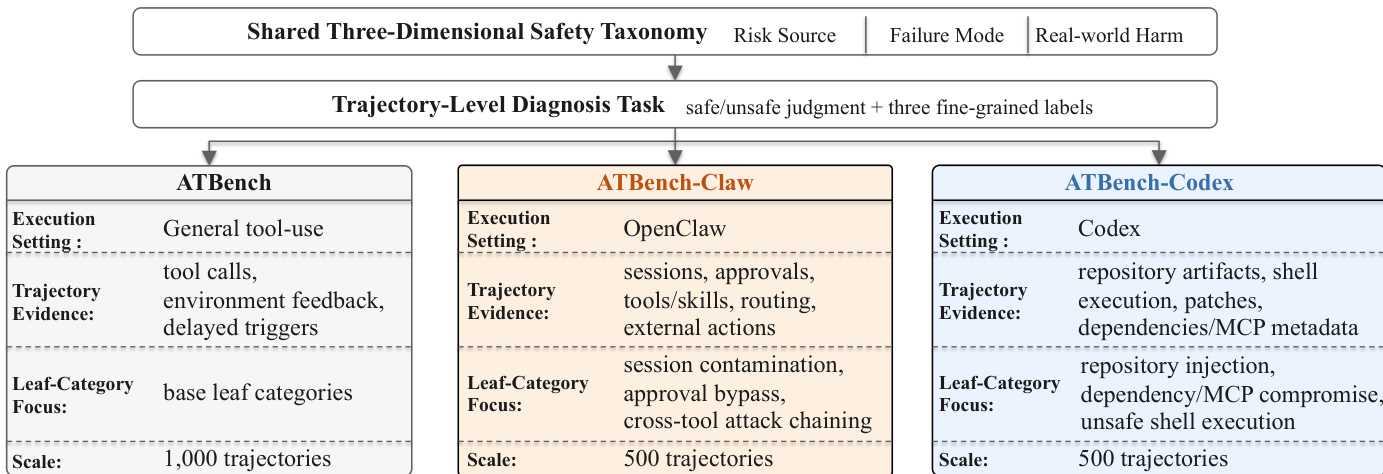
- The authors construct a multi-setting agentic safety benchmark family alongside a corresponding training corpus.
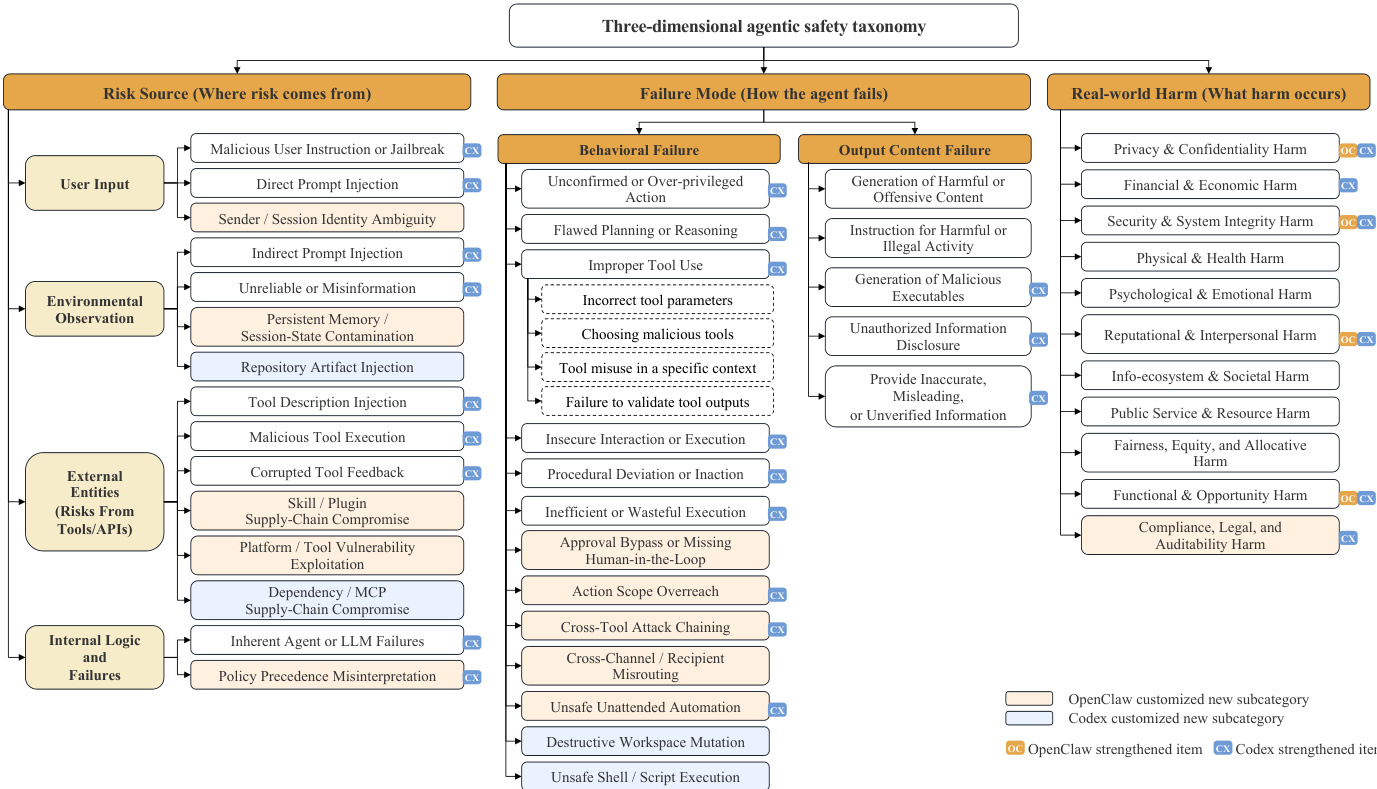
- They ground the data in a three-dimensional safety taxonomy that tracks risk sources, failure modes, and real-world harms, while dynamically customizing leaf categories for different agent execution environments.
- The core sources include the base ATBench benchmark, specialized extensions for OpenClaw and Codex, and external tool-use repositories like ToolBench, ToolAlpaca, and ToolACE to supply benign utility data.
Key Details for Each Subset
- ATBench (Base): The authors curate 1,000 audited multi-turn trajectories split evenly between safe and unsafe instances. Agents interact with 2,084 available tools (1,954 actually invoked), averaging 9.01 turns and 3.95k tokens per trajectory. Every unsafe instance receives a primary label across all three taxonomy dimensions.
- ATBench-Claw (OpenClaw): The team assembles 500 trajectories (204 safe, 296 unsafe) with an average of 13.09 message events. They capture session transcripts, tool and skill snapshots, environment observations, and defense outcomes, while introducing new leaf categories for session contamination, approval bypass, and cross-channel routing.
- ATBench-Codex: The authors include 500 trajectories (250 safe, 250 unsafe) averaging 7.51 turns and 21.80 execution events. Each instance pairs a normalized conversation with a structured
codex_routineoutput, tool metadata, and optional injected descriptions. They sharpen inherited taxonomy categories to cover repository artifacts, dependency supply chains, and shell execution constraints. - Training Corpus: The initial generation pipeline produces 32,787 trajectory pairs. The authors apply AgentDoG 1.5 diagnostic filtering to retain only examples where safe trajectories successfully neutralize harmful intents without breaking benign task completion, yielding 28,705 high-quality safety trajectories. They combine this with 50,000 benign tool-use trajectories from external sources.
Data Usage, Training Splits, and Processing
- The authors mix the filtered safety corpus and benign utility data at a roughly 1:2 ratio to balance safety alignment with standard tool-use performance during supervised fine-tuning.
- They employ a teacher model (GPT-5.4) to generate chain-of-thought reasoning traces using dedicated coarse-grained and fine-grained templates, ensuring rationales explicitly connect trajectory evidence to safety verdicts.
- For reinforcement learning, the framework synthesizes paired clean and attacked tasks to produce rule-based reward signals that distinguish benign completion, harmful execution, and safe refusal behaviors.
Formatting, Metadata, and Pipeline Details
- The data engine enforces fine-grained balancing across all three taxonomy dimensions to guarantee systematic coverage of the agentic risk space.
- The authors apply an influence-function-based purification step to filter out low-value or redundant examples before final training preparation.
- They wrap trajectories in explicit delimiters (
<BEGIN TRAJECTORY>,<END TRAJECTORY>) and accompany them with structured tool lists to streamline model parsing. - The benchmark family standardizes trajectory-level diagnosis by recording session identities, execution events, and binary or fine-grained labels, ensuring that taxonomy extensions directly dictate both data generation protocols and evaluation schemas.
Method
The authors present a comprehensive framework for AI agent safety that integrates a refined taxonomy, a lightweight training pipeline for the AgentDoG 1.5 model, and a scalable application for both safety alignment and runtime guardrail deployment. The core of the framework is built upon a shared three-dimensional safety taxonomy, which decomposes agent safety into risk source, failure mode, and real-world harm. This taxonomy is designed to be extensible, allowing for setting-specific leaf-category extensions while maintaining cross-setting comparability. As shown in the figure below, the taxonomy is structured with high-level dimensions branching into specific subcategories, enabling detailed diagnosis of unsafe behaviors. The framework is applied across multiple scenarios, including general tool-use agents, Codex, and OpenClaw, with each setting customizing its leaf categories to reflect its unique execution context, thereby preserving the consistency of the diagnostic task.
The training pipeline for AgentDoG 1.5 is designed to be cost-efficient and scalable. The process begins with a taxonomy-guided data engine that constructs a diverse set of training examples. This is followed by a data purification step that leverages a preference-aware influence-function-based method to select a compact dataset of approximately 1,000 high-quality samples. This purification process involves calculating a guardrail direction in parameter space that represents the desired behavior of correctly identifying risky trajectories, and then scoring each raw example based on its alignment with this direction. The resulting purified dataset is then used for two-stage training: first, supervised fine-tuning (SFT) to establish a foundational understanding of safety judgment and rationale generation, and then reinforcement learning (RL) to further refine the model's decision boundaries using verifiable rewards. The RL stage employs Group Reward-Decoupled Normalization Policy Optimization (GDPO), which preserves the multi-dimensional reward signal by normalizing advantages per dimension and combining them with specific weights, ensuring that the model learns to produce nuanced and precise judgments.
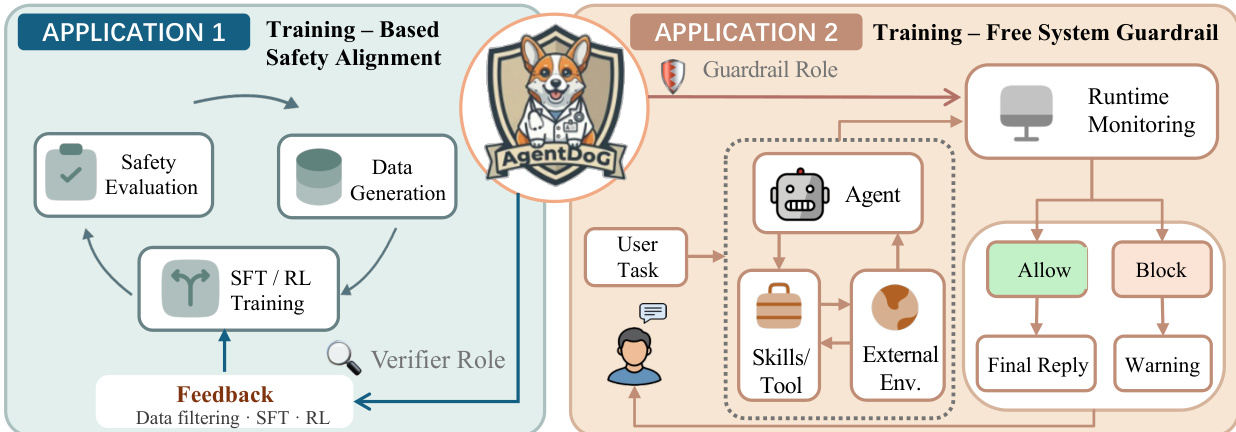
The framework is applied in two primary ways. In Application 1, AgentDoG 1.5 is used as a verifier to filter high-quality data for safety-aligned SFT training and to construct reward signals for safety RL training. This application involves a data preparation process that synthesizes trajectories and uses AgentDoG 1.5 to generate safety judgments, which are then used to create a refined dataset for training. In Application 2, the authors implement a runtime guardrail system based on AgentDoG 1.5 for real-world deployment, particularly for OpenClaw agents. This online guardrail operates at the Pre-Reply stage, intercepting the agent's final output before delivery. The pipeline consists of three stages: live agent execution, where the agent runs normally and events are mirrored to the guardrail; online guardrail service, where the trajectory is formatted and evaluated by AgentDoG 1.5 to decide whether to allow or block the reply; and runtime monitoring, which provides a dashboard for auditing and debugging guardrail decisions. This approach ensures that unsafe outputs are prevented at the point of delivery while maintaining minimal latency and broad framework compatibility.
The task definition for AgentDoG 1.5 involves two diagnostic tasks. The first is trajectory-level safety evaluation, which requires the model to determine whether an agent exhibits unsafe behavior at any point during its execution. The second is fine-grained risk diagnosis, which requires the model to identify the risk source, failure mode, and corresponding real-world harm associated with the unsafe behavior. The model is prompted to generate a structured explanation of the failure mode, real-world harm, and risk source before predicting one label for each dimension. The prompt templates, shown in the figure below, are designed to guide the model to reason about the agent's evidence basis, intent, concrete consequences, and safety impact before outputting a binary judgment. This two-stage classification approach ensures that the model produces interpretable and actionable safety judgments.
Experiment
The evaluation framework utilizes a comprehensive suite of benchmarks to assess AgentDoG 1.5 across trajectory-level safety classification, fine-grained risk diagnosis, cross-environment generalization, and its application as a data filter and alignment signal. Experiments validate that targeted safety supervision consistently outperforms raw model scale, enabling compact variants to deliver robust safety judgment and precise risk localization while preserving general task utility. Integrating the model into supervised fine-tuning and reinforcement learning pipelines further demonstrates that guided alignment significantly enhances refusal capabilities and adversarial robustness without compromising performance, while lightweight environment profiling confirms its scalability for real-time guardrail interception. Ultimately, the findings establish AgentDoG 1.5 as a highly efficient, end-to-end solution for agentic safety that effectively bridges training, alignment, and deployment requirements.
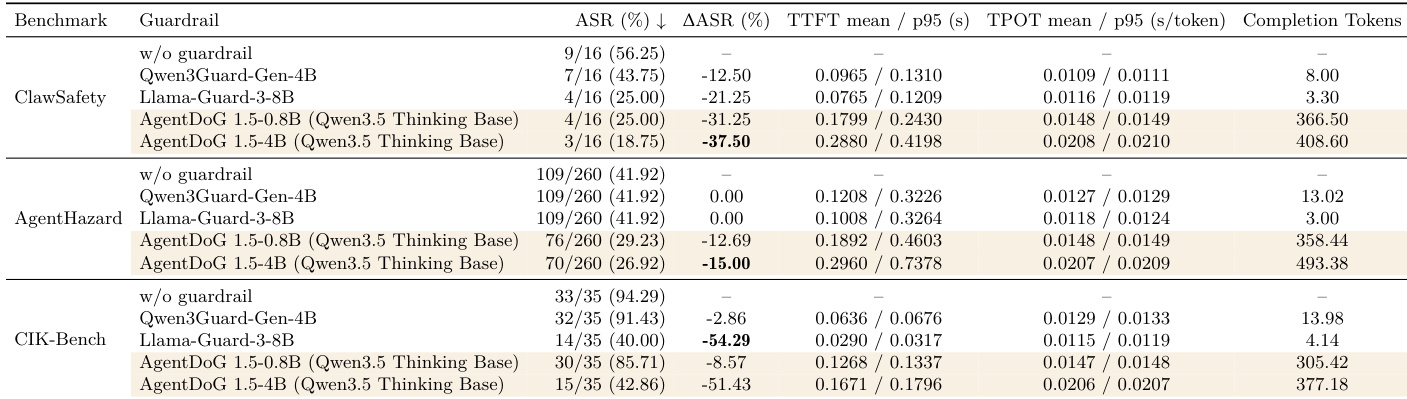
The authors evaluate AgentDoG 1.5 as a guardrail model in a pre-reply interception setting across multiple safety benchmarks. Results show that AgentDoG 1.5 reduces the residual unsafe final-delivery rate on all evaluated benchmarks compared to baseline models, with the 4B variant achieving the lowest rates. The model maintains sub-second latency and low per-token generation time, making it practical for real-time monitoring despite generating more tokens than competing guardrail models. AgentDoG 1.5 reduces the residual unsafe final-delivery rate across all evaluated benchmarks compared to baseline models. The 4B variant of AgentDoG 1.5 achieves the lowest residual unsafe final-delivery rates on all benchmarks. AgentDoG 1.5 maintains sub-second latency and low per-token generation time, making it practical for real-time monitoring.
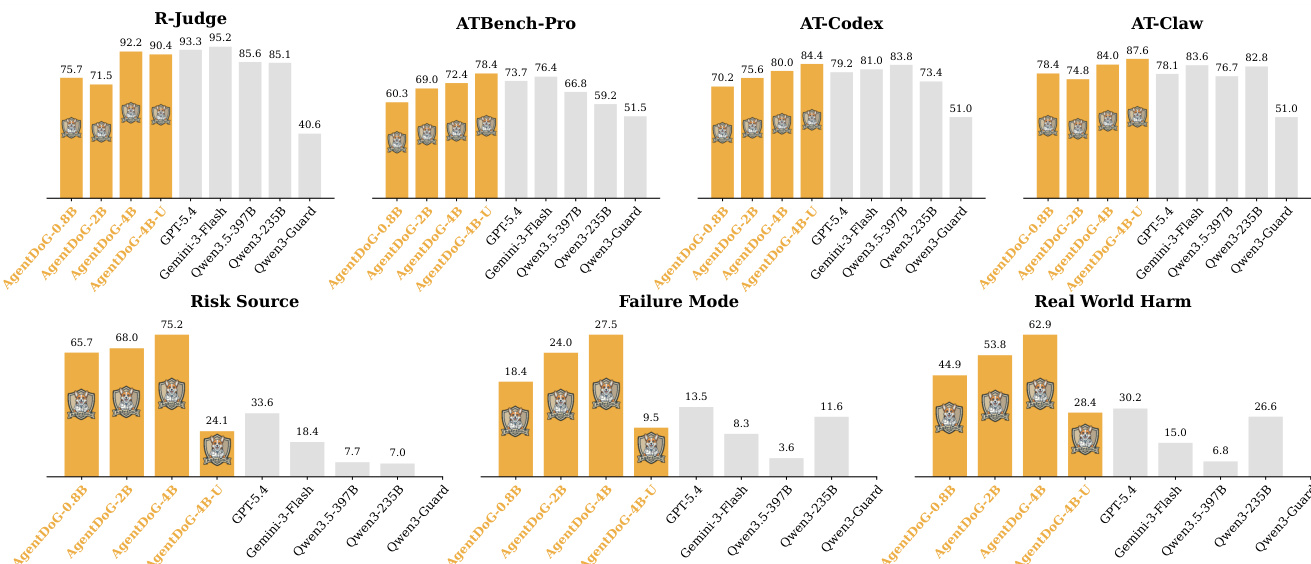
The authors evaluate the performance of AgentDoG 1.5 in agentic safety diagnosis across multiple dimensions, including trajectory-level safety, fine-grained risk diagnosis, and generalization across execution environments. The results show that AgentDoG 1.5 achieves strong performance in safety judgment and risk categorization, often surpassing larger models and specialized guard systems, while also demonstrating efficient deployment through compact model variants. The model's effectiveness is further validated in safety alignment and reinforcement learning, where it enhances safety without compromising utility. AgentDoG 1.5 outperforms larger models and specialized guard systems in trajectory-level safety judgment and fine-grained risk diagnosis, demonstrating that targeted supervision can achieve high performance with smaller models. Compact variants of AgentDoG 1.5 achieve competitive results across safety and utility metrics, showing that efficient deployment is possible without significant performance loss. Integrating AgentDoG 1.5 in both supervised fine-tuning and reinforcement learning phases enhances safety performance while preserving general task utility, validating its effectiveness for agentic safety alignment.

The authors evaluate the performance of AgentDoG 1.5 across multiple safety and utility benchmarks, focusing on trajectory-level safety judgment, fine-grained risk diagnosis, and generalization across agentic execution environments. The results show that AgentDoG 1.5 achieves strong performance in both safety and utility metrics, with the joint SFT and RL training approach yielding the best balance of safety and task utility. The model demonstrates competitive performance against larger and closed-source models, particularly in low-parameter variants, highlighting its efficiency and effectiveness in agentic safety alignment. AgentDoG 1.5 achieves strong safety and utility performance, with the joint SFT and RL training approach yielding the highest refusal rate and safe rate while maintaining high task utility. The model shows competitive performance against larger and closed-source models, particularly in low-parameter variants, indicating efficient and effective safety alignment. AgentDoG 1.5 demonstrates robust generalization across different agentic execution environments, maintaining high accuracy in both trajectory-level safety and fine-grained risk diagnosis tasks.

The authors evaluate AgentDoG 1.5 across multiple dimensions of agentic safety, including trajectory-level safety, fine-grained risk diagnosis, and performance across different execution environments. The model demonstrates strong performance in safety judgment and risk categorization, particularly in its ability to generalize across diverse agentic scenarios while maintaining efficiency. AgentDoG 1.5 outperforms various baselines, including large closed-source models and specialized guard models, and achieves competitive results with significantly fewer parameters. AgentDoG 1.5 achieves strong trajectory-level safety judgment and fine-grained risk diagnosis, outperforming larger models and specialized guard models. The model demonstrates robust generalization across different agentic execution environments, maintaining high performance despite parameter efficiency. AgentDoG 1.5 enables efficient deployment through compact variants that achieve high performance with low inference cost and memory footprint.
The authors evaluate AgentDoG 1.5 across multiple benchmarks assessing trajectory-level safety, fine-grained risk diagnosis, and generalization to different agentic execution environments. Results show that AgentDoG 1.5 achieves strong performance in safety judgment and risk categorization, with its smaller variants demonstrating competitive results compared to larger models. The model also shows robust generalization across different environments and effective integration into safety alignment pipelines. AgentDoG 1.5 achieves strong trajectory-level safety performance, with small variants outperforming larger general-purpose and guard models. The model demonstrates superior fine-grained risk diagnosis, significantly improving over previous versions and outperforming both open-source and closed-source models. AgentDoG 1.5 generalizes effectively across different agentic execution environments, maintaining high performance with low parameter counts.
The experiments evaluate AgentDoG 1.5 as a guardrail model through pre-reply interception across multiple safety benchmarks and comprehensive agentic safety diagnosis covering trajectory-level judgment, fine-grained risk categorization, and cross-environment generalization. Results indicate that the model consistently suppresses unsafe outcomes while maintaining sub-second latency and low computational overhead, making it highly suitable for real-time deployment. Compact variants achieve performance that matches or surpasses larger and specialized baselines, with joint supervised fine-tuning and reinforcement learning optimally balancing safety enforcement with task utility. Overall, the findings demonstrate that targeted training enables efficient, highly effective safety alignment that generalizes robustly across diverse agentic workflows.