Command Palette
Search for a command to run...
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
Abstract
We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields – from astronomy and bioscience to fine arts and the culinary arts – establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
One-sentence Summary
Gemini Embedding 2 is a native multimodal embedding model that embeds video, audio, image, and text modalities in a unified representation space via large-scale contrastive learning in a multi-task multi-stage training setup to achieve state-of-the-art performance on key benchmarks including 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual, and 84.0 on MTEB Code while demonstrating robust zero-shot performance across specialized domains such as astronomy, bioscience, fine arts, and the culinary arts for downstream use cases like RAG, recommendation, and search.
Key Contributions
- Gemini Embedding 2 is a native multimodal embedding model that represents video, audio, image, and text modalities within a unified representation space. The system supports arbitrary combinations of interleaved inputs across all modalities without requiring conversion to intermediate formats.
- Large-scale contrastive learning in a multi-task multi-stage training setup enables state-of-the-art performance on key embedding benchmarks. The model achieves scores of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual, and 84.0 on MTEB Code, surpassing specialized models across unimodal, cross-modal, and multimodal retrieval tasks.
- Robust zero-shot performance is demonstrated across distinct fields ranging from astronomy and bioscience to fine arts and the culinary arts. The architecture establishes efficiency by demonstrating that native audio input outperforms traditional ASR in retrieval tasks while eliminating the need for costly task-specific instructions.
Introduction
Embedding models provide essential semantic representations for applications like search and RAG, yet existing multimodal approaches typically rely on late-fusion encoders that struggle with mixed inputs. These systems lack deep cross-modal interaction and often depend on intermediate conversions like automatic speech recognition rather than processing audio natively. The authors introduce Gemini Embedding 2 to map text, image, audio, and video into a unified representation space. They leverage the underlying Gemini model and large-scale contrastive learning to achieve state-of-the-art performance across diverse benchmarks. This unified architecture supports complex downstream use cases like agentic systems without requiring task-specific instructions or modality conversion.
Method
The Multimodal Gemini Embedding 2 model is designed to generate holistic representations for inputs across different modalities, including text, images, video, and audio. These representations facilitate downstream tasks such as retrieval, clustering, and ranking. The model leverages the inherent multimodal capabilities of the Gemini foundation model to build these representations.
The architecture begins by converting raw input formats into a sequence of tokens, a process handled natively by the underlying Gemini model. This allows the system to accept raw images, video, or audio in formats supported by Gemini. Once tokenized, the input sequence T of L tokens is processed by a transformer M with bidirectional attention. This produces a sequence of token embeddings Tembed=M(T)∈RL×dM, where dM is the transformer model dimension. To condense this information into a single vector, a pooling operation is applied. The authors utilize mean pooling to average the token embeddings along the sequence axis, resulting in Pembed=P(Tembed)∈RdM. Finally, a linear projection f scales the embedding to the target dimension d, yielding the final output E=f(Pembed)∈Rd.
The diagram below illustrates how these diverse modalities are mapped into a unified vector space.
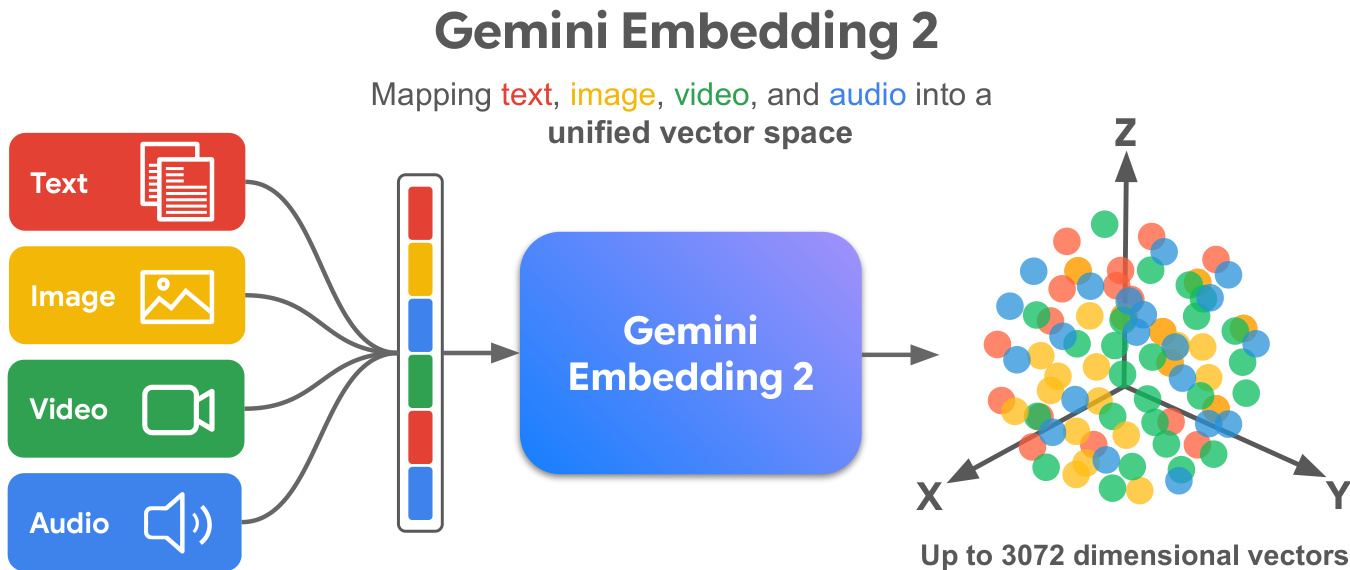
The training process employs a multi-task and multi-stage strategy to accommodate the multimodal nature of the data. The core objective function is Noise-Contrastive Estimation (NCE) loss with in-batch negatives. A training example generally includes a query qi, a positive target pi+, and optionally a hard negative target pi−. In text-only tasks, a task string t is included to describe the nature of the task, though this string is randomly dropped during training to augment robustness.
The query and passage embeddings are computed as: qi=f(mean_pool(M(t⊕qi))),pi±=f(mean_pool(M(pi±)))
For a batch of size B, the loss is calculated as: L=B1∑i=1B−logesim(qi,pi+)/τ+esim(qi,pi−)/τ+∑j=1Bmask(i,j)esim(qi,pj+)/τesim(qi,pi+)/τ
In this formulation, sim(x,y) denotes the cosine similarity between vectors. The masking term mask(i,j) is set to 0 if qi=qj or pi+=pj+, and 1 otherwise. This is particularly relevant for classification tasks with a small number of targets. Additionally, the model supports multiple embedding dimensions through Multi-Resolution Loss (MRL). This technique adapts the loss function across k overlapping sub-dimensions, enabling the model to provide up to 3072 dimensional vectors while maintaining optimization for 768 and 1536 dimensions.
The training recipe is divided into distinct stages to facilitate learning across different tasks and modalities. The first stage is Pre-Fine-Tuning (PFT), which adapts the model parameters from auto-regressive generation to encoding. This stage utilizes large batch sizes to provide stable gradients and mitigates the impact of noisy inputs. During PFT, the training data consists of image, text, and code tasks sampled at pre-specified rates.
The second stage is Fine-Tuning (FT), which incorporates a broader range of tasks including text, code, document, image, audio, and video. Many of these tasks involve query, target, and hard negative target triplets. The authors found it beneficial to tune batch sizes for each specific task to improve evaluation quality. In this stage, training batches are constructed by sampling examples from a single task, with sampling rates defined empirically to balance performance across modalities. Finally, the authors apply a Model Soup technique to systematize the combination of different checkpoints. This involves averaging parameters obtained from individual fine-tuning runs, including checkpoints from the same or different training runs, to achieve additional generalization performance.
Experiment
Gemini Embedding 2 is evaluated across comprehensive multimodal and unimodal benchmarks to validate its state-of-the-art capabilities in text, image, video, and audio understanding. The evaluation demonstrates that the model provides a robust unified latent space that outperforms competitors in retrieval tasks while delivering strong zero-shot performance without requiring manual prompt engineering. Furthermore, native audio processing significantly surpasses transcription-based baselines, and the model exhibits consistent generalization across specialized domains where other architectures often fluctuate.
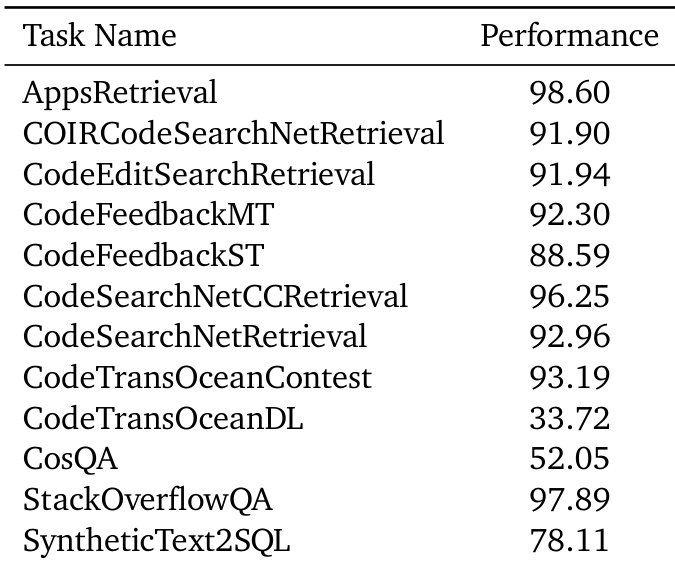
The the the table displays performance metrics for Gemini Embedding 2 on a suite of code retrieval and code-related question answering benchmarks. The model demonstrates strong capabilities across most tasks, achieving high scores in areas like AppsRetrieval and StackOverflowQA, while showing lower effectiveness on specific datasets such as CodeTransOceanDL. The accompanying text notes that the use of synthetic data contributed to significant improvements in tasks like CodeFeedbackMT and SyntheticText2SQL. The model achieves top-tier performance on AppsRetrieval and StackOverflowQA. Strong results are observed in CodeSearchNetCCRetrieval and CodeTransOceanContest. Performance is comparatively lower on CodeTransOceanDL and CosQA.
The authors evaluate the impact of input modality on retrieval performance by comparing a standard ASR pipeline against direct native audio processing. The results demonstrate that utilizing raw audio inputs significantly enhances retrieval capabilities over the transcription-based baseline across all tested splits. Native audio processing yields higher average retrieval scores than the ASR baseline. Performance improvements are consistent across both in-language and cross-language retrieval tasks. The advantage of direct audio encoding is notably larger in cross-lingual retrieval compared to in-language retrieval.

The authors investigate the impact of synthetic data on the performance of Gemini Embedding 2 using code retrieval benchmarks. The evaluation shows that the model variant trained with synthetic data significantly outperforms the base model and the version without synthetic data across all specific tasks. This approach leads to a substantial increase in the overall average score, confirming the effectiveness of using synthetic data for improving code understanding. The model variant trained with synthetic data achieves the highest scores across all evaluated benchmarks. Performance improvements are consistent across diverse code retrieval tasks including CodeFeedbackMT and SyntheticText2SQL. Utilizing synthetic data results in a significant boost to the overall average performance compared to the previous model version.

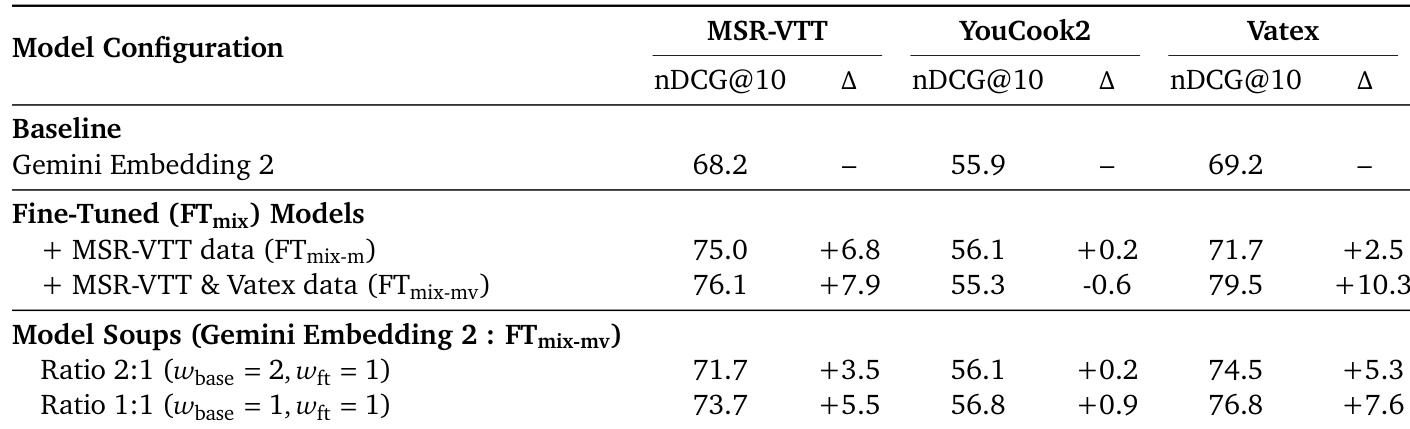
The authors evaluate the effects of fine-tuning Gemini Embedding 2 on specific video datasets and using model souping to optimize performance. Fine-tuning on targeted data significantly improves results on those specific benchmarks but can slightly degrade performance on out-of-domain tasks. Model souping effectively mitigates this trade-off, restoring performance on the out-of-domain dataset while retaining the benefits of fine-tuning. Fine-tuning on specific video datasets yields significant performance gains on in-domain benchmarks. Targeted fine-tuning leads to a slight performance decrease on out-of-domain datasets. Model souping balances the trade-off, recovering out-of-domain performance while maintaining in-domain improvements.
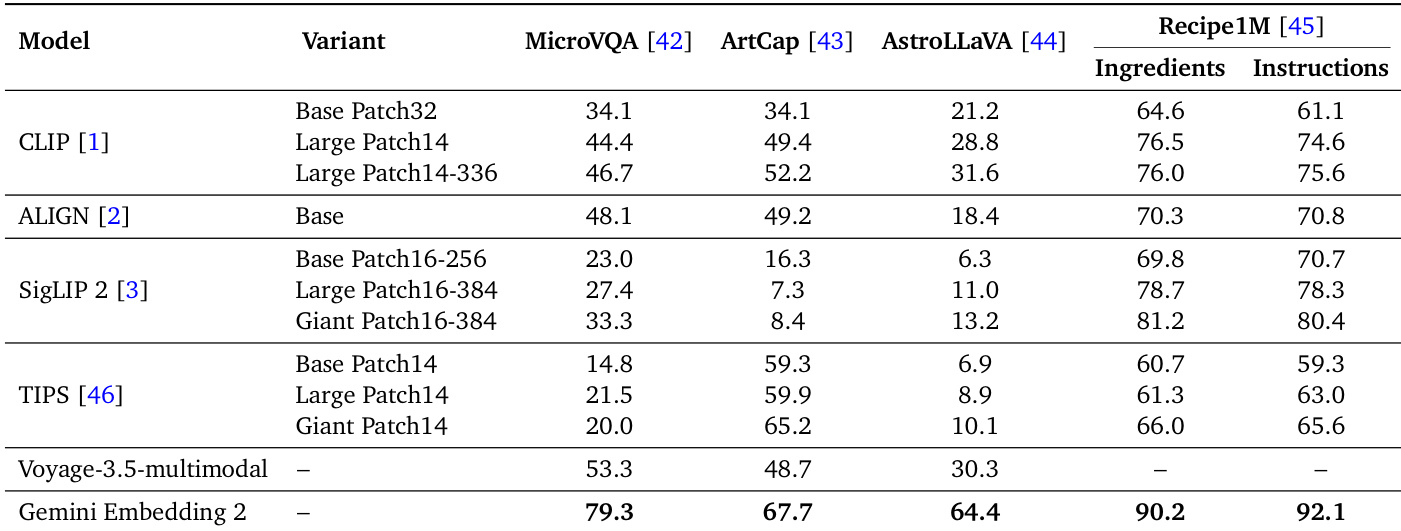
The authors evaluate Gemini Embedding 2 against various baseline models across specialized domains including microscopy, fine art, astronomy, and culinary arts. Results indicate that Gemini Embedding 2 consistently achieves top-tier performance in all categories, whereas competing models show significant variance depending on the specific domain. Gemini Embedding 2 demonstrates superior generalization, maintaining high performance across diverse fields where other models fluctuate significantly. Competing models exhibit domain-specific strengths and weaknesses, such as TIPS performing well on art but poorly on microscopy, while SigLIP 2 excels in culinary tasks but struggles with art. The model achieves the strongest retrieval capabilities in the Recipe1M dataset, significantly exceeding the performance of the next closest competitor.
This evaluation assesses Gemini Embedding 2 across code retrieval, audio modalities, and specialized domains to validate various optimization strategies. Findings indicate that native audio processing outperforms transcription baselines and synthetic data significantly boosts code understanding, while model souping effectively balances in-domain fine-tuning benefits with out-of-domain stability. Additionally, the model exhibits superior generalization across diverse fields such as microscopy and culinary arts, maintaining consistent top-tier performance where competing models fluctuate significantly.