Command Palette
Search for a command to run...
DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
DVAO: Dynamic Variance-adaptive Advantage Optimization for Multi-reward Reinforcement Learning
Guochao Jiang Jingyi Song Guofeng Quan Chuzhan Hao Guohua Liu Yuewei Zhang
Abstract
Reinforcement Learning has become a standard paradigm for aligning Large Language Models with human intent and task requirements. While Group Relative Policy Optimization offers an efficient, value-model-free alternative to Proximal Policy Optimization, adapting it to real-world multi-reward settings remains challenging. Standard scalarization practices, such as Reward Combination and Advantage Combination, suffer from significant drawbacks: Reward Combination frequently generates advantages with excessively large squared magnitudes that lead to training instability, while Advantage Combination relies on static hyperparameters and ignores cross-objective correlations. To address these limitations, we propose Dynamic Variance-adaptive Advantage Optimization (DVAO), which dynamically adjusts combination weights based on the empirical reward variance of each objective within a rollout group, effectively up-weighting objectives with a stronger learning signal while suppressing noisy ones. We mathematically prove that DVAO maintains bounded advantage magnitudes for stable training and introduces a self-adaptive cross-objective regularization mechanism. Extensive experiments on mathematical reasoning and tool-use benchmarks using Qwen3 and Qwen2.5 models demonstrate that DVAO significantly outperforms baseline methods, achieving a superior multi-objective Pareto frontier and robust training stability.
One-sentence Summary
Dynamic Variance-adaptive Advantage Optimization (DVAO) is a multi-reward reinforcement learning method that dynamically adjusts advantage combination weights using empirical reward variance to stabilize training, incorporates a self-adaptive cross-objective regularization mechanism, and guarantees bounded advantage magnitudes, thereby achieving a superior multi-objective Pareto frontier and robust stability on mathematical reasoning and tool-use benchmarks with Qwen3 and Qwen2.5 models.
Key Contributions
- The paper introduces Dynamic Variance-adaptive Advantage Optimization (DVAO), a multi-reward GRPO framework that dynamically adjusts combination weights based on the empirical reward variance within a rollout group to prioritize objectives with stronger learning signals.
- The method mathematically guarantees bounded advantage magnitudes to prevent training instability and replaces static scalarization with a self-adaptive cross-objective regularization mechanism that eliminates manual hyperparameter tuning.
- Extensive experiments on mathematical reasoning and tool-use benchmarks using Qwen3 and Qwen2.5 models demonstrate that the framework significantly outperforms standard baselines while achieving a superior multi-objective Pareto frontier and robust training stability.
Introduction
Reinforcement learning has become the standard approach for aligning large language models with practical requirements, yet real-world deployment demands simultaneous optimization of multiple competing objectives like accuracy, response length, and tool-use formatting. While Group Relative Policy Optimization provides an efficient, value-model-free training pipeline, adapting it to multi-reward settings remains challenging. Existing scalarization methods either trigger training instability through exploding advantage magnitudes or rely on fixed hyperparameters that fail to capture interactions between different objectives. The authors leverage dynamic variance-adaptive weighting to resolve these bottlenecks by scaling combination weights according to the empirical reward variance within each rollout group. This method automatically amplifies high-signal objectives while suppressing noise, mathematically guarantees bounded advantage magnitudes for stable convergence, and introduces an implicit cross-objective regularization mechanism that eliminates manual hyperparameter tuning.
Method
The authors leverage a policy optimization framework for multi-reward reinforcement learning, focusing on the limitations of existing scalarization methods—reward combination and advantage combination—and introduce a novel approach called Dynamic Variance-adaptive Advantage Optimization (DVAO). The method addresses the issues of magnitude explosion in reward combination and the isolation of objectives in advantage combination by dynamically adjusting the weighting of individual rewards based on their empirical variance within a rollout group.
In the reward combination method, the total reward is computed as a weighted sum of individual rewards, and advantages are derived by normalizing the cumulative reward within a group of rollouts. This approach leads to large advantage magnitudes, resulting in potentially unstable policy updates. In contrast, the advantage combination method computes a convex combination of normalized advantages, which reduces the magnitude of the advantage signal but fails to account for correlations between objectives and relies on fixed weights, limiting adaptability during training.
To overcome these limitations, the DVAO method introduces dynamic, variance-adaptive weights that adjust in a data-driven manner. Specifically, the weights are defined as w~k=∑lwlσliwkσki, where σki is the standard deviation of the k-th reward across the group of rollouts for a given query xi. This formulation up-weights objectives with higher variance, which often correspond to more informative or challenging tasks, while down-weighting those with low variance, which may represent stable or noise-prone signals. The resulting DVAO advantage is then computed as:
ADVAO(i,j)=k∑w~kAk(i,j)=∑lwlσli∑kwkσkiAk(i,j).
As shown in the figure below, the DVAO framework integrates this adaptive weighting into the policy gradient computation, replacing the fixed convex combination used in standard advantage combination with a variance-aware mechanism that dynamically modulates the contribution of each objective.
The key theoretical advantage of DVAO lies in its ability to balance the magnitude of the advantage signal while preserving cross-objective interactions. Proposition 2 demonstrates that the DVAO advantage magnitude is strictly bounded by the reward combination advantage, ensuring that policy updates remain stable and do not suffer from excessive gradients. This is achieved by leveraging the variance of each reward to scale its influence, effectively regularizing the learning process.
Furthermore, the sensitivity of the combined advantage to individual rewards reveals a fundamental distinction between DVAO and the standard advantage combination method. The partial derivative of the combined advantage with respect to the k-th raw reward for the advantage combination method depends solely on the isolated advantage Ak(i,j), treating each objective independently. In contrast, the DVAO sensitivity includes a cross-term ADVAO(i,j)Ak(i,j), which couples the gradient contribution of the k-th objective to the overall multi-objective performance. This dependency enables DVAO to adaptively modulate learning signals based on the model’s global performance, promoting synergistic alignment across objectives and preventing over-optimization of any single reward. The dynamic interplay between individual and collective performance ensures that the policy learns to balance multiple objectives in a context-aware manner.
Experiment
The evaluation assesses DVAO on mathematical reasoning and tool-use benchmarks, validating its capacity to simultaneously optimize accuracy alongside secondary constraints like output length and format compliance across multiple model scales. Main results demonstrate that DVAO consistently outperforms fixed-weight baselines by maintaining high performance on both objectives, whereas competing methods inevitably sacrifice one dimension for the other. Training dynamics and Pareto frontier analyses further validate that DVAO’s adaptive variance normalization stabilizes reward signals, prevents gradient dominance by easier tasks, and enables robust navigation of the accuracy-compliance trade-off without manual hyperparameter tuning. Ultimately, the algorithm establishes a reliable framework for multi-reward optimization by delivering balanced, stable convergence across diverse reasoning and execution tasks.
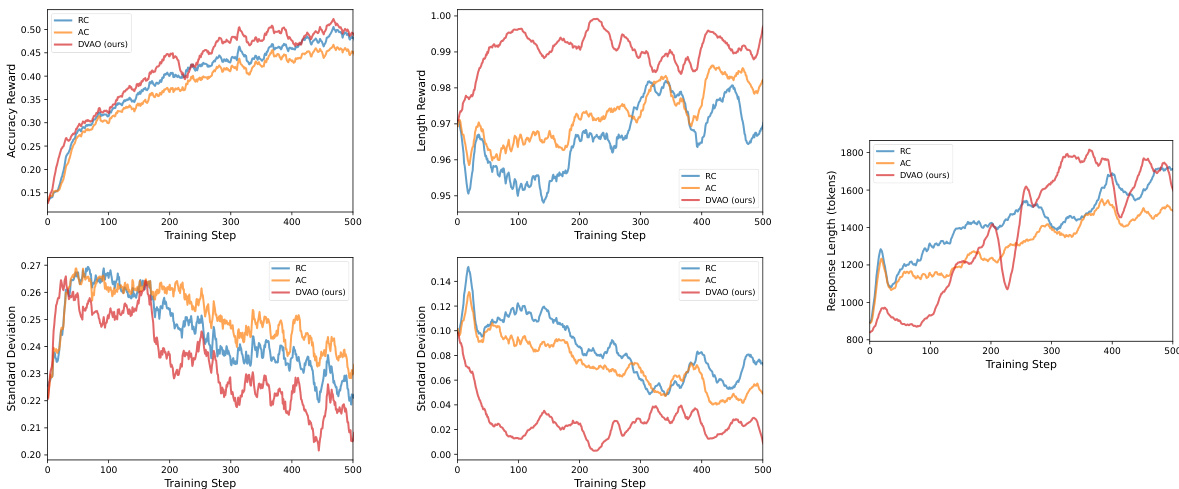
{"summary": "The authors evaluate their proposed DVAO method on tool-use tasks using the BFCL-v4 benchmark, comparing it against several baselines across different model scales. Results show that DVAO achieves the highest performance in both accuracy and format compliance simultaneously, outperforming all other methods which typically sacrifice one objective for the other. The training dynamics reveal that DVAO stabilizes rewards and response lengths more effectively, leading to better convergence and consistent improvement.", "highlights": ["DVAO achieves the highest accuracy and format compliance across all tasks and model scales, outperforming all baselines that trade one objective for the other.", "DVAO demonstrates superior training stability with lower variance in accuracy and length rewards compared to baselines, leading to more consistent optimization.", "DVAO's adaptive mechanism enables it to dominate the Pareto frontier, maintaining high compliance across different accuracy-weight settings while other methods show instability or saturation."]
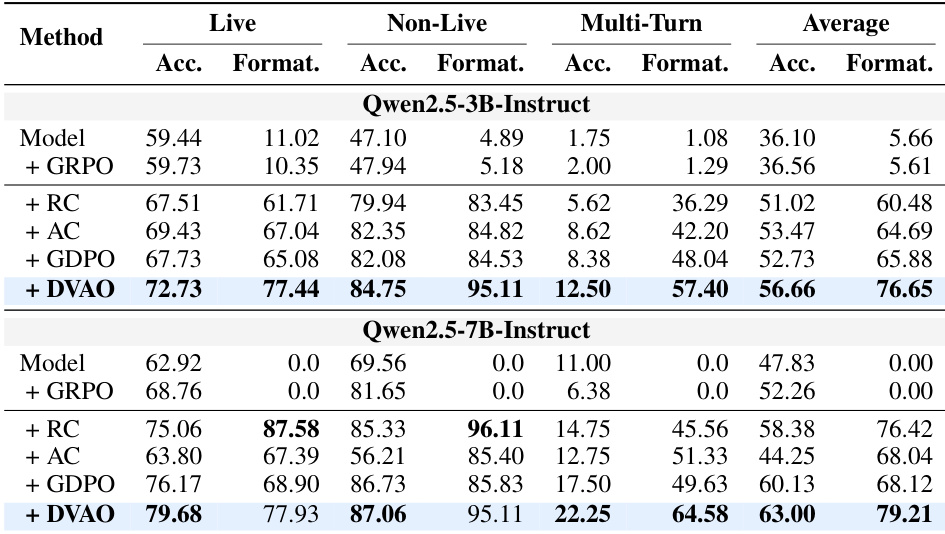
The authors evaluate their DVAO algorithm on mathematical reasoning and tool-use tasks, comparing it against several baselines including GRPO, RC, AC, and GDPO. Results show that DVAO achieves the highest average performance across both tasks and model scales, maintaining high accuracy while also ensuring strong compliance with length and format constraints. Other methods typically sacrifice one objective for the other, whereas DVAO consistently leads in both dimensions simultaneously. DVAO achieves the highest accuracy and compliance scores across both mathematical reasoning and tool-use tasks simultaneously. DVAO maintains superior performance across model scales, while baselines trade off between accuracy and compliance. DVAO exhibits more stable training dynamics, with lower variance in reward signals and effective convergence to target length and format requirements.
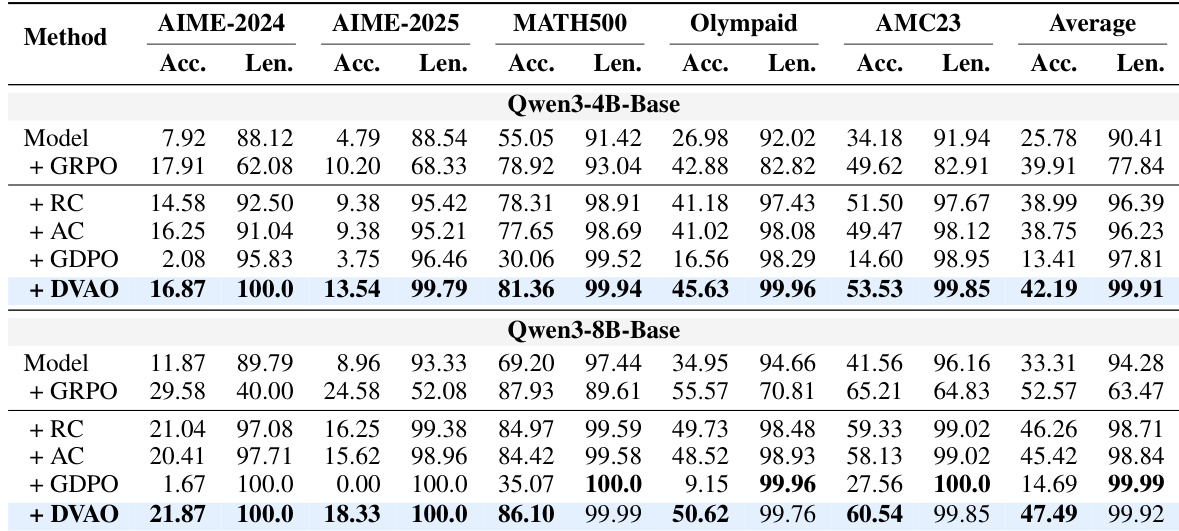
The authors evaluate their DVAO method on mathematical reasoning and tool-use tasks across multiple model scales, comparing it against several baselines to validate its capacity for simultaneous accuracy and compliance optimization. The results demonstrate that DVAO successfully eliminates the typical trade-off between performance and constraint adherence, consistently delivering strong outcomes where competing methods sacrifice one objective for the other. Qualitatively, the approach exhibits superior training stability and reliable convergence, maintaining robust performance across varying configurations and confirming its status as a balanced optimization framework.