Command Palette
Search for a command to run...
Comparative Analysis of Military Detection Using Drone Imagery Across Multiple Visual Spectrums
Comparative Analysis of Military Detection Using Drone Imagery Across Multiple Visual Spectrums
Sourov Roy Shuvo Prajwal Panth Rajesh Chowdhury Sorup Chakraborty Sudip Chakrabarty Prasant Kumar Pattnaik
Abstract
In modern warfare, drones are becoming an essential part of intelligence gathering and carrying out precise attacks in different kinds of hostile environments. Their ability to operate in real-time and hostile environments from a safe distance makes them invaluable for surveillance and military operations. The KIIT-MiTA dataset is comprised of images of different military scenarios taken from drones, and these provide a foundation for detecting military objects, but it does not take into account the various types of real-world scenarios. With that in mind, to evaluate how the models are performing under varying conditions, four different types of datasets are created: Gray Scale, Thermal Vision, Night Vision, and Obscura Vision. These simulate the real-world environments such as low visibility, heat-based imagery, and nighttime conditions. The YOLOv11-small model is trained and used to detect objects across diverse settings. This research boosts the performance and reliability of drone-based operations by contributing to the development of advanced detection systems in both defensive and offensive missions.
One-sentence Summary
This study conducts a comparative analysis of military object detection using drone imagery by introducing four datasets, Gray Scale, Thermal Vision, Night Vision, and ObscuraVision, to train and evaluate the YOLOv11-small model across varied environmental conditions and improve detection reliability.
Key Contributions
- This paper introduces four specialized dataset variants derived from the KIIT-MiTA dataset: Gray Scale, Thermal Vision, Night Vision, and ObscuraVision. These variants simulate challenging military environments characterized by low visibility, heat-based imagery, and nighttime conditions.
- A systematic evaluation framework is developed to test the YOLOv11-small object detection architecture across these diverse visual conditions. This assessment quantifies model robustness against environmental degradation factors typical of dynamic defense scenarios.
- Experimental results demonstrate consistent detection accuracy and operational reliability across all simulated imaging modalities. These findings establish a performance baseline for enhancing drone-based surveillance systems in hostile environments.
Introduction
Drone-based object detection is critical for modern military surveillance and defense, yet maintaining high accuracy across harsh environments like low light, thermal gradients, and atmospheric obscurants remains a persistent challenge. Prior research has largely prioritized controlled settings or conventional detectors, frequently struggling with sensor noise, coarse resolution, and a notable absence of publicly labeled datasets for specialized imaging modalities. To address these limitations, the authors leverage the YOLOv11-small architecture and systematically evaluate its performance across four transformed versions of the KIIT-MITA dataset. By simulating grayscale, thermal, night vision, and obscura conditions, they provide actionable insights into model robustness, ultimately advancing the reliability of autonomous drone systems in dynamic operational theaters.
Dataset

Dataset Composition and Sources
- The authors utilize the KIIT-MiTA dataset, which consists of 1,700 high-resolution images captured by military drones across various operational scenarios.
- Each image is paired with over 4,100 manually annotated labels stored in YOLO format, with dedicated text files containing normalized bounding box coordinates and class identifiers.
- The annotations track seven distinct military object classes: Artillery, Missile, Radar, Multiple Rocket Launcher, Soldier, Tank, and Vehicle.
Subset Details and Transformations
- To evaluate detection performance under varying environmental conditions, the authors generate four specialized subsets from the original imagery.
- ThermalVision applies OpenCV grayscale conversion followed by a COLORMAP INFERNO mapping and full-range normalization to simulate infrared sensor output.
- NightVision converts images to grayscale, enhances brightness and contrast using OpenCV's convertScaleAbs function, and overlays a weighted green channel to replicate monochromatic night optics.
- Grayscale removes the color channel entirely to emphasize edges, contours, and object geometry for scenarios where color data is unreliable.
- ObscuraVision introduces controlled environmental interference to mimic real-world visibility challenges, applying a blur limit of 3, a fog coefficient of approximately 0.1, and contrast/brightness adjustments capped at 0.1 to represent roughly 25% visual degradation.
Data Usage and Model Integration
- The authors partition the original dataset into training, validation, and testing subsets to support model development, hyperparameter tuning, and final performance evaluation.
- They train a YOLOv11-small architecture on these subsets to assess object detection robustness across simulated thermal, nocturnal, and obscured conditions.
- The transformed subsets are evaluated individually and comparatively to measure how well the detection pipeline generalizes when faced with domain shifts and low-level visual interference.
Processing and Metadata Construction
- All visual transformations rely on OpenCV functions to ensure reproducible domain shifts while preserving the underlying spatial structure of the original frames.
- Annotation metadata remains consistent across all subsets, maintaining the original YOLO label files and normalized coordinate system without modification.
- The authors process full-frame imagery without applying any cropping strategies, ensuring that contextual scene information is retained for aerial surveillance tasks.
Method
The proposed methodology centers on a multi-modal object detection pipeline designed for robust performance across diverse imaging conditions. The system begins with a dataset composed of four distinct image modalities: Thermal, Grayscale, Night Vision, and ObscuraVision. Each modality contributes unique visual information, enabling enhanced object detection under varying environmental constraints. These inputs are processed through the YOLOv11s model, a lightweight and efficient deep learning architecture optimized for real-time applications. The model performs preprocessing, inference, and postprocessing to identify and localize objects within each frame. Following detection, key performance metrics—including mAP@50, mAP@50-95, precision, recall, and F1-score—are computed to evaluate detection accuracy and efficiency. The results are then subjected to performance analysis, where outcomes across modalities are compared to determine the most effective detection strategy. As shown in the figure below, the workflow proceeds from dataset input through model inference and performance evaluation, culminating in a comprehensive assessment of system capabilities.
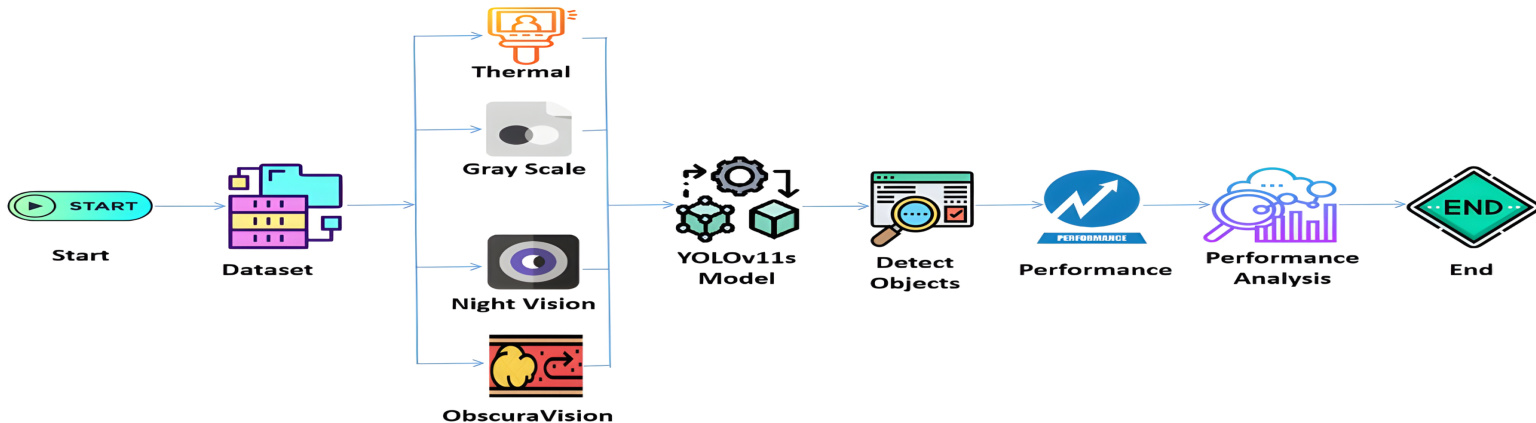
Experiment
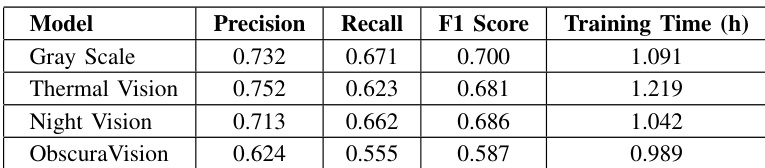
The YOLOv11s model was trained and comparatively evaluated across gray scale, thermal vision, night vision, and obscura vision modalities to validate its robustness in localizing military targets under diverse and visually challenging conditions. Night vision emerged as the most accurate modality, proving optimal for applications where detection reliability is paramount, whereas thermal and obscura inputs offered favorable balances between precision and inference speed. Gray scale processing proved the fastest but yielded the lowest detection accuracy, restricting its utility to latency-sensitive scenarios that can tolerate reduced reliability. Overall, the model maintains consistent classification and localization capabilities across degraded environments, demonstrating that modality selection should be guided by the required trade-off between computational efficiency and detection performance.
The authors evaluate the performance of an object detection model across four vision modalities using standard metrics such as precision, recall, F1 score, and training time. Results show that Night Vision achieves the highest precision and recall, while Gray Scale has the lowest performance across these metrics. The training times vary slightly among the modalities, with Thermal Vision requiring the longest training duration. Night Vision achieves the highest precision and recall among the tested modalities. Gray Scale exhibits the lowest precision, recall, and F1 score compared to other modalities. Training times vary across modalities, with Thermal Vision requiring the longest duration.
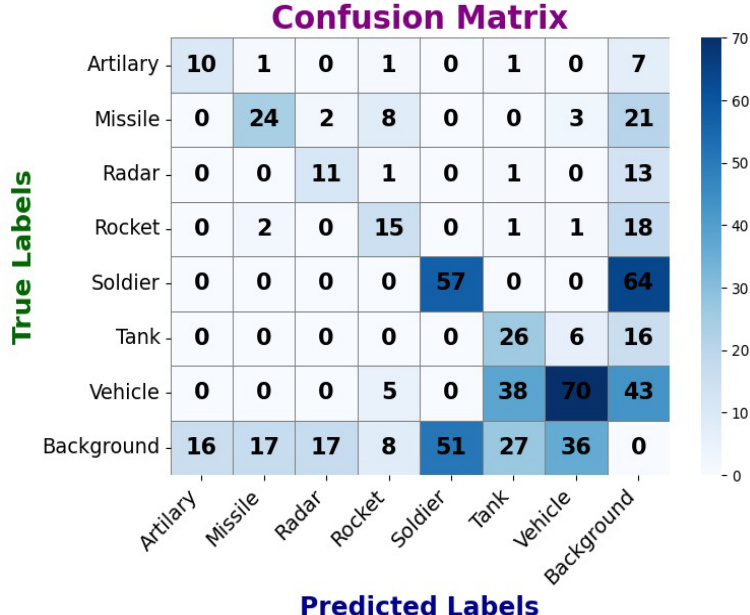
The authors present a confusion matrix that visualizes the performance of an object detection model on a grayscale dataset, showing classification results across multiple military target classes. The matrix illustrates the distribution of true and predicted labels, highlighting correct classifications and misclassifications, with the highest values along the diagonal indicating strong overall performance for most classes. The model achieves high accuracy for several classes, as indicated by large values along the diagonal of the confusion matrix. There are notable misclassifications, particularly for Artillery and Missile, which are often confused with each other. The model shows strong performance in distinguishing between different target types, with relatively low false positives for most classes.
The authors evaluate the performance of an object detection model across four vision modalities: Gray Scale, Thermal Vision, Night Vision, and ObscuraVision, using metrics such as mAP@50 and mAP@50-95. Results show that Night Vision achieves the highest detection accuracy, followed by ObscuraVision and Thermal Vision, while Gray Scale performs the worst in terms of accuracy despite the fastest processing time. The model demonstrates robustness across different imaging conditions, with performance trade-offs between accuracy and inference speed. Night Vision achieves the highest detection accuracy among all modalities. ObscuraVision offers a strong balance between accuracy and processing speed. Gray Scale provides the fastest processing time but has the lowest detection accuracy.

The experiments evaluate an object detection model across four imaging modalities to assess its classification accuracy, computational efficiency, and robustness under varying visual conditions. Qualitative analysis reveals that Night Vision consistently delivers the highest detection performance, while Gray Scale offers the fastest processing speed despite its lower accuracy. Thermal Vision requires the longest training duration, and ObscuraVision provides a balanced trade-off between precision and inference speed. Overall, the model demonstrates strong cross-modal adaptability, though certain target classes remain prone to misclassification due to visual similarities.