Command Palette
Search for a command to run...
Few-Shot Learning with Large Models Loaded via vLLM
Abstract
One-sentence Summary
By evaluating Gemma3 variants, Llama4 Scout, Qwen3, Magistral Small, and DeepSeek R1 against two gold standards for 2,780 medical, health, and life science papers, this study demonstrates that models exceeding 4 billion parameters reliably rate journal articles for research quality, that score averaging consistently improves accuracy while few-shot prompting provides only weak benefits, and that reasoning models deliver no performance advantage, thereby validating computationally efficient, offline-deployable LLMs for research evaluation.
Key Contributions
- This study introduces a systematic evaluation of medium-sized, smaller, and reasoning large language models using a dataset of 2,780 medical, health, and life science papers with two expert gold standards to quantify how parameter count and architecture influence research quality scoring.
- The analysis evaluates prompting techniques, demonstrating that averaging scores across multiple identical queries consistently improves alignment with expert ratings, whereas few-shot prompting provides only marginal benefits.
- Performance benchmarks confirm that models exceeding four billion parameters achieve results comparable to ChatGPT 4o-mini and Gemini 2.0 Flash without requiring specialized reasoning steps, supporting the deployment of smaller, offline-capable models in secure research evaluation workflows.
Introduction
Large language models are emerging as scalable alternatives to citation-based metrics for evaluating academic research quality, offering a pathway toward efficient, offline-deployable evaluation tools. While earlier studies demonstrated that major cloud-based and select open-weight models can moderately align with expert judgments, significant gaps remain regarding how model scale, reasoning capabilities, and prompting strategies affect scoring accuracy. Prior work also yielded inconsistent results across varying architectures and quantization methods, leaving the practical viability of smaller or reasoning-focused models largely unproven. To address these limitations, the authors systematically benchmark a diverse set of medium, small, and reasoning LLMs against expert quality ratings for thousands of biomedical papers. They evaluate few-shot prompting and iterative score averaging, demonstrating that models exceeding four billion parameters perform comparably to leading commercial systems. The authors ultimately establish that averaging multiple model outputs reliably improves alignment with human experts, while reasoning models provide no measurable benefit, confirming that smaller, resource-efficient LLMs are now credible and practical tools for research evaluation.
Dataset

-
Dataset Composition and Sources: The authors compile a benchmark dataset focused on the health and life sciences, drawn from the UK Research Excellence Framework (REF2021) Main Panel A. The collection spans six Units of Assessment covering clinical medicine, public health and primary care, allied health professions, psychology and neuroscience, biological sciences, and agriculture and veterinary sciences.
-
Subset Details and Filtering: A random sample of 500 journal articles was selected per Unit of Assessment, yielding an initial pool of 3,000 papers. After removing duplicates across overlapping institutional submissions, the final dataset contains 2,780 unique articles. The authors applied two filtering rules: they excluded articles lacking DOIs to ensure uniqueness tracking and removed the 10 percent of papers with the shortest abstracts, which typically represent short-form contributions.
-
Data Usage and Evaluation Setup: The authors use this collection exclusively as a static evaluation benchmark rather than for model training, meaning there is no training split or mixture ratio. It serves as a fixed test set to compare the research quality prediction capabilities of various LLMs. The dataset is processed into two parallel scoring streams to act as independent ground truths for model assessment. The first stream relies on departmental mean quality scores, where each article is assigned the average REF2021 rating of its submitting department. Articles submitted by multiple departments receive the mean of those departmental averages. The second stream uses a custom gold standard where the first author independently rates each paper on a nine-point scale aligned with REF2021 criteria, norm referenced to match official UoA distributions.
-
Processing and Metadata Construction: The authors construct metadata by verifying DOI availability and tracking cross-UoA overlaps. For the departmental proxy, aggregate submission scores are converted into per-article values by averaging the percentage breakdowns of quality ratings. To mitigate potential departmental biases in the proxy scores, the independent author ratings provide a triangulated quality metric. All text and metadata are preserved in their original form, with no cropping applied beyond the initial short-abstract exclusion.
Method
The authors leverage a structured framework to evaluate research quality using large language models (LLMs), focusing on the alignment between human expert assessments and AI-generated scores. The overall approach involves generating a large dataset of articles across multiple disciplines, each annotated with expert scores, and then applying various LLMs with different prompting strategies to assess the same articles. The primary evaluation metric is rank correlation between the human and AI scores, as previous studies have demonstrated that absolute score accuracy is less meaningful due to the tendency of LLMs to produce scores that cluster around specific values. The framework is designed to test how different prompting strategies, particularly few-shot prompting and averaging, affect the consistency and reliability of the LLM outputs.
The prompting strategy begins with a system prompt that defines the evaluation task in terms of originality, significance, and rigour—dimensions aligned with the research assessment guidelines for the REF2021 Main Panel A. This prompt is adapted to address the LLM directly as an academic expert, ensuring the model interprets the task appropriately. For models that support separate system and user prompts, this system prompt is provided independently, while for others, the user prompt includes the full instructions. The core user prompt consists of the instruction "Score this article:", followed by the article title, a newline, the text "Abstract", and the article abstract. Full texts are excluded to reduce computational overhead and because prior research indicates that abstracts yield comparable correlation results with expert scores.
For the few-shot prompting approach, the authors design a strategy that includes example inputs with corresponding scores to guide the LLM. Given the challenge of defining a "correct" output due to the variability in expert reports, the few-shot method is carefully constructed to balance representativeness and practicality. The chosen strategy includes four example articles—covering all score levels from 1* to 4*—to provide a comprehensive range of evaluation standards. This approach is preferred over alternatives that limit examples to higher-scoring articles or use only two examples, as it ensures better differentiation across the full score spectrum, particularly for lower-quality articles. The examples are selected from a pool of articles not included in the main evaluation set to prevent data leakage and model memorization. Specifically, the authors employ a modified strategy labeled "Cx2", where two candidate articles are identified for each star level within each unit of assessment (UoA), and one is randomly selected per prompt to maintain diversity while preserving data integrity.
As shown in the figure below: the few-shot prompt structure begins with a sample article labeled with its score, followed by the title, abstract, and a separator ("###") to distinguish between examples and the target article. This format helps prevent confusion, especially in models that may otherwise process all input articles as part of the evaluation. The prompts are regenerated dynamically for each submission, ensuring that repeated evaluations of the same article use different combinations of examples, thereby reducing the risk of systematic bias.
A key component of the methodology is the use of averaging multiple LLM responses. The authors explore the hypothesis that averaging scores from multiple identical prompts improves reliability by better capturing the model’s internal probabilistic reasoning. This technique, while uncommon in general LLM applications, has been shown effective in prior work for research evaluation tasks. The current study provides robust evidence that averaging is beneficial across different models, supporting the idea that multiple evaluations help extract more consistent information from the model’s output distribution. This averaging process is applied to each article across multiple prompt iterations to produce a final aggregated score.
Experiment
The study evaluates the capacity of various large language models to rank academic articles for research quality by correlating their outputs with established human benchmarks across multiple disciplines. Controlled experiments validate the impact of model scale, prompting strategy, and architectural design, revealing that medium and smaller open-weight models achieve ranking accuracy comparable to larger systems, while specialized reasoning architectures offer no distinct advantage. Qualitative analysis further indicates that averaging multiple prompt iterations consistently enhances reliability, whereas few-shot techniques yield marginal gains primarily through increased prompt variety rather than direct example learning. Ultimately, the findings establish that smaller models provide a practical and secure alternative for relative article ranking, confirming this capability as a core function that effectively supports expert decision-making without demanding extensive computational resources.
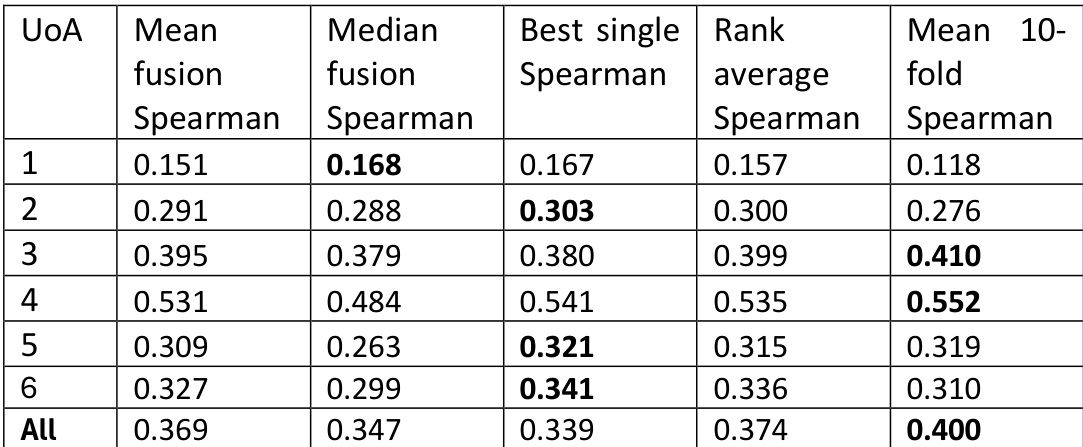
The the the table presents Spearman correlation results across different research assessment units, comparing various fusion methods for combining LLM scores. The results show that different fusion strategies yield varying levels of correlation, with some methods consistently outperforming others across units. The overall performance indicates that averaging scores from multiple models generally improves correlation with the gold standard. Averaging LLM scores across multiple models improves correlation with the gold standard compared to individual model scores. Different fusion methods show varying effectiveness across research assessment units, with some methods performing better in specific contexts. The highest correlations are observed for certain units, indicating that model performance can vary depending on the research domain.
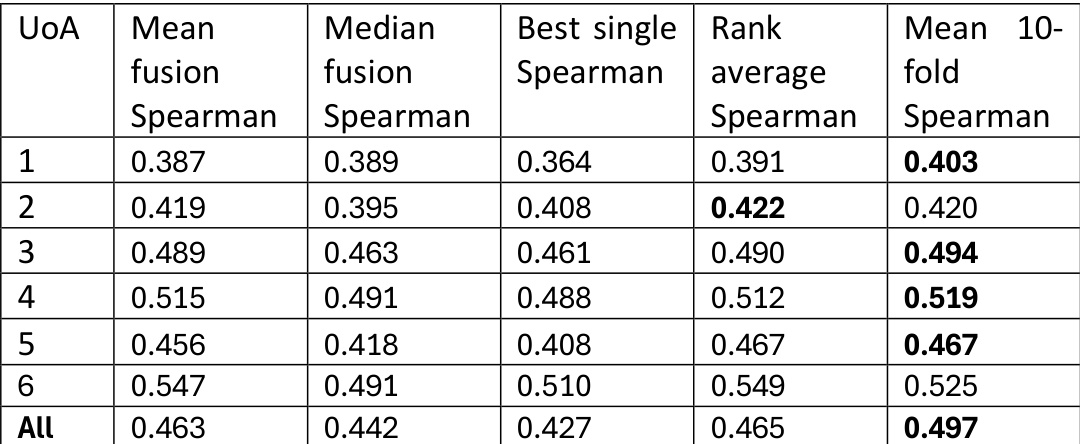
The the the table presents Spearman correlation results for different fusion methods across six UoAs and an overall average, showing that median fusion and rank average methods generally outperform mean fusion and single model approaches. The highest correlations are observed for UoA 4 and UoA 3, with median fusion performing best in most cases. Median fusion consistently achieves the highest Spearman correlations across most UoAs compared to other fusion methods. Rank average fusion performs better than mean fusion and single model approaches in most UoAs. UoA 4 and UoA 3 show the highest correlation values across all fusion methods, indicating stronger alignment with gold standards.
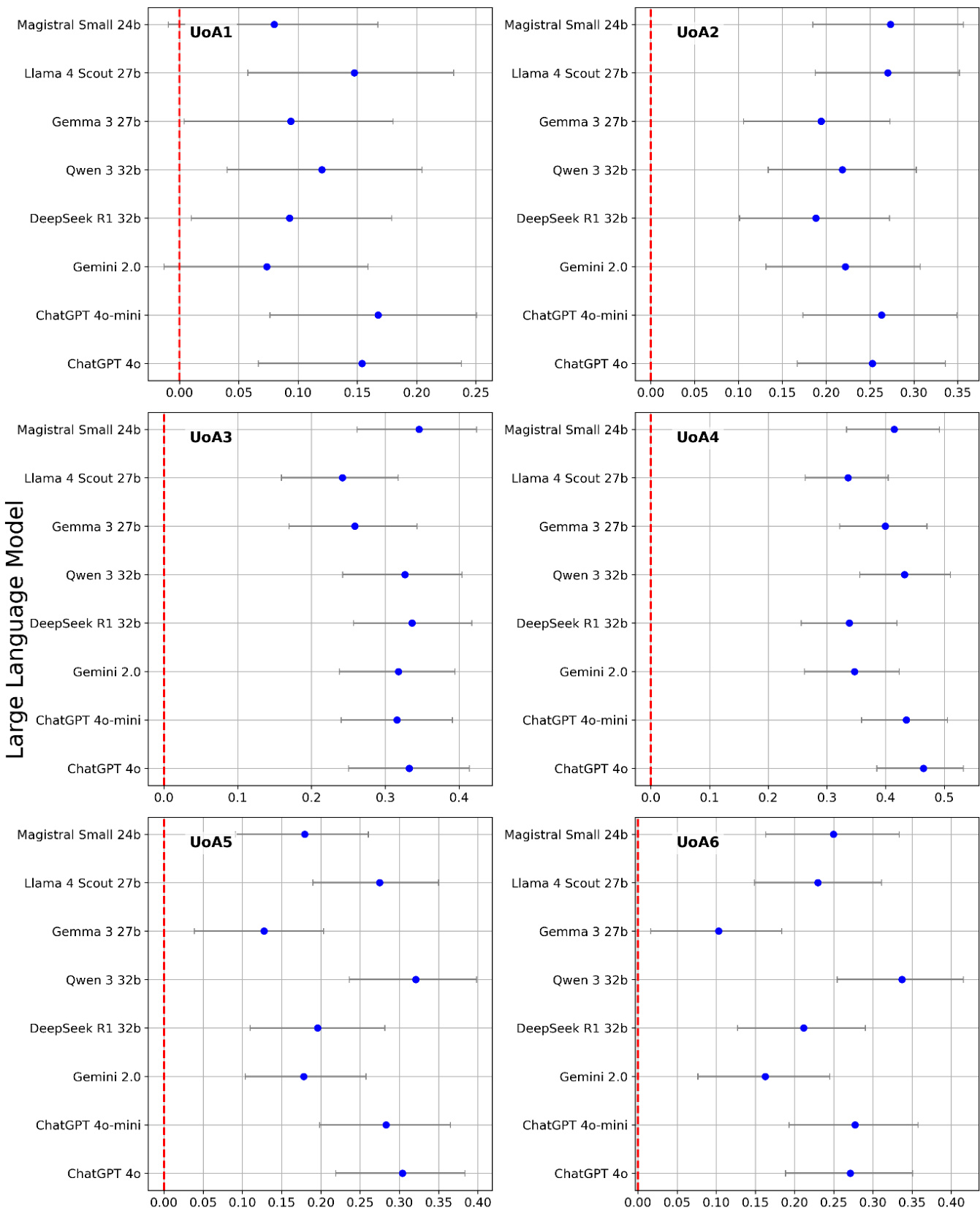
The authors compare the performance of various large language models in scoring academic articles, using Spearman correlation to measure alignment with human judgments. The results show that different models achieve varying levels of correlation, with some performing consistently across different evaluation metrics and others showing notable differences in their scoring patterns. Different large language models exhibit varying levels of correlation with human evaluations, with some models showing consistent performance across different metrics. The performance of models varies significantly, with some models achieving higher correlations than others, indicating differences in their ability to assess research quality. The study highlights that model performance can differ based on the specific evaluation metric used, suggesting that the choice of metric impacts the observed effectiveness of the models.
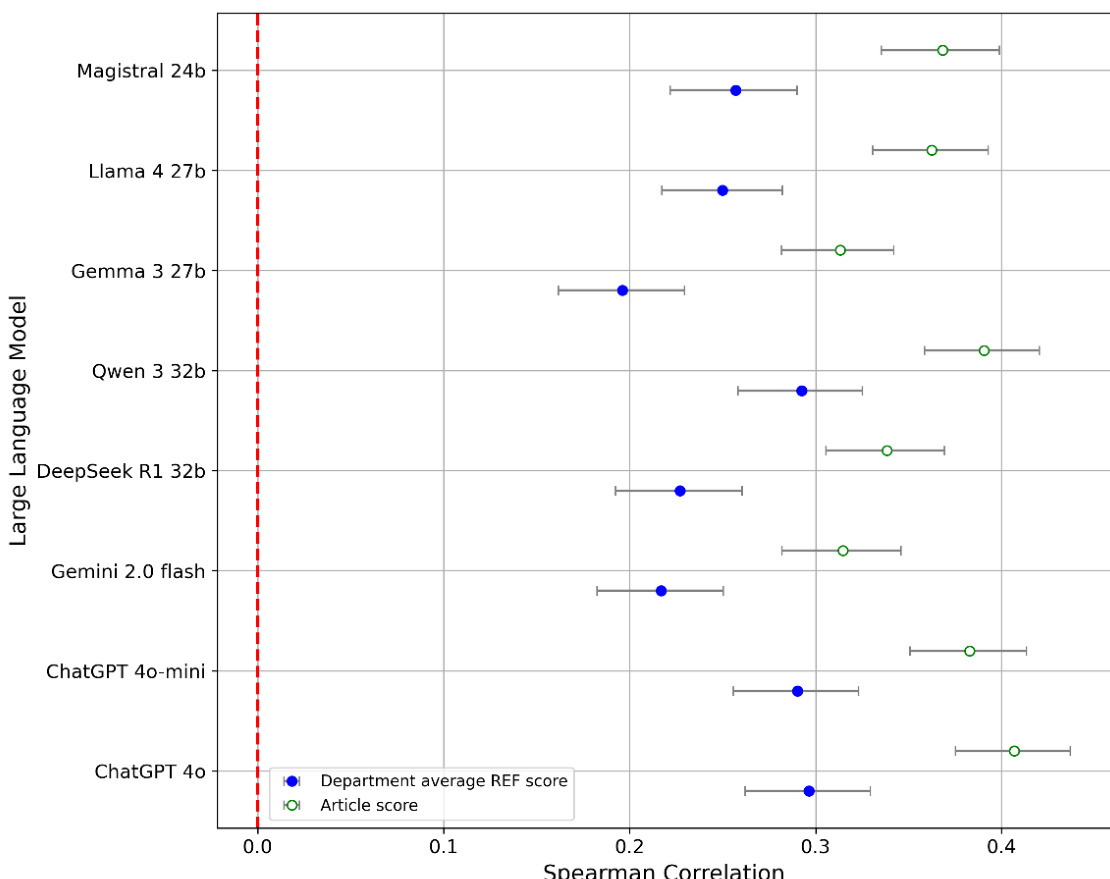
The experiment evaluates the performance of various large and medium-sized language models in scoring academic articles based on research quality, using Spearman correlation to measure alignment with human judgments. Results show that model performance varies across different units of assessment, with some models performing consistently well across most units while others show significant variation, and that averaging multiple scores improves reliability. The analysis also suggests that few-shot prompting may enhance performance, though not necessarily through learning from examples, and that reasoning models do not offer a clear advantage over non-reasoning models for this task. Averaging multiple model scores improves correlation with human judgments across all units of assessment. Model performance varies significantly across different units of assessment, with some models showing consistent results and others being highly variable. Reasoning models do not outperform non-reasoning models, despite being slower and more resource-intensive.
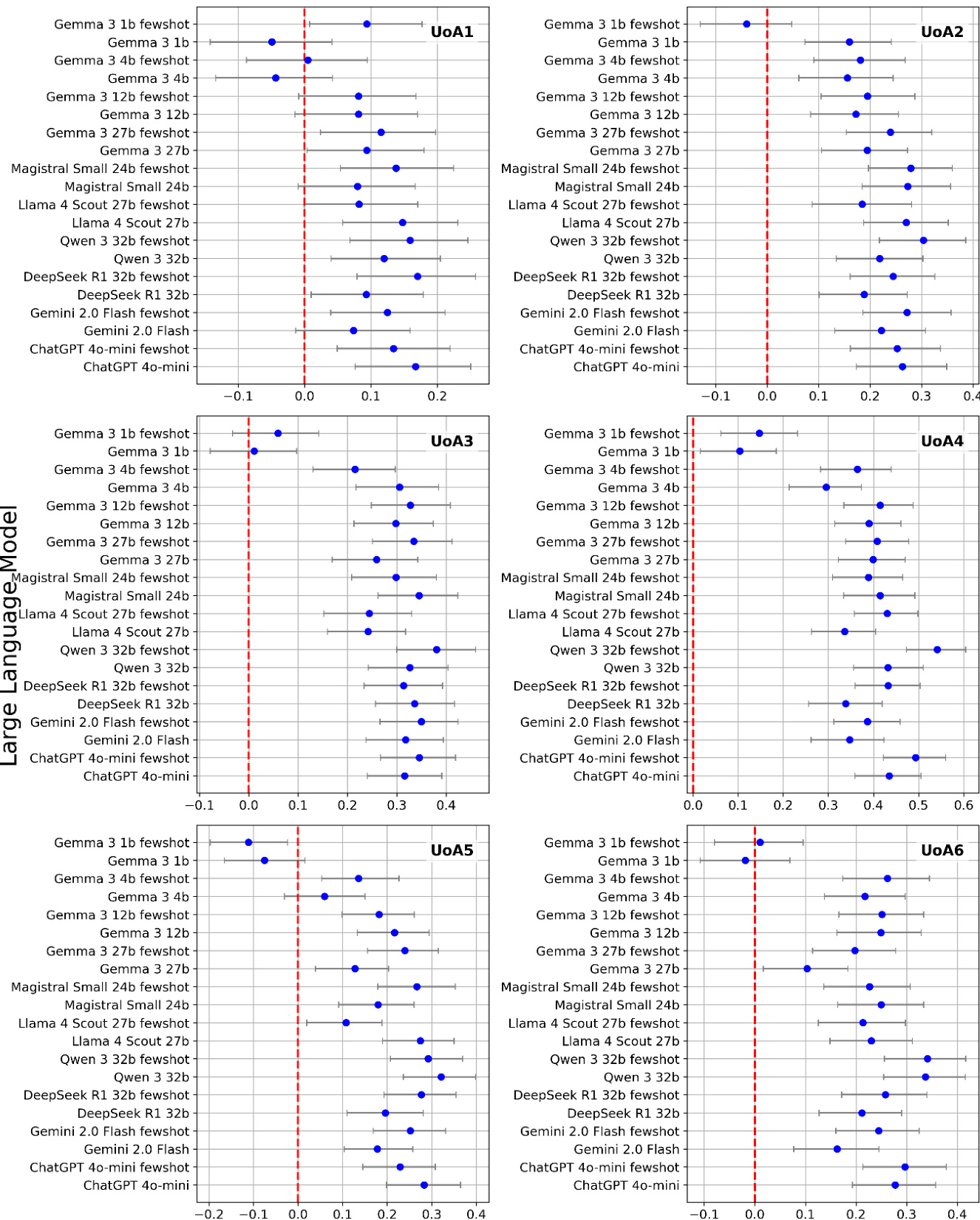
The authors evaluate various large and medium-sized language models for their ability to assess research quality in academic articles, focusing on how model size, prompting strategies, and architectural features affect performance. Results show that smaller models can achieve similar correlations to larger ones, and averaging multiple scores improves consistency, while few-shot prompting offers limited benefits that may stem from prompt variation rather than learning from examples. Smaller models perform similarly to larger ones, with no clear advantage for cloud-based or reasoning models in research quality scoring. Averaging multiple model scores consistently improves correlation with human judgments compared to using a single score. Few-shot prompting shows weak evidence of improvement, potentially due to increased prompt variation rather than learning from examples.
The experimental series evaluates large and medium-sized language models for scoring academic research quality against human judgments across multiple assessment units. The studies validate that aggregating predictions through averaging or median-based fusion consistently enhances alignment with human assessments compared to relying on single-model outputs. Additionally, the experiments confirm that smaller models can match larger counterparts, while advanced features like reasoning architectures or few-shot prompting provide no reliable performance gains. Collectively, these findings establish that model ensembling remains the most robust approach for improving scoring consistency across diverse research domains.