Command Palette
Search for a command to run...
One-click Deployment of Dia-1.6B
Abstract
One-sentence Summary
EmoSSLSphere is a multilingual emotional text-to-speech framework that encodes emotions within a continuous spherical coordinate space using discrete self-supervised tokens, with evaluations on English and Japanese corpora demonstrating significant improvements in speech intelligibility, spectral fidelity, prosodic consistency, naturalness, and emotional expressiveness over baseline models.
Key Contributions
- The paper introduces EmoSSLSphere, a multilingual emotional text-to-speech framework that encodes emotions within a continuous spherical coordinate space to enhance cross-lingual synthesis controllability.
- The architecture integrates these interpretable spherical emotion vectors with discrete token features derived from self-supervised learning to achieve fine-grained emotional control and robust cross-lingual emotion transfer.
- Evaluations on English and Japanese corpora demonstrate that the framework significantly outperforms baseline models in speech intelligibility, spectral fidelity, and subjective naturalness, while ablation studies verify the effectiveness of the discrete token integration.
Introduction
Multilingual emotional text-to-speech synthesis is critical for building expressive voice interfaces that adapt naturally across different languages. Prior methods typically rely on explicit emotion labels or monolingual spherical vector models, which often fail to capture fine-grained prosodic nuances, cause cross-lingual emotional drift, or compromise speaker identity. The authors leverage spherical emotion vectors to map affective states into an interpretable continuous space and combine them with discrete tokens derived from self-supervised learning. This architecture decouples emotional modulation from language-specific acoustic patterns, enabling precise emotional control and robust cross-lingual transfer while preserving natural prosody and speaker consistency.
Dataset

-
Dataset Composition and Sources: The authors evaluate the model using single-speaker emotional speech corpora in English and Japanese to isolate prosodic and emotional modeling effects, deliberately avoiding speaker adaptation or cross-speaker fine-tuning.
-
Subset Details:
- English: 80 utterances sourced from the Emotional Speech Dataset (ESD), split evenly into 20 samples each for Angry, Sad, Happy, and Surprised emotions, all recorded by a single female speaker.
- Japanese: 60 utterances sourced from the JVNV corpus, split evenly into 10 samples each for Angry, Sad, Happy, Surprised, Disgust, and Fear emotions, also recorded by a single female speaker.
-
Data Usage and Processing: The training pipeline enforces a strict separation between evaluation and training samples to prevent data leakage. During inference, ground-truth utterances are used as reference speech drawn from the same speaker and language as the target synthesis.
-
Additional Processing Details: The provided documentation does not specify cropping strategies, metadata construction, or mixture ratios, emphasizing instead strict speaker isolation and clean dataset partitioning.
Method
The authors leverage a modular architecture for EmoSSL-Sphere, a multilingual emotional text-to-speech (TTS) framework designed to address challenges in integrating linguistic, emotional, and acoustic features across languages. The system is structured around four primary components: an Emotional Style and Intensity Encoder, an SSL-based Feature Encoder, a Text Encoder, and a Mel-spectrogram Decoder. These modules operate independently to extract complementary speech characteristics, with their embeddings later fused to condition the decoder. The overall framework supports both pre-training of individual encoders and a subsequent fine-tuning stage of the decoder, ensuring modularity and efficient adaptation.
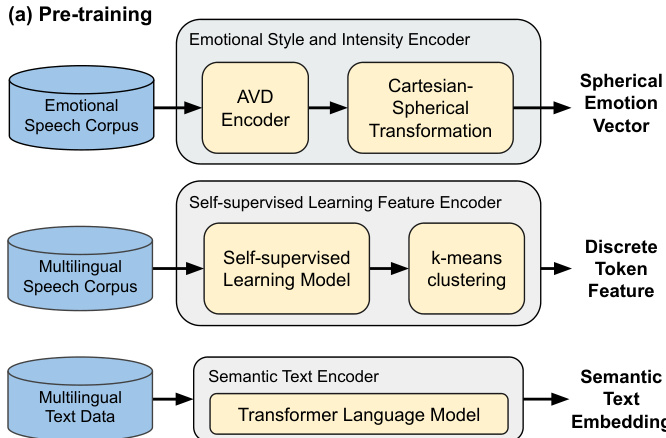
As shown in the figure below, the pre-training phase involves three distinct encoders. The Emotional Style and Intensity Encoder processes reference speech to extract Arousal-Valence-Dominance (AVD) vectors from Mel-spectrograms using a pretrained model. These vectors, initially in Cartesian coordinates, are transformed into spherical coordinates (r,θ,ϕ) to enable smooth interpolation and continuous control over emotional intensity. To incorporate categorical emotion information, discrete Emotion IDs are embedded into one-hot vectors and concatenated with the spherical AVD representation, forming a hybrid emotional embedding that combines fine-grained nuance with explicit stylistic priors. The SSL-based Feature Encoder utilizes HuBERT, a self-supervised model trained on large-scale speech data, to extract prosodic cues. Hidden states from the 9th layer of the 12-layer base model are selected to balance phonetic detail and high-level semantics. These continuous features are then quantized using language-specific k-means clustering to produce discrete prosody tokens, which capture universal yet weakly language-specific rhythmic and pitch patterns. The Text Encoder consists of two parallel branches: a Phoneme Encoder that processes input text into phoneme sequences via forced alignment tools to ensure accurate pronunciation, and a Semantic Encoder that employs DeBERTaV3 to generate higher-level semantic embeddings. These semantic embeddings condition the emotional and prosodic modules via cross-attention and are also concatenated with other embeddings for decoder input.
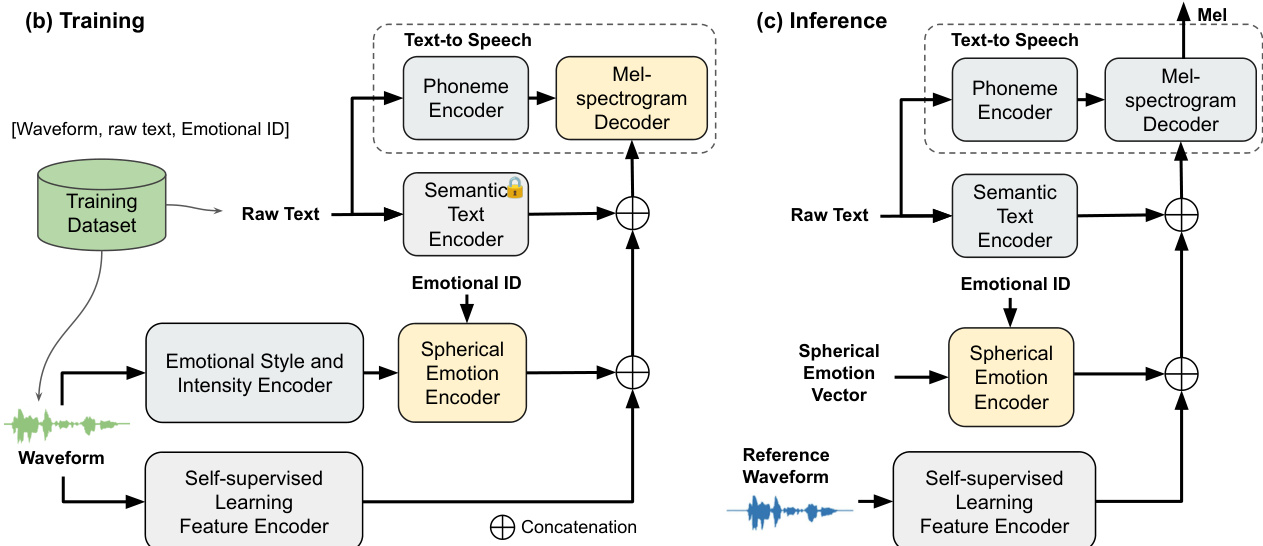
The training procedure consists of two phases. In the pre-training stage, each encoder is trained independently: the Emotional Style and Intensity Encoder converts AVD values into spherical embeddings, the SSL-based Feature Encoder discretizes HuBERT features using language-specific k-means, and the Semantic Text Encoder uses pre-trained DeBERTaV3 embeddings without further tuning. During the fine-tuning stage, the Mel-spectrogram Decoder, based on FastSpeech2, is trained using paired text-waveform data while keeping all encoder parameters frozen. Input embeddings—including phoneme sequences, spherical emotion vectors, discrete SSL tokens, speaker embeddings, and semantic embeddings—are projected into a shared latent space, concatenated, and linearly mapped to match the decoder’s input dimension. This fusion mechanism enables the decoder to effectively integrate linguistic, prosodic, emotional, and speaker-related information. Inference requires two inputs: the target text and a reference speech waveform. The reference provides emotional and prosodic cues, while the phoneme encoder ensures intelligible pronunciation. Speaker identity is preserved via a fixed speaker embedding. The combined embeddings are fed into the decoder to generate expressive, speaker-consistent speech. The model architecture is designed to support multilingual adaptation by instantiating separate encoder modules for each language, thereby avoiding cross-lingual interference.
Experiment
The evaluation compares EmoSSLSphere against two baseline models and conducts ablation studies to validate the individual contributions of its reference waveform conditioning, semantic text encoder, and SSL token discretization modules. Experimental results demonstrate that the framework significantly enhances semantic consistency, acoustic fidelity, and perceived naturalness across both English and Japanese. Qualitative analyses further confirm its ability to accurately capture fine-grained emotional contours while maintaining robust cross-lingual prosodic integrity. Ultimately, these findings validate that the integrated components work synergistically to deliver superior emotional control and high-quality multilingual speech synthesis.
The authors evaluate EmoSSLSphere against baseline methods across multiple dimensions including intelligibility, acoustic quality, naturalness, and emotional expressiveness. Results show that EmoSSLSphere achieves superior performance compared to baselines in most metrics, particularly in emotional expressiveness and acoustic fidelity, with consistent improvements across both English and Japanese languages. EmoSSLSphere outperforms baseline methods in emotional expressiveness, achieving lower error rates in emotion-specific metrics for both English and Japanese. The proposed method demonstrates superior acoustic quality with improved spectral and pitch accuracy compared to baselines. Ablation studies confirm that each component of EmoSSLSphere contributes significantly to overall performance, especially in maintaining naturalness and emotional controllability.

The authors evaluate EmoSSLSphere against baseline models using objective and subjective metrics across multiple dimensions, including intelligibility, acoustic quality, naturalness, and emotional expressiveness. Results show that EmoSSLSphere outperforms baselines in most metrics, particularly in naturalness and emotional control, with consistent improvements across both English and Japanese. Ablation studies further confirm the importance of key components such as reference waveform conditioning, semantic text encoding, and discrete SSL token discretization. EmoSSLSphere achieves the highest naturalness ratings and lowest acoustic distortion compared to baseline models in both English and Japanese. The model demonstrates superior emotional expressiveness with lower AVD RMSE values, indicating better control over emotional prosody. Ablation studies confirm that removing key components like reference waveform conditioning or semantic text encoding leads to significant performance degradation.
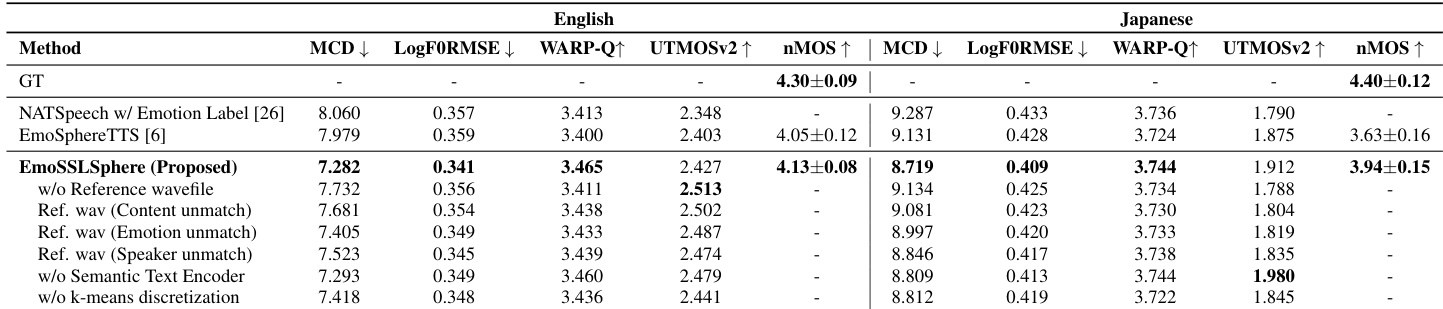
The authors evaluate EmoSSLSphere against baseline methods across multiple dimensions including intelligibility, acoustic quality, naturalness, and emotional expressiveness. Results show that EmoSSLSphere achieves superior performance compared to baselines, particularly in reducing error rates and improving semantic and prosodic fidelity, with consistent gains across both English and Japanese. Ablation studies further demonstrate the importance of each component in the model's design. EmoSSLSphere outperforms baseline methods in intelligibility, achieving lower error rates and higher speech quality metrics across both English and Japanese. The proposed model demonstrates improved emotional expressiveness by achieving lower AVD RMSE values, indicating more accurate emotional control compared to baselines. Ablation studies confirm that key components such as reference waveform conditioning and semantic text encoding are essential for maintaining high performance in prosodic and emotional fidelity.

The authors evaluate EmoSSLSphere against established baseline models across English and Japanese speech, assessing intelligibility, acoustic quality, naturalness, and emotional expressiveness. The experiments demonstrate that the proposed framework consistently outperforms baselines by delivering superior acoustic fidelity and more precise emotional control while maintaining high speech naturalness. Ablation studies further validate the architectural design by confirming that core components such as reference waveform conditioning and semantic text encoding are essential for preserving prosodic accuracy and emotional controllability. Overall, the findings establish EmoSSLSphere as a robust solution for high-fidelity, emotionally expressive speech synthesis across multiple languages.