Command Palette
Search for a command to run...
SGDFuse: SAM-Guided Diffusion Model for High-Fidelity Infrared and Visible Image Fusion
SGDFuse: SAM-Guided Diffusion Model for High-Fidelity Infrared and Visible Image Fusion
Xiaoyang Zhang Jinjiang Li Guodong Fan Yakun Ju Linwei Fan Jun Liu Alex C. Kot
One-click Deployment of IC-Light
Abstract
Infrared and visible image fusion (IVIF) is essential for integrating thermal saliency with textural details to support downstream perception. However, most existing approaches suffer from "semantic blindness," leading to the erroneous suppression of thermal targets and the introduction of visual artifacts. To address this, we propose SAM-Guided Diffusion Fusion Network (SGDFuse), a novel Semantic-Guided Generation (SGG) framework that reframes IVIF as a semantically-steered generative task rather than simplistic pixel mapping. Our method uniquely couples high-level semantic priors from the Segment Anything Model (SAM) with the high-fidelity generative power of a conditional diffusion model. We employ a deliberate two-stage strategy to decouple multimodal alignment from iterative refinement: Stage I establishes a robust structural foundation via preliminary fusion, while Stage II utilizes dual-modality semantic masks as spatial anchors to guide the diffusion process toward a semantically coherent, high-fidelity reconstruction. Comprehensive experiments demonstrate that SGDFuse not only delivers state-of-the-art image quality but also enhances downstream task performance, confirming its effectiveness as a new Methodological Framework for semantically aware image fusion.
One-sentence Summary
SGDFuse addresses the semantic blindness of conventional infrared and visible image fusion by coupling Segment Anything Model priors with a conditional diffusion network, utilizing a two-stage strategy that first establishes structural alignment and then employs dual-modality semantic masks as spatial anchors to guide iterative refinement, ultimately generating high-fidelity, semantically coherent images that enhance downstream task performance.
Key Contributions
- Introduces SGDFuse, a Semantic-Guided Generation framework that reframes infrared and visible image fusion as a semantically-steered generative task to mitigate the semantic blindness and visual artifacts prevalent in conventional pixel-mapping approaches.
- Proposes a decoupled two-stage architecture integrated with a closed-loop guidance system that leverages Segment Anything Model masks as explicit spatial anchors to steer a conditional diffusion model toward high-fidelity, semantically coherent reconstruction.
- Demonstrates through extensive experiments that the framework achieves state-of-the-art image quality and significantly improves performance on downstream perception benchmarks, including object detection and semantic segmentation.
Introduction
Infrared and visible image fusion is essential for combining thermal saliency with rich visual textures, enabling robust environmental perception in critical applications like autonomous driving and medical diagnostics. However, prior methods typically treat fusion as a low level pixel mapping process, which results in semantic blindness, blurred target boundaries, and the erroneous suppression of crucial thermal features. To address these challenges, the authors leverage the Segment Anything Model to extract explicit semantic masks and integrate them into a conditional diffusion framework. Their proposed SGDFuse network reframes image fusion as a semantically guided generation task, employing a two stage architecture that first establishes structural priors and then uses dual modality masks to steer iterative refinement. This closed loop guidance system ensures high fidelity reconstruction while preserving task critical information, significantly enhancing performance in downstream vision tasks.
Dataset
The authors evaluate their proposed model using four infrared and visible image datasets, each chosen to cover a range of scene conditions and resolutions. The collection is composed of the following subsets:
- MSRS: 361 test pairs at 640×480 resolution
- M³FD: 4,164 image pairs at 1024×768 resolution
- LLVIP: 16,836 image pairs at 1280×1024 resolution
- RoadScene: 221 registered infrared-visible pairs
For experimentation, the authors rely on these datasets primarily for model evaluation. The text specifies test splits for MSRS, M³FD, and LLVIP, while RoadScene is applied as a complete set of registered pairs. No training splits, mixture ratios, or data augmentation pipelines are described in this section. The authors process the data by using the original registered pairs directly, with no additional cropping, metadata construction, or filtering rules applied. All datasets are available from the authors upon request.
Method
The proposed framework, SGDFuse, employs a two-stage architecture designed to achieve high-fidelity multimodal image fusion by decoupling structural alignment from generative refinement. The overall process begins with the extraction of complementary features from the infrared (IR) and visible (VIS) inputs. In the first stage, the IR image is processed through a Multi-Scale Feature Enhancement Module (MSFEM), which utilizes a parallel convolutional structure with kernels of varying receptive fields (1×1, 3×3, 5×5, 7×7) to capture structural details at multiple scales. The features from the larger kernels are concatenated and enhanced through a sequence of depthwise and pointwise convolutions before being fused with the shallow features from the 1×1 branch. This fused representation is then refined using a channel attention mechanism and a residual connection to produce an enhanced IR feature map. Concurrently, the VIS image is encoded by a Transformer Block (TB) that leverages multi-head self-attention to extract global context and fine-grained texture information. The features from both modalities are then aligned and selectively fused via a cross-attention pathway, generating an initial fused image that integrates salient thermal targets from the IR with high-resolution texture details from the VIS. 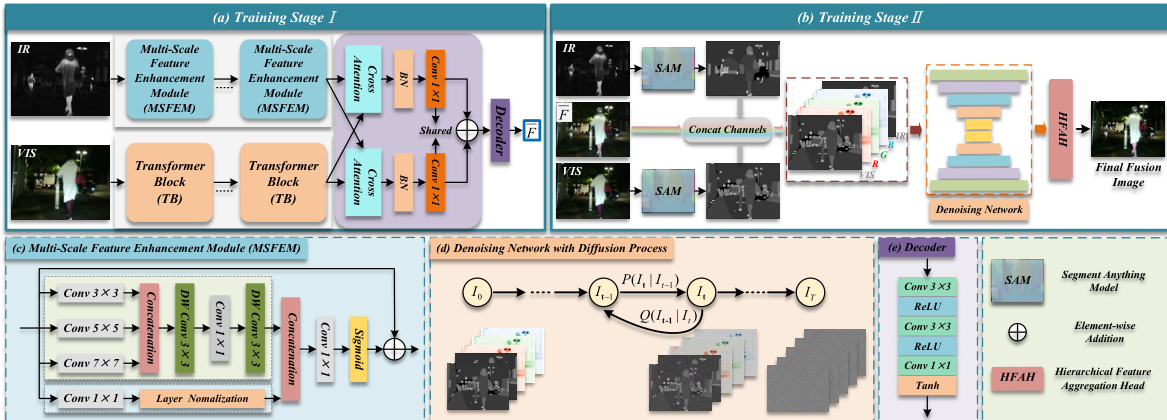
In the second stage, the initial fused image is refined using a conditional diffusion model to enhance structural fidelity and semantic consistency. The framework leverages the Segment Anything Model (SAM) to generate high-quality semantic masks for both the IR and VIS images. These masks are then concatenated with the initial fused image to form a five-channel input, creating a task-aware guidance signal for the diffusion process. The diffusion model operates by first perturbing this five-channel input with Gaussian noise over a series of time steps, progressively transforming the image into a standard Gaussian distribution. The reverse process then learns to denoise this perturbed image, guided by the semantic masks, to reconstruct a high-fidelity fused image. 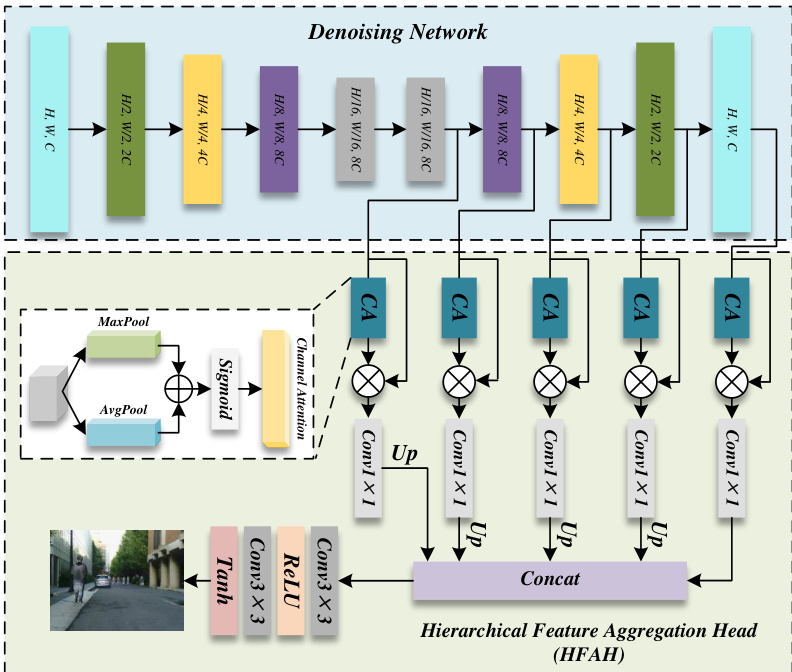
The core of the diffusion process is a denoising network based on a U-Net architecture. This network is structured with a contracting path that downsamples the input to extract deep features and an expanding path that restores spatial resolution. The network takes the five-channel input, consisting of the three-channel fused image and two semantic masks, and estimates the noise added at each time step. The reverse diffusion process iteratively denoises the input, with the mean of the conditional Gaussian distribution being predicted by the network, ultimately producing the final fused image. To further enhance the quality of the reconstructed image, a Hierarchical Feature Aggregation Head (HFAH) is integrated into the decoder path. The HFAH aggregates multi-level decoded features and incorporates a spatial attention mechanism to jointly optimize structural detail and semantic consistency. The aggregated features are concatenated and passed through a fusion head, which consists of multiple 3×3 convolutional layers, to generate the final three-channel fused image. A Tanh activation function is applied to the output to enhance texture continuity and fine detail expression. The entire framework is trained using a combination of task-specific loss functions. In the first stage, the loss is a combination of intensity and gradient losses to ensure the preliminary fused image aligns with the visible image's structure and preserves thermal information from the infrared image. In the second stage, the loss includes a mask-guided intensity loss and a mask-guided gradient loss, which are applied within the salient regions defined by the semantic masks to enhance luminance consistency and edge clarity, respectively. This two-stage approach effectively resolves the conflict between cross-modal feature extraction and high-fidelity reconstruction, leading to fused images with superior structural and semantic quality.
Experiment
Evaluated across multiple visible-infrared, medical, and downstream vision datasets against numerous baselines, the experimental setup validates the framework’s overall fusion quality, computational efficiency, and architectural robustness. Qualitative assessments and ablation studies confirm that the two-stage design effectively separates structural alignment from generative refinement, while semantic guidance and diffusion modeling consistently preserve thermal targets, fine textures, and perceptual consistency across challenging environments. Robustness and generalizability tests further validate the method’s resilience to segmentation inaccuracies and its adaptability to alternative semantic priors, demonstrating reliable performance even with imperfect inputs. Ultimately, these experiments collectively establish that the framework achieves a superior balance between high-fidelity fusion, practical inference speed, and cross-domain applicability for downstream vision tasks.
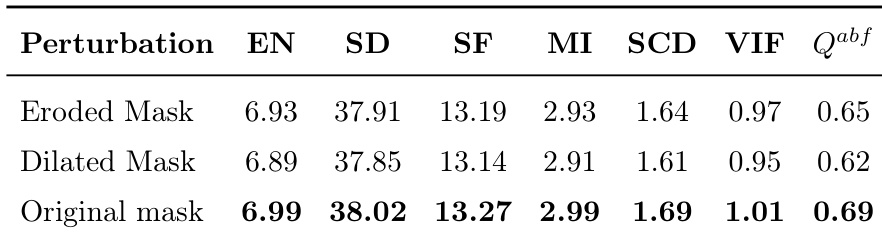
The authors analyze the robustness of their method to perturbations in semantic priors by evaluating the impact of eroded and dilated masks on fusion performance. Results show that while perturbations lead to measurable declines in metrics, the model maintains high performance and structural fidelity, indicating resilience to segmentation inaccuracies. The original mask configuration achieves the best overall results across all evaluated metrics. The model maintains high performance even with perturbed semantic masks, showing robustness to segmentation errors. Performance declines gradually with mask perturbations, indicating the framework is not overly sensitive to prior inaccuracies. The original mask configuration achieves the highest scores across all metrics, demonstrating optimal semantic guidance.
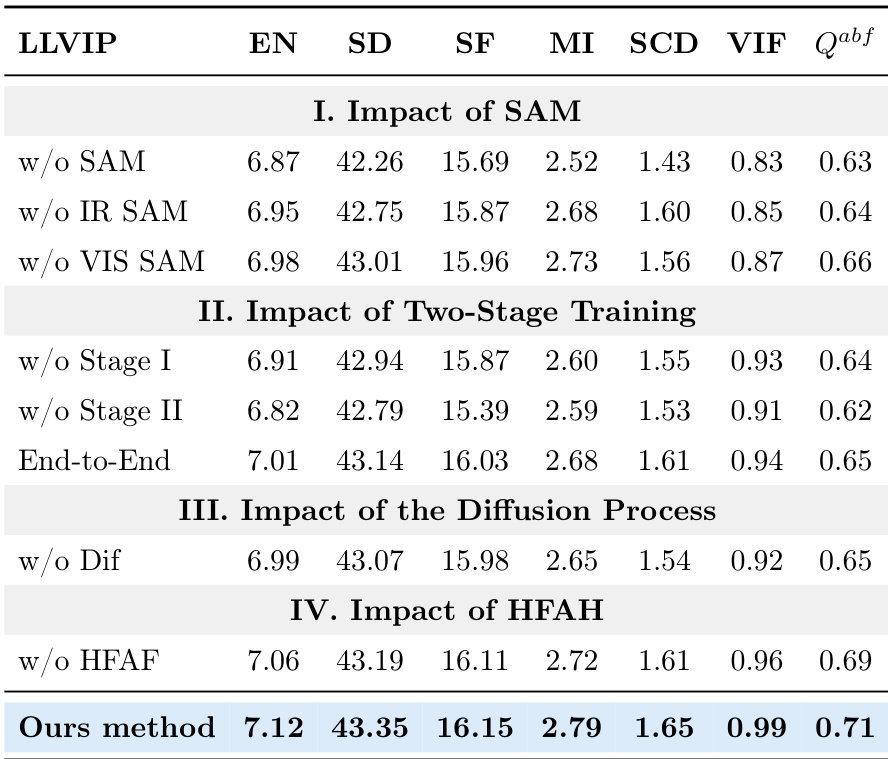
The the the table presents ablation study results on the LLVIP dataset, evaluating the impact of key components in the proposed method. It shows that removing semantic guidance, two-stage training, the diffusion process, or hierarchical feature aggregation leads to performance degradation across multiple metrics. The full method achieves the highest scores in all evaluated metrics, demonstrating the effectiveness of each component. Removing semantic guidance (SAM) results in lower performance across all metrics compared to the full method. The two-stage training approach outperforms both single-stage alternatives in all evaluated metrics. The diffusion process and hierarchical feature aggregation are critical, as their removal leads to significant drops in performance.
The authors compare their method against multiple state-of-the-art fusion approaches on the MSRS dataset using object detection metrics. Results show that their method achieves the highest performance across most categories, particularly in background and car detection, indicating superior structural fidelity and semantic consistency. The evaluation highlights strong detection accuracy and robustness in complex scenes. the method achieves the highest detection accuracy for most categories, especially in background and car detection. The proposed approach outperforms all baselines in mean IoU, demonstrating superior structural fidelity and semantic consistency. Compared to other methods, the method maintains clearer boundaries and more complete contours in complex scenes.
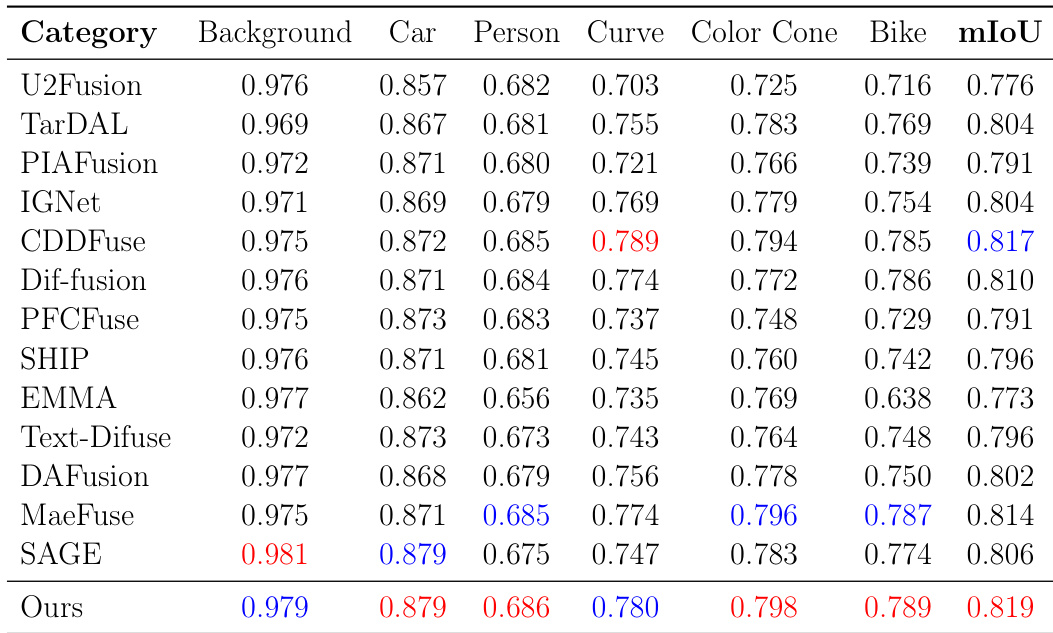
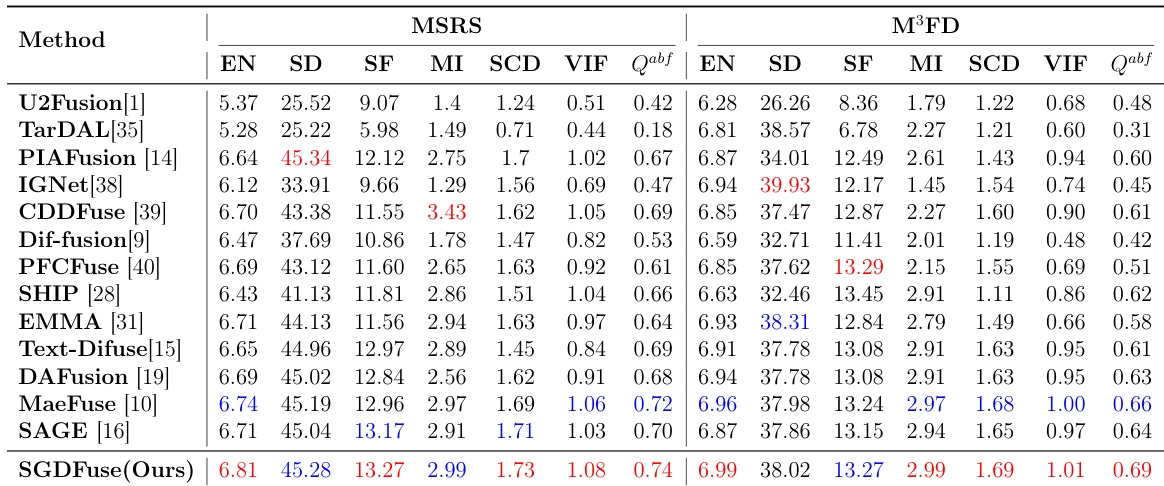
The authors evaluate their proposed method, SGDFuse, against multiple state-of-the-art fusion approaches on several benchmark datasets, including MSRS and M3FD. The results show that SGDFuse achieves the best performance across most metrics on both datasets, indicating superior image quality, structural consistency, and perceptual fidelity compared to existing methods. The method demonstrates strong generalization and robustness, particularly in challenging conditions such as low-light scenes and complex traffic environments. SGDFuse achieves the best performance on most metrics across multiple datasets, indicating superior fusion quality and structural consistency. The method shows strong generalization capabilities, performing well on diverse scenarios including low-light conditions and complex traffic environments. SGDFuse outperforms existing methods in downstream vision tasks such as object detection and semantic segmentation, demonstrating practical value.
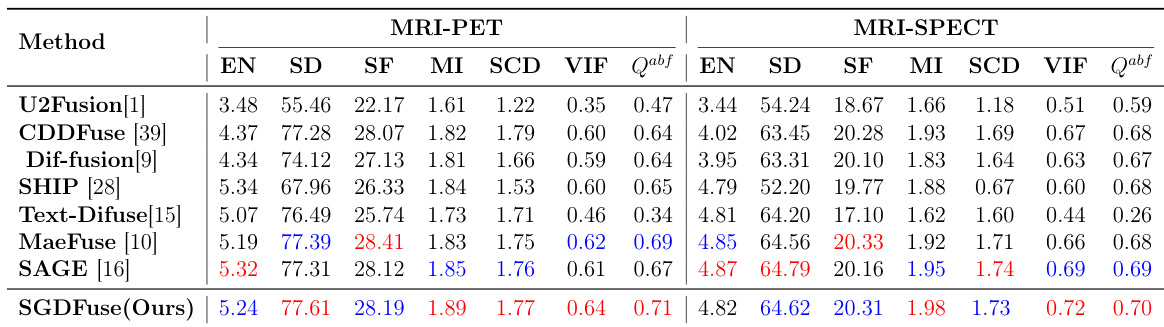
The authors evaluate their proposed method on medical image fusion datasets, comparing it against several state-of-the-art approaches. Results show that the method achieves the best or near-best performance across multiple metrics, indicating strong generalization and effectiveness in preserving structural details and enhancing image quality for medical imaging applications. The method achieves top performance on key metrics across both MRI-PET and MRI-SPECT datasets. It outperforms competing methods in preserving fine structures and enhancing overall image quality. The results demonstrate the method's robust generalization to medical image fusion domains beyond visible-infrared fusion.
The evaluation encompasses robustness testing against semantic mask perturbations, comprehensive ablation studies, and comparative assessments across visible-infrared and medical imaging benchmarks. These experiments validate that the proposed framework maintains high structural fidelity and semantic consistency even under segmentation inaccuracies, while confirming that each architectural component is essential for optimal performance. Across diverse datasets and downstream tasks, the method consistently outperforms state-of-the-art alternatives, demonstrating superior fusion quality, robust generalization in challenging environments, and strong adaptability to specialized domains like medical imaging.