Command Palette
Search for a command to run...
AR-RAG: Autoregressive Retrieval Augmentation for Image Generation
AR-RAG: Autoregressive Retrieval Augmentation for Image Generation
Jingyuan Qi Zhiyang Xu Qifan Wang Lifu Huang
One-click Deployment of InfiniteYou: High-Fidelity Image Generation Demo
Abstract
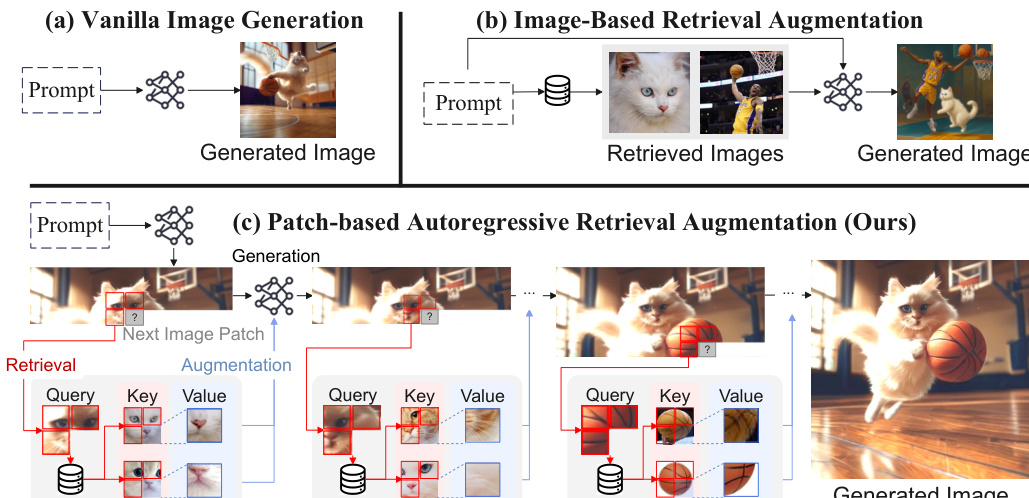
We introduce Autoregressive Retrieval Augmentation (AR-RAG), a novel paradigm that enhances image generation by autoregressively incorporating k-nearest neighbor retrievals at the patch level. Unlike prior methods that perform a single, static retrieval before generation and condition the entire generation on fixed reference images, AR-RAG performs context-aware retrievals at each generation step, using prior-generated patches as queries to retrieve and incorporate the most relevant patch-level visual references, enabling the model to respond to evolving generation needs while avoiding limitations (e.g., over-copying, stylistic bias, etc.) prevalent in existing methods. To realize AR-RAG, we propose two parallel frameworks: (1) Distribution-Augmentation in Decoding (DAiD), a training-free plug-and-use decoding strategy that directly merges the distribution of model-predicted patches with the distribution of retrieved patches, and (2) Feature-Augmentation in Decoding (FAiD), a parameter-efficient fine-tuning method that progressively smooths the features of retrieved patches via multi-scale convolution operations and leverages them to augment the image generation process.
One-sentence Summary
The authors propose AR-RAG, an autoregressive image generation framework that replaces static pre-generation retrieval with context-aware, patch-level k-nearest neighbor retrievals at each generation step, implemented via either the training-free DAiD distribution merging strategy or the parameter-efficient FAiD fine-tuning method to mitigate over-copying and stylistic bias.
Key Contributions
- Autoregressive Retrieval Augmentation (AR-RAG) enhances image generation by performing context-aware, patch-level k-nearest neighbor retrievals at each decoding step rather than relying on static pre-generation references. This dynamic approach adapts to evolving generation states and mitigates limitations such as over-copying and stylistic bias.
- Two parallel decoding frameworks operationalize this paradigm. Distribution-Augmentation in Decoding (DAiD) merges native patch distributions with retrieved patches using inverse distance weighting without additional training, while Feature-Augmentation in Decoding (FAiD) refines and blends retrieved features through parameter-efficient multi-scale convolutions and compatibility scoring.
- Experiments on the Midjourney-30K, Geneval, and DPG-Bench benchmarks demonstrate that both frameworks improve image coherence and naturalness with minimal computational overhead.
Introduction
Modern image generation models excel at producing photorealistic visuals but frequently struggle with structural inconsistencies, complex object interactions, and domain gaps. Retrieval-augmented generation addresses these challenges by incorporating external visual references to guide the synthesis process. However, prior approaches rely on static, prompt-based retrieval of entire reference images before decoding begins. This fixed strategy cannot adapt to evolving generation states, often introducing irrelevant details, stylistic bias, and visual hallucinations. To overcome these limitations, the authors leverage dynamic, patch-level k-nearest-neighbor retrieval throughout the generation process. By using already-generated surrounding patches as localized queries, the system fetches contextually relevant visual tokens from a pre-built database and integrates them via two parallel strategies. The first is a training-free decoding technique that merges predicted distributions with retrieved patches, while the second is a parameter-efficient fine-tuning pipeline that blends refined features through learned smoothing. This autoregressive design ensures precise, adaptive conditioning that preserves local semantic coherence while minimizing computational overhead.
Dataset
- Dataset Composition and Sources: The authors assemble a large-scale patch-based retrieval database and a dedicated fine-tuning collection sourced from CC12M, JourneyDB, DataComp, and Midjourney-v6.
- Subset Details: The retrieval database contains 13.6 million images, divided into 5.7 million from CC12M, 3.3 million from JourneyDB, and 4.6 million from DataComp. The fine-tuning dataset comprises 50,000 image-caption pairs, evenly split with 25,000 samples from CC12M and 25,000 from Midjourney-v6. All samples are filtered to strictly exclude any images that appear in the official testing splits, preventing data leakage.
- Processing and Metadata Construction: Each image is encoded into 576 patch features and corresponding tokens using the Janus-Pro quantized autoencoder tokenizer. The retrieval database indexes each patch vector as a value, while its key is generated by concatenating the vectors of its h-hop surrounding neighbors in a top-to-bottom, left-to-right order. Patches at image boundaries with missing neighbors are padded with zero vectors to preserve consistent key dimensions. The authors leverage the FAISS library to enable efficient similarity search across the indexed patches.
- Usage and Training Setup: During fine-tuning, the 50,000-pair dataset is augmented by retrieving the top-K database tokens that share similar neighborhood relationships with each ground-truth patch. This context-augmented data is used to fine-tune the Janus-Pro-1B and Show-o backbones. The training runs for a single epoch with a global batch size of 256, utilizing the AdamW optimizer, a 10 percent linear warm-up schedule, and a constant learning rate of 2e-4.
Method
The authors introduce Autoregressive Retrieval Augmentation (AR-RAG), a framework designed to enhance image generation by dynamically incorporating patch-level visual references during the autoregressive generation process. Unlike traditional retrieval-augmented methods that perform a single, static retrieval before generation, AR-RAG conducts context-aware retrievals at each generation step, using the previously generated patches as queries to retrieve relevant visual content. This autoregressive retrieval mechanism allows the model to adapt to evolving generation needs, mitigating issues such as over-copying and stylistic bias that are common in existing approaches.
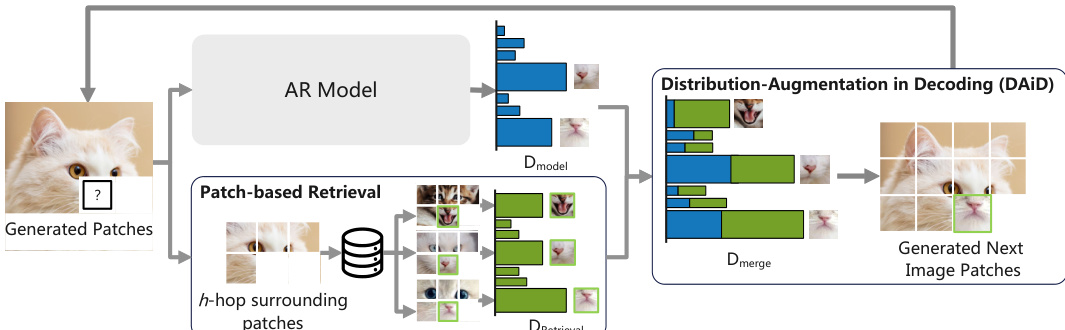
The core of AR-RAG is built upon two complementary frameworks: Distribution-Augmentation in Decoding (DAiD) and Feature-Augmentation in Decoding (FAiD). DAiD is a training-free, plug-and-play strategy that directly integrates retrieved patch information into the generation process by modifying the probability distribution of the next image token. When predicting the next token, DAiD uses the h-hop surrounding patches of the current position as a query to retrieve the top-K most similar patch representations from a pre-constructed database. These retrieved patches are mapped back to discrete token indices using the codebook, and a retrieval-based distribution is constructed by applying a softmax over their l2 distances, scaled by a retrieval temperature. This distribution is then merged with the model's predicted distribution using a weighted average, where the retrieval weight λ controls the influence of the retrieved patches. The final token is sampled from this merged distribution.
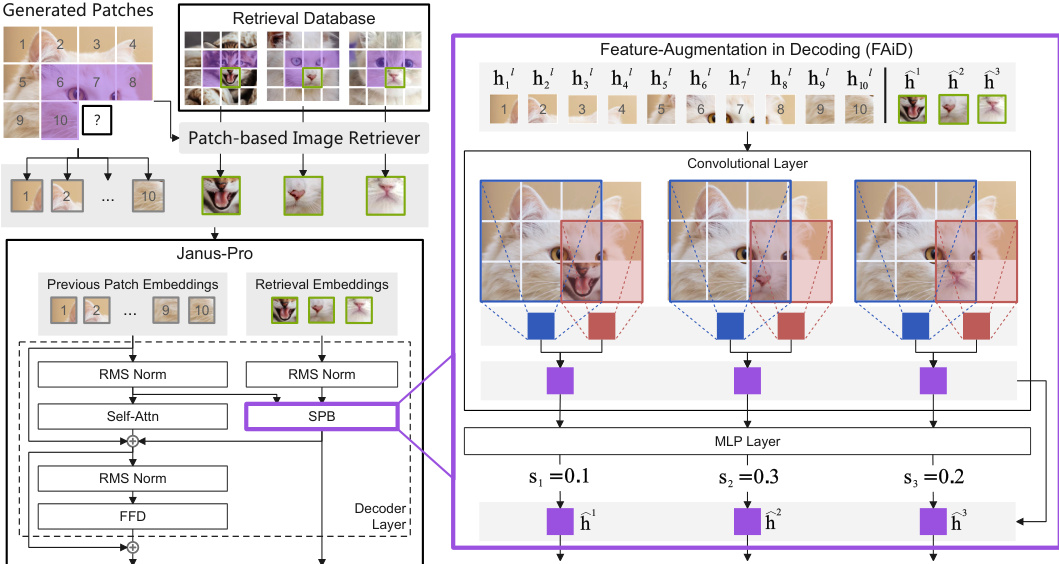
FAiD, on the other hand, is a parameter-efficient fine-tuning method that enhances the generation process by progressively refining and blending the features of retrieved patches. It operates by inserting FAiD modules at regular intervals within the decoder layers of the autoregressive model. For each predicted token, FAiD first retrieves the top-K relevant patches and their representations. To ensure spatial coherence, it applies multi-scale feature smoothing, which involves transforming the retrieved patch representations into the model's hidden space and then applying convolution operations at multiple scales (from 2×2 to Q×Q) to capture contextual patterns. This process is performed only when the kernel covers the target position, ensuring computational efficiency. The final refined representation for each retrieved patch is a weighted sum of the multi-scale features, with weights determined by learnable parameters. After feature smoothing, compatibility scores are computed for each refined patch to determine their contribution to the final representation. The augmented representation for the next image token is then calculated by combining the residual, the updated transformer layer output, and the weighted sum of the retrieved patch features.
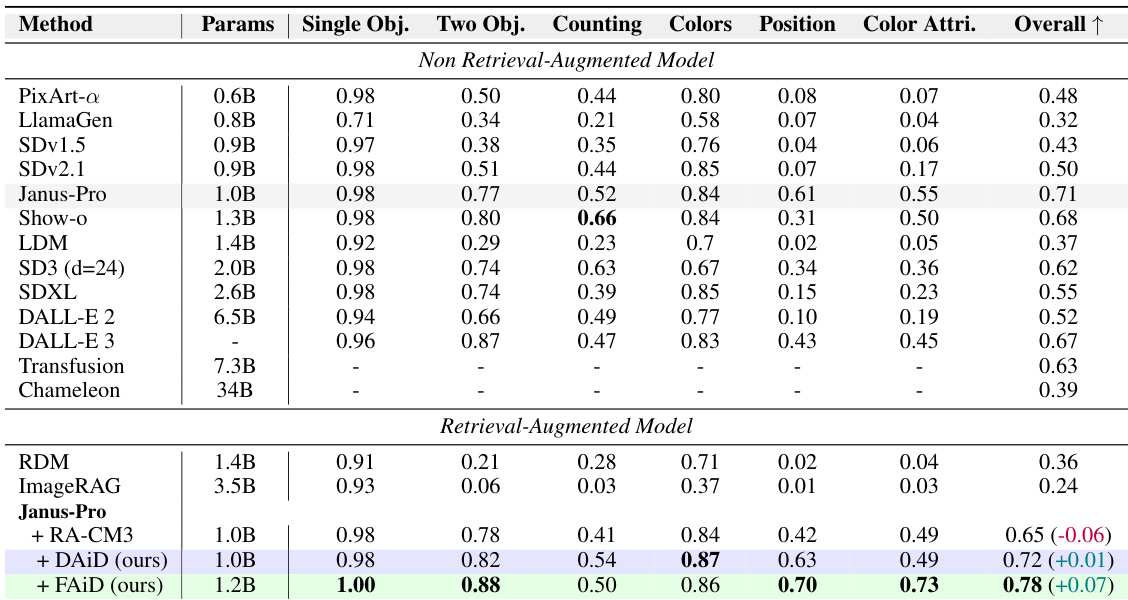
The framework is implemented on Janus-Pro, an autoregressive image generation model that uses a quantized autoencoder to encode images into discrete tokens. The autoencoder consists of an encoder, a decoder, and a codebook, enabling the construction of a retrieval database from the discrete image tokens. The effectiveness of AR-RAG is demonstrated through extensive experiments on benchmarks such as Midjourney-30K, GenEval, and DPG-Bench, showing significant performance gains over state-of-the-art models. Furthermore, the authors show that their methods are generalizable to other models, such as Show-o, by adapting the retrieval mechanisms to accommodate different generation strategies.
Experiment
The evaluation combines multiple generation benchmarks, qualitative visual comparisons, and inference timing tests to validate an autoregressive patch-level retrieval framework. Benchmark and qualitative results demonstrate that dynamically integrating fine-grained visual features during generation significantly improves instruction following and multi-object composition while preventing the overcopying of irrelevant reference elements common in static retrieval methods. Efficiency tests confirm that the approach maintains practical computational overhead relative to its substantial quality improvements. Overall, the framework establishes a robust, architecture-agnostic enhancement that preserves generative flexibility and holistic image fidelity across diverse synthesis tasks.
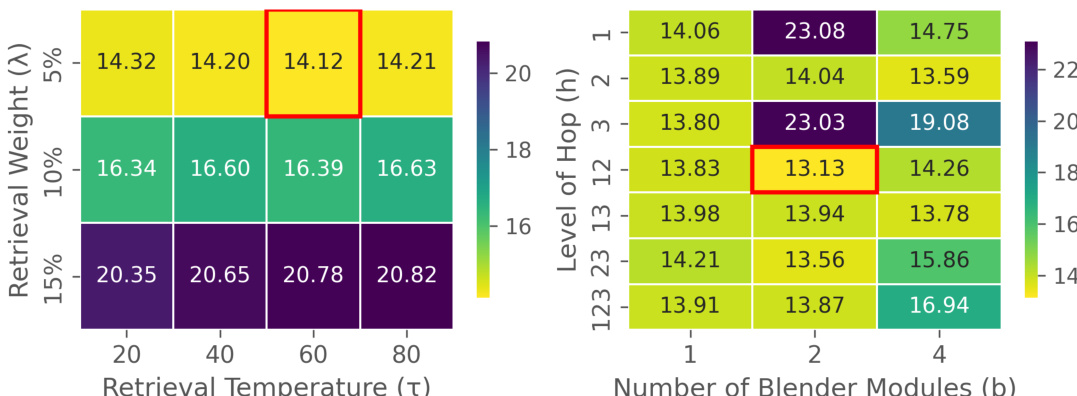
The authors analyze the impact of hyperparameters on the performance of their AR-RAG methods, focusing on retrieval temperature and merging weight for DAiD, and hop level and number of blender modules for FAiD. The results show that optimal configurations involve moderate integration of retrieval information and a balanced combination of retrieval contexts, with specific settings leading to the best performance on the benchmark. These findings support the importance of careful hyperparameter tuning to achieve effective autoregressive patch-level retrieval and refinement. Optimal performance is achieved with moderate integration of retrieval information and balanced hyperparameter settings. Specific configurations of retrieval temperature and merging weight lead to the best results for DAiD. Combining multiple hop levels and an intermediate number of blender modules yields optimal performance for FAiD.
The authors evaluate text-to-image generation methods on multiple benchmarks, comparing retrieval-augmented approaches with non-retrieval baselines. Their proposed methods, based on Janus-Pro, show consistent improvements in overall performance, particularly in categories requiring accurate multi-object generation and spatial arrangement, while maintaining computational efficiency. The results highlight the advantages of autoregressive patch-level retrieval over image-level retrieval, which often leads to overcopying and poor instruction following. The proposed retrieval-augmented methods consistently outperform non-retrieval baselines across multiple benchmarks, with significant gains in multi-object and spatial reasoning tasks. Image-level retrieval methods suffer from overcopying and poor instruction following, whereas the autoregressive patch-level approach enables selective and context-aware integration of visual features. The proposed methods achieve higher quality and coherence with minimal inference time overhead, demonstrating practical efficiency and scalability.
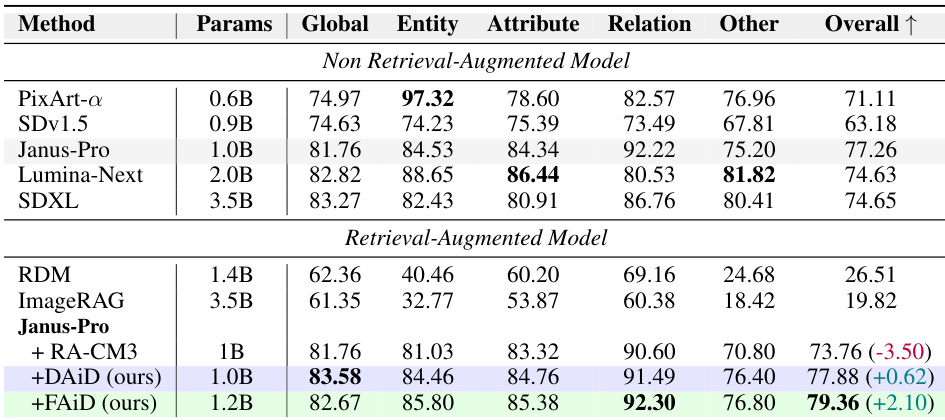
The authors evaluate their autoregressive retrieval-augmented generation methods against existing approaches on multiple benchmarks, showing consistent improvements in text-to-image generation quality. Their methods achieve better results in complex scenarios requiring accurate multi-object arrangements and detailed prompt following, while maintaining computational efficiency. The performance gains are attributed to dynamic, patch-level retrieval that avoids overfitting to irrelevant visual structures in retrieved references. the methods outperform existing retrieval-augmented approaches on benchmarks requiring accurate multi-object generation and spatial arrangement. The autoregressive patch-level retrieval reduces overcopying of irrelevant visual elements and improves instruction following compared to image-level retrieval methods. The proposed methods maintain low inference time overhead while achieving significant improvements in image quality metrics.
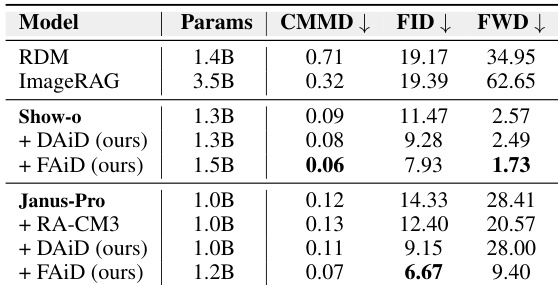
The authors evaluate text-to-image generation models on multiple benchmarks, comparing non-retrieval-augmented and retrieval-augmented approaches. Results show that their proposed AR-RAG methods consistently outperform existing retrieval-augmented models, particularly in tasks requiring accurate multi-object generation and spatial arrangement, with improvements in both category-specific and overall performance metrics. The proposed AR-RAG methods achieve higher performance than existing retrieval-augmented approaches across multiple benchmarks, especially in multi-object and spatial reasoning tasks. AR-RAG methods show significant improvements in categories such as two-object generation and positioning, outperforming non-retrieval and retrieval-augmented baselines. The results demonstrate that autoregressive patch-level retrieval enhances image quality and instruction following, reducing overcopying and improving object consistency compared to image-level retrieval methods.
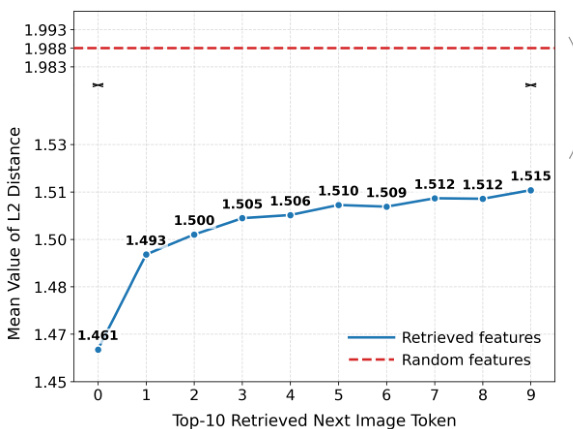
The authors analyze the impact of retrieved features on generation quality by measuring the mean L2 distance between the retrieved features and the next image token across different retrieval ranks. Results show that the mean L2 distance stabilizes quickly after the first few retrieved tokens, indicating that early retrieved features are more informative and contribute more significantly to the generation process compared to later ones. The distance for random features remains consistently higher, suggesting that the retrieved features are more relevant and aligned with the generation context. The trend demonstrates that the quality of retrieved features improves with the retrieval rank initially, then plateaus, highlighting the importance of selecting the most relevant features early in the process. The mean L2 distance stabilizes quickly after the initial retrieval ranks, indicating early retrieved features are more influential. Retrieved features show a lower mean L2 distance compared to random features, suggesting higher relevance and alignment with the generation context. The improvement in feature quality diminishes after the first few retrieval ranks, highlighting the diminishing returns of later retrieved features.
The authors evaluate their autoregressive retrieval-augmented generation framework on multiple text-to-image benchmarks, validating its effectiveness against both non-retrieval and image-level retrieval baselines. Hyperparameter analysis demonstrates that moderate integration strategies and balanced configurations are essential for optimal performance, while feature relevance studies confirm that early retrieval ranks yield the most informative and context-aligned visual cues. Collectively, these experiments reveal that patch-level retrieval significantly enhances multi-object composition and spatial reasoning by minimizing irrelevant overcopying and improving instruction adherence. The approach consistently delivers higher generation quality and coherence while maintaining practical computational efficiency.