Command Palette
Search for a command to run...
One-click Deployment of Music Generation Foundation Model ACE-Step
Abstract
One-sentence Summary
ACE-Step is an open-source music generation foundation model that integrates diffusion-based synthesis with Sana’s Deep Compression AutoEncoder and a lightweight linear transformer, leveraging MERT and m-hubert for semantic alignment to generate up to four minutes of music in twenty seconds on an A100 GPU, delivering a 15× speedup over LLM-based baselines while achieving superior musical coherence and lyric alignment across melody, harmony, and rhythm metrics.
Key Contributions
- This work introduces ACE-Step, an open-source foundation model for music generation that addresses the inherent trade-offs between inference speed, structural coherence, and controllability.
- The architecture integrates a diffusion-based generator with a Deep Compression AutoEncoder and a lightweight linear transformer, while leveraging semantic representation alignment to accelerate training convergence and preserve fine-grained acoustic details.
- Evaluations demonstrate that the model synthesizes up to four minutes of audio in twenty seconds on an A100 GPU, achieving inference speeds fifteen times faster than LLM-based baselines while attaining state-of-the-art performance across melody, harmony, rhythm, and lyric alignment metrics.
Introduction
Text-to-music generation presents a unique challenge in AI due to the complex interplay of melody, harmony, rhythm, and precise lyric alignment. While commercial platforms have progressed quickly, open-source models continue to struggle with balancing generation speed, long-range structural coherence, and fine-grained controllability. Two-stage autoregressive approaches often suffer from slow inference and error propagation, whereas latent diffusion methods frequently lack musical consistency and flexible conditioning. To address these limitations, the authors leverage a Deep Compression AutoEncoder integrated with a flow-matching process driven by a lightweight linear transformer. They further incorporate representation alignment using pre-trained MERT and mHuBERT encoders to accelerate training convergence and enforce strict semantic and lyrical fidelity. This architectural design enables the synthesis of multi-minute tracks in seconds while supporting advanced creative controls like lyric editing and voice cloning, establishing a fast and extensible foundation for next-generation music AI applications.
Dataset

-
Dataset Composition and Sources: The authors construct a large-scale audio corpus containing approximately 1.8 million unique musical pieces, totaling roughly 100,000 hours of audio. The collection spans 19 languages, with English representing the dominant portion.
-
Key Details and Filtering Rules: To maintain strict audio quality, the team processes the entire corpus through the Audiobox aesthetics toolkit. This automated quality control pipeline systematically identifies and removes low-fidelity recordings and live performances, effectively eliminating tracks prone to unwanted acoustic artifacts.
-
Metadata Construction and Annotation: The dataset is enriched with multi-modal conditioning signals to guide model generation. Descriptive captions capturing musical content and mood are generated using Qwen-omini. Vocal tracks are transcribed via Whisper 3.0, then aligned to canonical lyric databases using a locality-sensitive hashing approach that maps International Phonetic Alphabet representations. Structural segmentation identifies song sections like verses and choruses through a dedicated music understanding model. Rhythm and tonal features, including beats per minute and musical key, are extracted with Beatthis and Essentia, then standardized into consistent natural language phrases by Qwen-omini.
-
Data Usage and Processing Pipeline: This curated collection serves as the primary training corpus for the ACE-Step model. The authors integrate the cleaned audio with the generated metadata to provide rich conditioning signals during the training phase. While exact training splits and mixture ratios are not detailed in the provided sections, the complete preprocessing workflow ensures the model receives consistently formatted, artifact-free, and semantically structured audio-text pairs for robust optimization.
Method
The ACE-Step model is designed as a fast, general-purpose, and flexible foundation model for music generation, adopting a diffusion-based generation paradigm inspired by successful text-to-image frameworks. The overall framework integrates efficient architectural choices and advanced semantic alignment techniques to achieve high-quality, controllable audio synthesis. As shown in the figure below, the model operates on a compressed mel-spectrogram latent representation, with the core generative process guided by conditioning information from three specialized encoders: a text prompt encoder, a lyric encoder, and a speaker encoder. These embeddings are concatenated and integrated into the diffusion model via cross-attention mechanisms, enabling fine-grained control over the generated output.
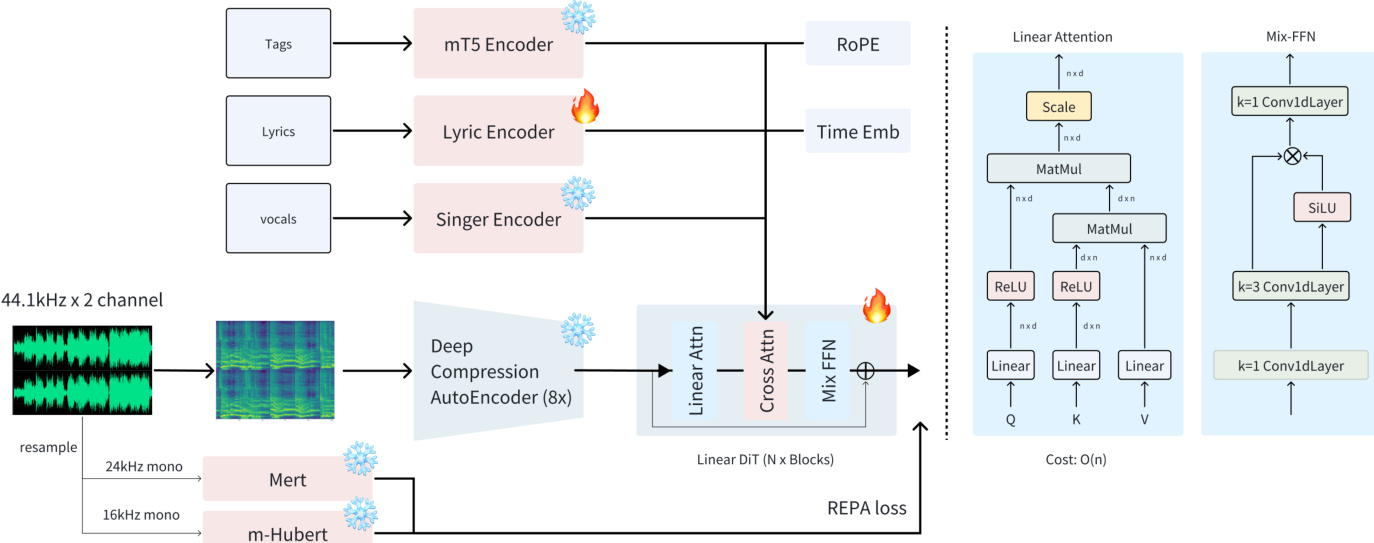
The audio representation pipeline begins with a Deep Compression AutoEncoder (DCAE), which compresses the input audio into a latent space. The DCAE is configured with an 8x compression setting (f8c8, channel=8), achieving a temporal resolution of approximately 10.77Hz, which provides a superior balance between compression ratio and fidelity compared to higher compression settings. The generated mel-spectrograms are then converted back to waveform using a pre-trained universal music vocoder from Fish Audio. The core denoising network is a Linear Diffusion Transformer (DiT), adapted from Sana, with two key modifications: a simplified adaptive layer normalization using AdaLN-single to reduce model size and memory consumption, and the replacement of 2D convolutional feedforward layers with 1D convolutions to better align with the sequential nature of audio data.
The conditioning encoders play a crucial role in guiding the generation process. The text encoder employs a frozen Google mT5-base model to generate 768-dimensional embeddings from textual prompts, leveraging its robust multilingual capabilities. The lyric encoder, adopted from SongGen, is trainable during training and processes lyrics using the XTTS VoiceBPE tokenizer, with non-Romanized scripts converted to phonemic representations via grapheme-to-phoneme tools. The speaker encoder processes 10-second unaccompanied vocal segments to produce 512-dimensional embeddings, with a zero vector used for instrumental tracks. During training, a 50% dropout rate is applied to speaker embeddings to prevent over-reliance on timbre information, enhancing stylistic control.
Training is conducted by optimizing a composite objective function that balances generative fidelity with semantic coherence. The primary loss is a continuous-time flow matching (FM) objective, which learns the data distribution in the latent space by predicting the negative of the constant velocity field associated with the linear path from noise to the target data distribution. This is implemented using a mean squared error between the reconstructed prediction and the ground truth latent representation. An auxiliary semantic alignment loss is also incorporated, inspired by the Representation Alignment (REPA) framework, to constrain intermediate representations from the Linear DiT backbone to align with those from pre-trained audio SSL models, such as MERT and mHuBERT. This ensures robust lyric adherence and musical coherence, particularly in the alignment of sung lyrics.
Experiment
The evaluation combined blind human listening assessments with comprehensive automatic benchmarks to validate waveform reconstruction fidelity, stylistic and lyrical alignment, perceptual musicality, and generation efficiency across multiple music generation models. While automatic metrics revealed a notable divergence from subjective human preferences due to inherent perceptual variability and current benchmark limitations, ACE-Step consistently demonstrated superior genre fidelity, musical coherence, and generation speed among open-source alternatives. The text-only evaluation protocol further confirmed its robust multilingual capabilities and practical efficiency, positioning it as a leading open-source solution while underscoring the need for more perceptually aligned evaluation frameworks in music AI research.
The authors compare the waveform reconstruction performance of Music DCAE and DiffRhythm's VAE using FAD and Audiobox-aesthetics scores. Music DCAE achieves lower FAD scores, indicating better reconstruction quality, while DiffRhythm VAE shows higher scores in some Audiobox-aesthetics dimensions, suggesting better audio quality in specific aspects. Music DCAE achieves lower FAD scores than DiffRhythm VAE, indicating superior waveform reconstruction quality. DiffRhythm VAE outperforms Music DCAE in some Audiobox-aesthetics dimensions, suggesting better audio quality in specific aspects. Music DCAE demonstrates better reconstruction performance across different audio conditions, while DiffRhythm VAE shows higher scores in certain quality metrics.

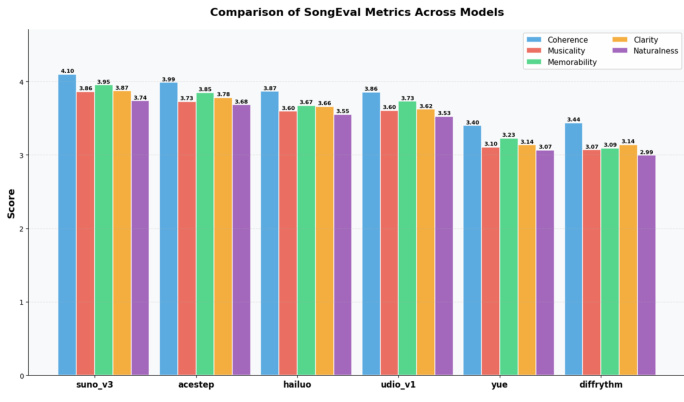
The authors evaluate ACE-Step's performance in music generation using both human and automatic metrics, comparing it to several baseline models. Results show that ACE-Step achieves strong scores across multiple SongEval dimensions, particularly in coherence and memorability, and performs competitively with other models in terms of musicality and overall quality. The evaluation highlights differences between subjective human judgments and objective metrics, with SongEval demonstrating greater alignment with human perception. ACE-Step achieves high scores in coherence and memorability according to SongEval metrics, outperforming other models in these dimensions. ACE-Step demonstrates competitive performance in musicality and overall quality, ranking among the top models in automatic evaluations. The study reveals a divergence between human evaluations and objective metrics, with SongEval showing stronger alignment to human perception compared to other automated assessments.
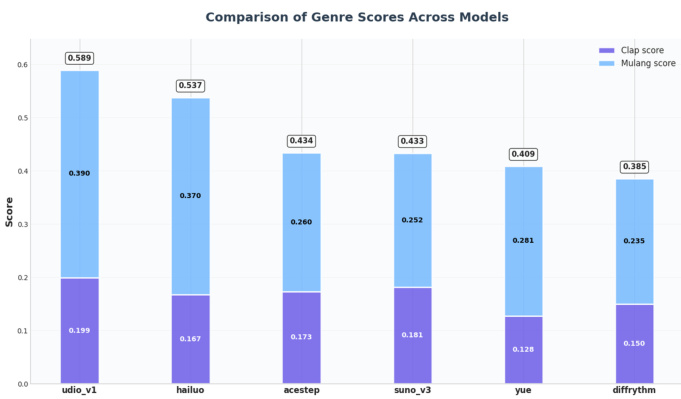
The authors compare ACE-Step with several baseline models across multiple evaluation metrics, including genre and lyric alignment, aesthetic quality, and musicality. Results show that ACE-Step achieves competitive performance in musicality and genre fidelity, particularly excelling in style alignment and generation speed, while other models exhibit strengths in specific areas such as lyric alignment or aesthetic scores. ACE-Step demonstrates strong performance in genre alignment, outperforming several baselines in both CLAP and Mulan scores. ACE-Step achieves high generation speed, significantly surpassing other models in real-time factor. While ACE-Step shows competitive results in musicality, other models like DiffRhythm achieve higher lyric alignment due to architectural differences.
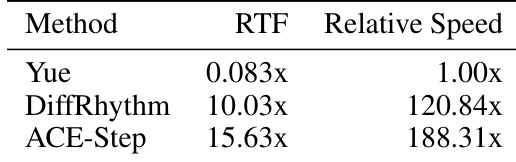
The authors compare the generation speed of ACE-Step, DiffRhythm, and Yue using the Real-Time Factor (RTF) on an RTX 4090 GPU, showing that ACE-Step achieves the highest speed, significantly outperforming the other two models. The results indicate that ACE-Step is substantially faster than Yue and also faster than DiffRhythm, with relative speed improvements of 188x and 120x respectively. These findings suggest that ACE-Step maintains high efficiency despite its larger model size and multilingual capabilities. ACE-Step achieves the highest generation speed among the compared models. ACE-Step is significantly faster than Yue, which is the slowest model. ACE-Step is also faster than DiffRhythm, despite having a larger model size.
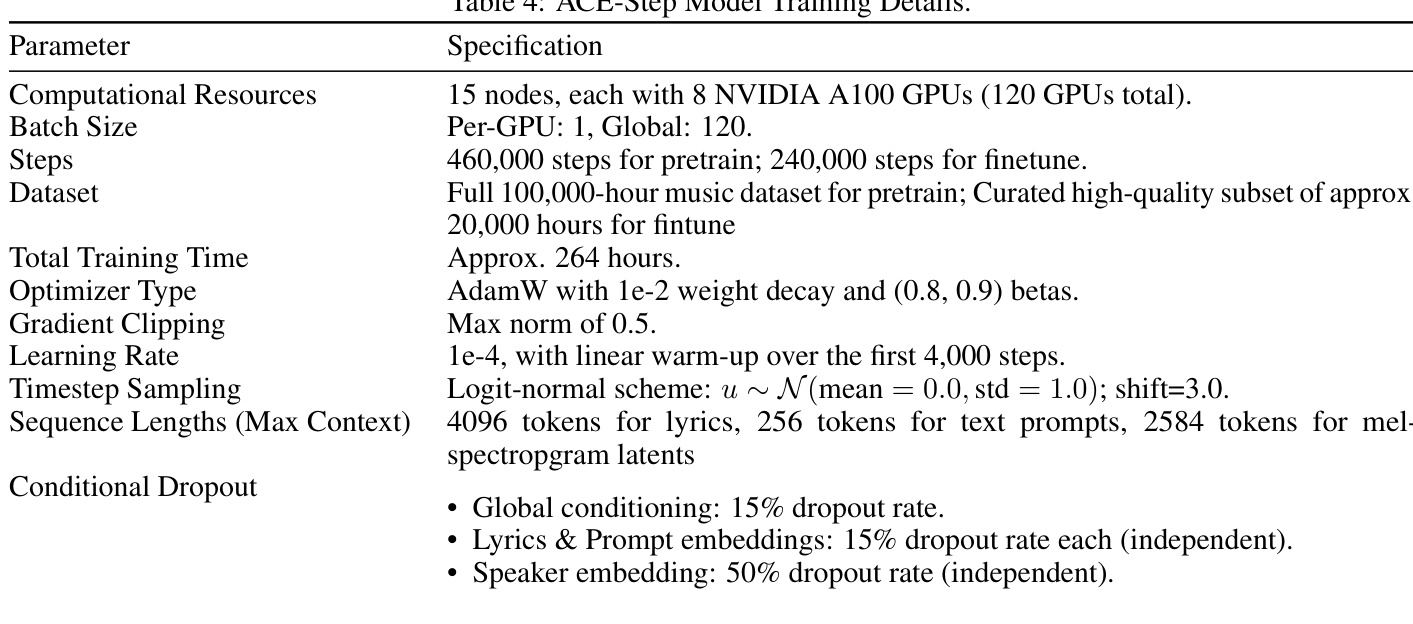
The authors conducted experiments to evaluate the ACE-Step model, focusing on its performance in music generation through both human and automatic evaluations. The training process involved extensive computational resources and specific configurations, with results showing competitive performance in musicality and speed compared to other models. The evaluation highlights a gap between subjective human judgments and objective metrics, emphasizing the need for more perceptually aligned evaluation methods. ACE-Step achieves strong performance in musicality and emotional expression in human evaluations, outperforming several baselines. The model demonstrates superior generation speed compared to other open-source alternatives, enabling near-real-time audio production. Automatic metrics reveal discrepancies between objective scores and human perception, with SongEval showing better alignment to human judgments than other metrics.
The experiments assess waveform reconstruction and music generation performance across several models through comparative automatic and human evaluations. The reconstruction analysis validates that Music DCAE provides more consistent waveform fidelity across varying audio conditions, whereas DiffRhythm VAE demonstrates strengths in particular aesthetic dimensions. The generation benchmarks validate ACE-Step's superior coherence, genre alignment, and computational efficiency, showing it maintains high quality while significantly outpacing other architectures. Collectively, these evaluations reveal a persistent gap between automated scoring and human perception, emphasizing the importance of developing more perceptually aligned assessment methods for music synthesis.