Command Palette
Search for a command to run...
SketchAgent: Language-Driven Sequential Sketch Generation
SketchAgent: Language-Driven Sequential Sketch Generation
Yael Vinker Tamar Rott Shaham Kristine Zheng Alex Zhao Judith E Fan Antonio Torralba
One-click Deployment of Pencil Sketch Text-to-Image Generation (shouxin)
Abstract
Sketching serves as a versatile tool for externalizing ideas, enabling rapid exploration and visual communication that spans various disciplines. While artificial systems have driven substantial advances in content creation and human-computer interaction, capturing the dynamic and abstract nature of human sketching remains challenging. In this work, we introduce SketchAgent, a language-driven, sequential sketch generation method that enables users to create, modify, and refine sketches through dynamic, conversational interactions. Our approach requires no training or fine-tuning. Instead, we leverage the sequential nature and rich prior knowledge of off-the-shelf multimodal large language models (LLMs). We present an intuitive sketching language, introduced to the model through in-context examples, enabling it to "draw" using string-based actions. These are processed into vector graphics and then rendered to create a sketch on a pixel canvas, which can be accessed again for further tasks. By drawing stroke by stroke, our agent captures the evolving, dynamic qualities intrinsic to sketching. We demonstrate that SketchAgent can generate sketches from diverse prompts, engage in dialogue-driven drawing, and collaborate meaningfully with human users.
One-sentence Summary
The authors introduce SketchAgent, a training-free, language-driven sequential sketching system that leverages off-the-shelf multimodal LLMs and an in-context sketching language to process string-based actions into vector graphics rendered on a pixel canvas, demonstrating across diverse prompts and dialogue-driven interactions that users can generate, modify, and refine drawings stroke by stroke while capturing the dynamic nature of human sketching.
Key Contributions
- Introduces SketchAgent, a training-free framework that leverages off-the-shelf multimodal large language models to generate sketches sequentially. The system translates an in-context sketching language into string-based commands to render vector graphics stroke-by-stroke on a pixel canvas.
- Establishes a conversational interaction paradigm that enables users to iteratively create, modify, and refine visuals through natural language prompts. Each dialogue turn triggers a discrete drawing action that facilitates adaptive human-machine collaboration without requiring model fine-tuning.
- Demonstrates through qualitative evaluations that the generated sketches capture spontaneous drawing qualities while avoiding the rigid appearance of standard code-based or pixel-space methods. The system successfully processes diverse textual prompts and supports real-time, dialogue-driven drawing sessions.
Introduction
Sketching is a foundational method for rapid ideation, cross-disciplinary communication, and visual problem-solving, positioning AI-assisted sketching as a powerful tool for augmenting human creativity. Existing generative approaches either depend on limited human-drawn datasets or rely on vision-language models that optimize all strokes simultaneously, stripping sketches of the iterative, stroke-by-stroke progression that mirrors human drawing. Furthermore, prompting large language models to output vector code typically yields rigid, mechanically precise visuals that lack spontaneous freehand qualities and struggle with fine-grained spatial editing. To address these gaps, the authors leverage an off-the-shelf multimodal LLM to create SketchAgent, a sequential sketching system guided by a custom spatial language and a coordinate-based grid canvas. By integrating in-context learning and chain-of-thought prompting, the agent generates natural-looking, semantically structured stroke sequences that support real-time collaborative refinement without requiring additional model training.
Dataset
-
Dataset Composition and Sources: The authors compile a sketch dataset sourced from a controlled web-based study and an automated generation pipeline. It contains three primary categories: human-only sketches, AI-generated sketches produced by SketchAgent, and collaborative sketches created through human-agent interaction.
-
Key Details for Each Subset:
- Human (Solo): Each participant completes 10 sketches, consisting of two warm-up concepts and eight primary concepts presented in randomized order.
- Collaborative: Users and the agent alternate adding strokes to a shared canvas, with human strokes rendered in green and agent strokes in pink.
- AI/Quantitative: Contains 10 randomly generated sketches per evaluation category used for benchmarking performance.
-
Data Usage and Training: The authors use the dataset to train SketchAgent, supply in-context learning examples, and run quantitative evaluations. The system prompt instructs the model to break down complex concepts into sequential strokes, while user prompts define the target concept and expected output format. The data directly supports both automated benchmarking and human-subject collaboration studies.
-
Processing and Metadata Construction: All sketches are mapped to a 400 by 400 pixel canvas and converted into a normalized grid coordinate system. Each stroke is parameterized as a Bezier curve defined by a starting point, an ending point, at least two intermediate waypoints, and corresponding t-values ranging from 0 to 1 to control path curvature. Complex objects are systematically decomposed into multiple connected strokes, and concept sequences are randomized per session to eliminate ordering bias.
Method
The authors leverage a language-driven, sequential sketch generation framework that enables dynamic, conversational interactions without requiring training or fine-tuning. At the core of the method is a frozen multimodal large language model (LLM), referred to as SketchAgent, which operates on a structured pipeline to generate sketches from natural language instructions. The overall architecture is illustrated in the framework diagram, where the agent processes a system prompt, a user prompt, and a blank canvas to produce a sequence of drawing actions. The system prompt provides the agent with contextual instructions, including its role as an expert artist and an introduction to the sketching language and grid-based canvas. The user prompt specifies the desired task, such as "draw a shark," and includes an in-context example of a simple sketch to ensure the output adheres to the required format.
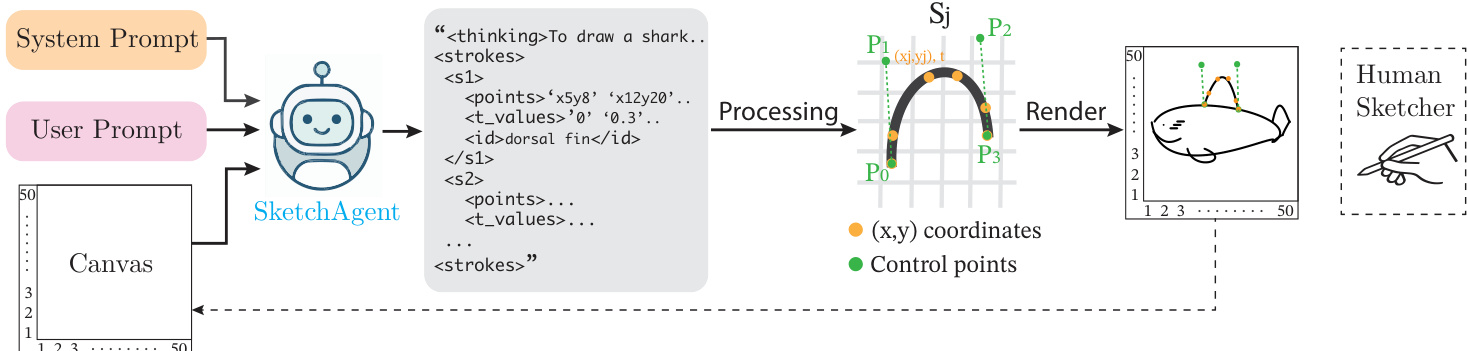
The canvas is designed as a 50×50 grid, with each cell uniquely identified by a coordinate pair (x,y), enabling the agent to interact with the environment through spatially grounded actions. This grid-based representation addresses the spatial reasoning limitations of multimodal LLMs, which often fail to translate visual understanding into precise coordinate-based drawing commands. The agent responds by generating a textual sequence of strokes, each defined as a sequence of (x,y) coordinates on the grid, formatted as <points>x1y1, x15y20, ...</points>.
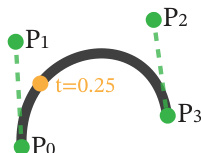
To ensure smooth and natural-looking sketches, the system processes the agent's coordinate sequence by fitting cubic Bézier curves to the sampled points. Each stroke is represented as a set of m sampled points along the curve, accompanied by corresponding t values that define the parameterization of the curve. The control points of the Bézier curve are determined by solving a least squares optimization problem that minimizes the error between the fitted curve and the sampled points. The optimization objective is expressed as:
P=argminP∣∣AP−B∣∣where A∈Rm×4 contains the cubic Bézier basis functions evaluated at the specified tj values, and B∈Rm×2 contains the sampled (xj,yj) coordinates. For sequences with high fitting error, the curve is recursively split. The method also supports lower-degree curves, including quadratic and linear segments, to accommodate various stroke types. The resulting parametric curves are rendered onto the canvas using SVG, producing a vector-based sketch.
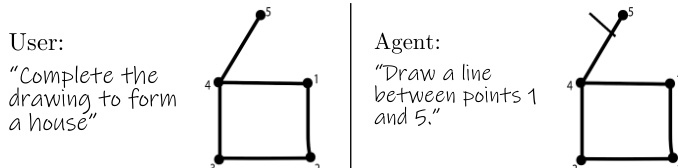
The framework supports iterative and collaborative sketching. After generating a sequence of strokes, the rendered canvas can be fed back into the model with an updated user prompt to enable editing. The process incorporates a stopping token, </s{j}>, which allows the agent to pause at a specified stroke, enabling human intervention. User-drawn strokes are processed by sampling them at multiple t values and converting them into the agent's coordinate format, which are then appended to the agent's sequence for continuation. This bidirectional interaction facilitates a seamless human-agent collaboration, where the agent and human co-create sketches through a conversational interface.
Experiment
The evaluation setup encompasses text-conditioned generation, sequential stroke-by-stroke drawing, interactive human-agent collaboration, and chat-based editing tasks. These experiments validate that the agent produces fluid, semantically annotated sketches that closely emulate human drawing progression, successfully execute spatial reasoning during iterative editing, and yield collaborative outputs that match solo human recognition rates. Qualitatively, the method consistently outperforms rigid direct-prompting baselines by generating natural, expressive strokes while maintaining logical structural coherence. Overall, the findings demonstrate that leveraging multimodal LLM priors enables highly adaptable, interactive sketching systems capable of both independent generation and meaningful human collaboration, despite current limitations with highly complex or abstract concepts.
The authors analyze the performance of their method in generating sketches across various categories, comparing recognition accuracy and human-likeness against different models and baselines. Results show that the proposed method achieves high recognition rates, with performance approaching that of human-drawn sketches, and generates sketches that are perceived as more human-like than direct prompting methods. The method also demonstrates robustness in collaborative sketching, where both human and agent contributions are essential for achieving high recognizability. The method achieves high sketch recognition accuracy, approaching human-level performance on a diverse set of categories. Sketches generated by the method are perceived as more human-like compared to those from direct prompting, as shown in a user study. Collaborative sketching results show that both human and agent contributions are crucial for creating recognizable sketches.
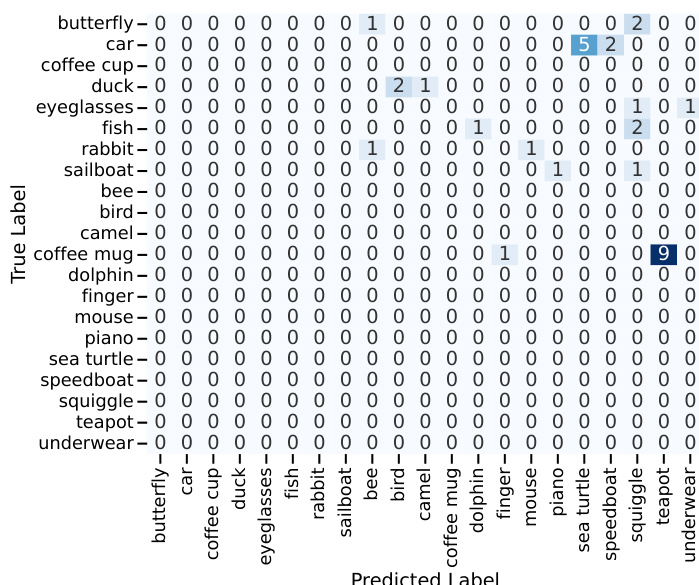
The authors evaluate the performance of their sketch generation method by comparing it to human sketches and other models using a CLIP zero-shot classifier. Results show that the method produces sketches with high recognition accuracy, approaching human-level performance, and that the generated sketches are perceived as more human-like than those from direct prompting. The method also enables collaborative sketching, where both human and agent contributions are essential for creating recognizable sketches. The method achieves high sketch recognition accuracy, approaching human-level performance with the best-performing model. Generated sketches are perceived as more human-like compared to those from direct prompting, with users preferring them in a two-alternative forced choice study. Collaborative sketching results show that both human and agent contributions are necessary for producing recognizable sketches.
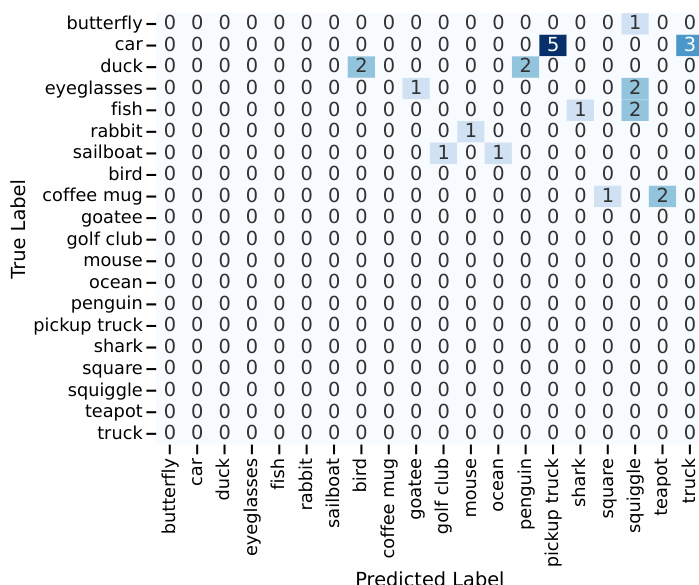
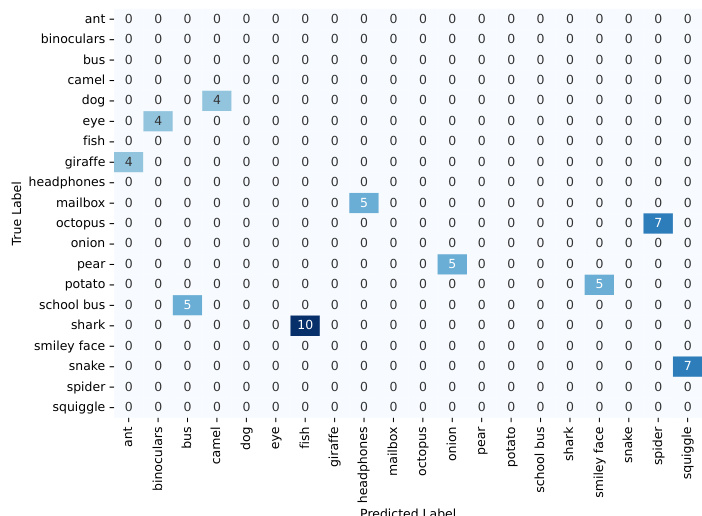
The authors analyze the performance of their method in generating sketches across various categories, comparing recognition accuracy and human-like qualities. Results show that the method achieves high recognition rates, particularly with its default model, and produces sketches that are more human-like than direct prompting approaches. The sketches exhibit a gradual, meaningful stroke-by-stroke evolution, similar to human drawing processes. The method achieves high recognition accuracy, with its default model outperforming other models and approaching human-level performance. Sketches generated by the method are perceived as more human-like compared to those from direct prompting, though still slightly less so than actual human sketches. The sketching process is sequential and meaningful, with each stroke contributing to the evolving recognition of the concept, similar to human drawing behavior.
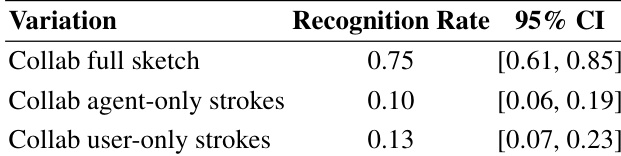
The experiment evaluates collaborative sketching between users and an agent, comparing recognition rates of full collaborative sketches to partial sketches consisting of only agent-generated or user-generated strokes. Results show that full collaborative sketches achieve high recognition rates, significantly higher than those of partial sketches, indicating that both the user and the agent contribute essential information for recognizability. The recognition rates for partial sketches are low and similar, suggesting that neither party alone can produce a recognizable sketch. Collaborative sketches achieve high recognition rates compared to partial sketches. Partial sketches generated by either the agent or the user alone have low recognition rates. Both user and agent contributions are necessary for producing recognizable collaborative sketches.
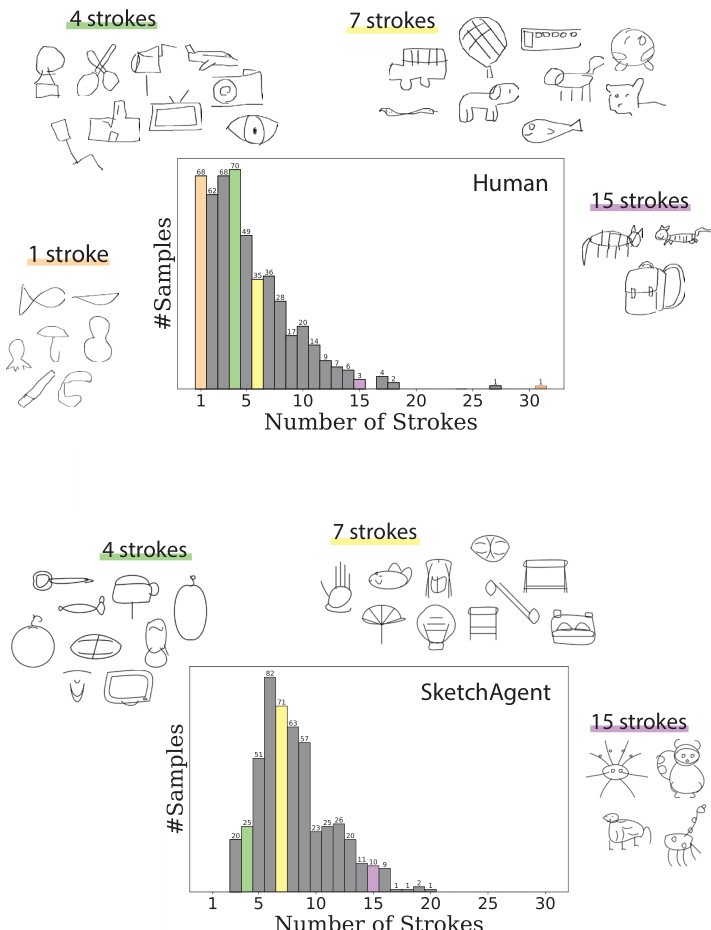
The experiment compares the number of strokes in human-generated sketches from the QuickDraw dataset with those generated by SketchAgent. The results show that human sketches tend to have fewer strokes, with a peak at one stroke, while SketchAgent's sketches have a broader distribution, peaking at five strokes and extending to higher stroke counts. Visual examples illustrate that human sketches often use single, continuous lines, whereas SketchAgent's sketches are composed of multiple strokes and exhibit a more varied structure. Human sketches predominantly use a single stroke, while SketchAgent's sketches use more strokes and show a broader distribution. SketchAgent's sketches peak at five strokes, indicating a higher average stroke count compared to human sketches. Human sketches often consist of a single continuous line, whereas SketchAgent's sketches are composed of multiple distinct strokes.
The evaluation compares the proposed sketch generation method against human drawings and baseline models using recognition accuracy and human-likeness assessments, alongside a collaborative sketching setup and stroke count analysis. Results demonstrate that the method produces highly recognizable sketches that closely approach human-level performance and are perceived as more natural than direct prompting approaches. The experiments further validate that successful collaborative sketching requires meaningful contributions from both users and the agent, as partial inputs fail to achieve clear recognition. Additionally, the sequential stroke generation process mirrors human drawing progression, though the agent typically employs a broader distribution of strokes compared to the concise single-stroke habits of human artists.