Command Palette
Search for a command to run...
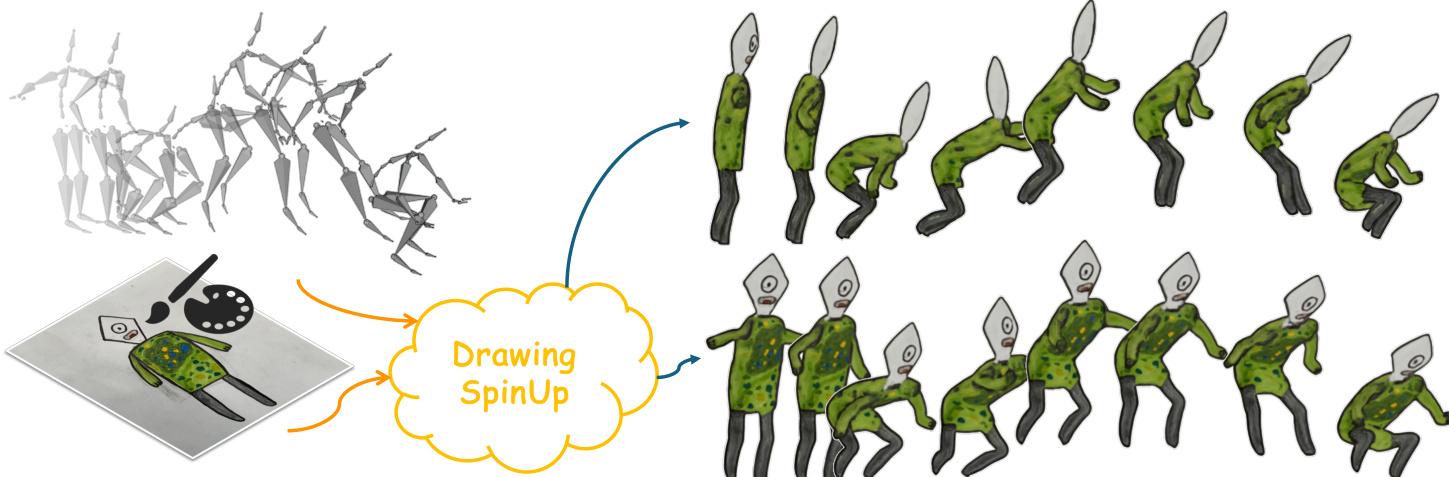
DrawingSpinUp: 3D Animation from Single Character Drawings
DrawingSpinUp: 3D Animation from Single Character Drawings
Jie Zhou Chufeng Xiao Miu-Ling Lam Hongbo Fu
One-click Deployment of DrawingSpinUp: 2D Character Drawing to 3D Animation
Abstract
Animating various character drawings is an engaging visual content creation task. Given a single character drawing, existing animation methods are limited to flat 2D motions and thus lack 3D effects. An alternative solution is to reconstruct a 3D model from a character drawing as a proxy and then retarget 3D motion data onto it. However, the existing image-to-3D methods could not work well for amateur character drawings in terms of appearance and geometry. We observe the contour lines, commonly existing in character drawings, would introduce significant ambiguity in texture synthesis due to their view-dependence. Additionally, thin regions represented by single-line contours are difficult to reconstruct (e.g., slim limbs of a stick figure) due to their delicate structures. To address these issues, we propose a novel system, DrawingSpinUp, to produce plausible 3D animations and breathe life into character drawings, allowing them to freely spin up, leap, and even perform a hip-hop dance. For appearance improvement, we adopt a removal-then-restoration strategy to first remove the view-dependent contour lines and then render them back after retargeting the reconstructed character. For geometry refinement, we develop a skeleton-based thinning deformation algorithm to refine the slim structures represented by the single-line contours. The experimental evaluations and a perceptual user study show that our proposed method outperforms the existing 2D and 3D animation methods and generates high-quality 3D animations from a single character drawing.
One-sentence Summary
DrawingSpinUp generates high-quality 3D animations from single character drawings by employing a removal-then-restoration strategy to resolve view-dependent contour ambiguities and a skeleton-based thinning deformation algorithm to refine delicate structures, with experimental evaluations and perceptual user studies confirming its superior performance over existing 2D and 3D animation methods.
Key Contributions
- DrawingSpinUp explicitly reconstructs a 3D model from a single character drawing to enable free-viewpoint motion retargeting, overcoming the flat 2D constraints of prior animation approaches.
- A removal-then-restoration strategy eliminates view-dependent contour lines prior to texture synthesis, while a skeleton-based thinning deformation algorithm refines delicate single-line structures.
- Comprehensive experiments and a perceptual user study demonstrate that the proposed pipeline generates high-quality 3D animations from amateur character drawings, surpassing existing 2D and 3D animation methods.
Introduction
The authors address the creative challenge of animating single character drawings by converting static sketches into dynamic 3D models capable of complex movements. Bringing hand-drawn characters to life holds significant value for digital storytelling, gaming, and interactive media, yet existing techniques struggle to deliver convincing results. Two-dimensional deformation methods restrict characters to flat, planar motions and lack spatial depth, while modern image-to-3D reconstruction models fail to handle amateur sketches due to a domain gap with photo-realistic training data. These models frequently misinterpret view-dependent contour lines as internal textures and cannot accurately reconstruct delicate single-line structures like thin limbs. To overcome these limitations, the authors introduce DrawingSpinUp, a novel pipeline that temporarily removes contour lines to enable robust 3D geometry reconstruction, applies a skeleton-based thinning algorithm to preserve slender anatomical features, and finally restores the stylized lines during motion retargeting. This approach successfully bridges the gap between amateur sketches and immersive 3D animation.
Method
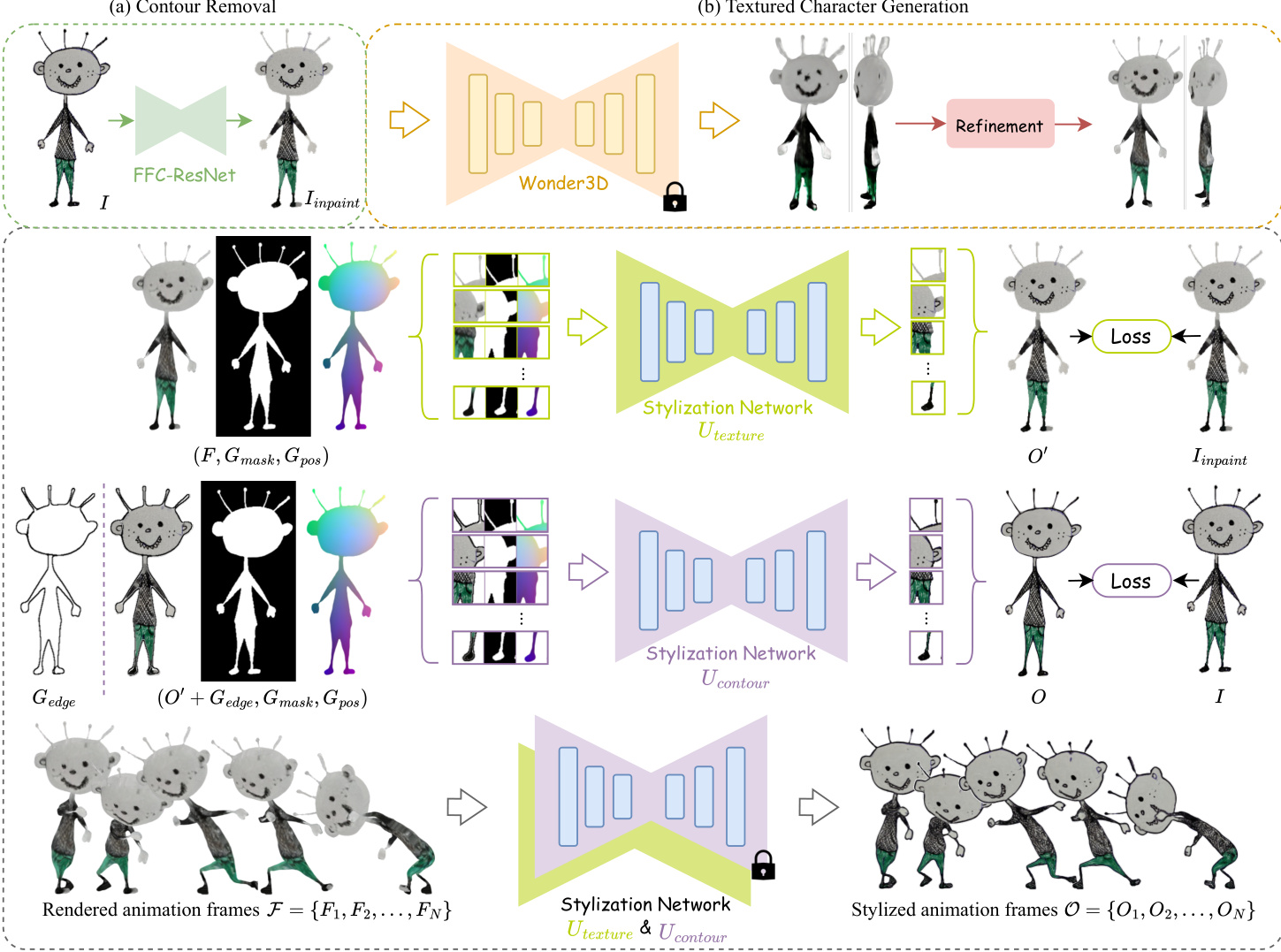
The authors propose a comprehensive framework, DrawingSpinUp, designed to generate 3D animations from a single character drawing by applying target 3D motions while preserving the original artistic style. The pipeline is structured into distinct stages, beginning with the removal of view-dependent contour lines to prevent interference with 3D reconstruction, followed by the generation and refinement of a textured 3D character model, and concluding with the restoration of the original drawing style to the animated sequence. The overall process is illustrated in Fig. 4, which shows the transition from a static drawing to a dynamic, stylized animation.
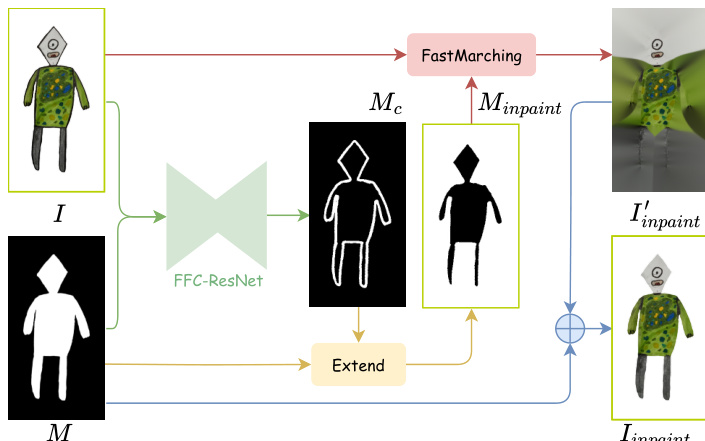
The first stage involves contour removal to create a contour-free input for 3D reconstruction. The authors frame this task as an image-to-image translation problem, where an FFC-ResNet is employed to predict a contour mask Mc from the input drawing I and its foreground mask M. This network is chosen for its ability to capture long-range dependencies due to the large receptive field of Fast Fourier Convolution, which is beneficial for accurately identifying object boundaries. Once the contour mask is predicted, the original contour lines are removed by inpainting the masked region. To ensure the inpainting is not influenced by the background color, the inpainting region mask Minpaint is defined as the union of the predicted contour mask and the background region, i.e., Minpaint=Mc∪(1−M). The inpainting is performed using a fast marching method, which replaces each pixel in the masked region with a normalized weighted sum of its neighbors in the non-masked area. This process results in an inpainted drawing Iinpaint that retains the interior texture but lacks the original contour lines. The detailed process is shown in Fig. 5.
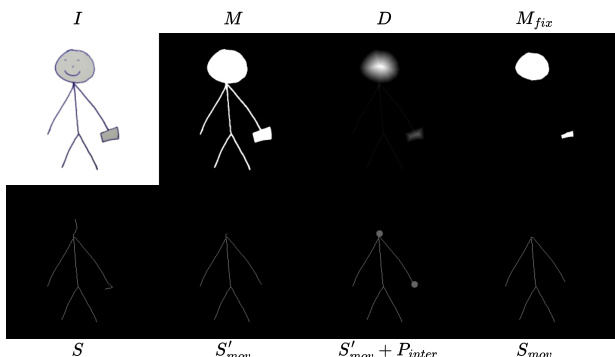
Following contour removal, the system generates a coarse 3D character model. It leverages a pre-trained diffusion model, Wonder3D, to produce multi-view normal maps and color images from the contour-free drawing. These 2D representations are then fed into a neural surface reconstructor, Instant-NSR, to create a textured geometry. However, the initial reconstruction often suffers from geometric artifacts, such as thickened thin structures and surface adhesion, as illustrated in Fig. 6, and blurry textures. To address these issues, a multi-step refinement process is applied. First, a shape cutting operation is performed by intersecting the reconstructed geometry with the front-view mask M to trim the silhouette to the correct front view, as defined by the 0-level set of the signed distance function (SDF). This step, shown in Fig. 8 (e), corrects the silhouette but does not address side thickness. To reduce the thickness of side structures, a skeleton-based thinning deformation algorithm is developed. This algorithm treats the problem as a bi-harmonic deformation, where the deformation field d is computed using a Laplacian operator based on known displacements at handle vertices. The handle vertices are determined by extracting a distance map D and a skeleton S from the foreground mask M. Vertices are classified as fixed (Pfix) or move-needed (Pmov) based on their distance from the skeleton and a distance threshold. The displacement for move-needed vertices is derived from the distance map, and the deformation is applied. This process, illustrated in Fig. 7, allows for the thinning of features like hair and limbs without altering the front silhouette. After thinning, Laplacian smoothing is applied to handle sharp edges. To improve texture quality, a color back-projection technique is used, where multi-view color images are projected onto the 3D model to recolor each vertex, as shown in Fig. 8 (g).
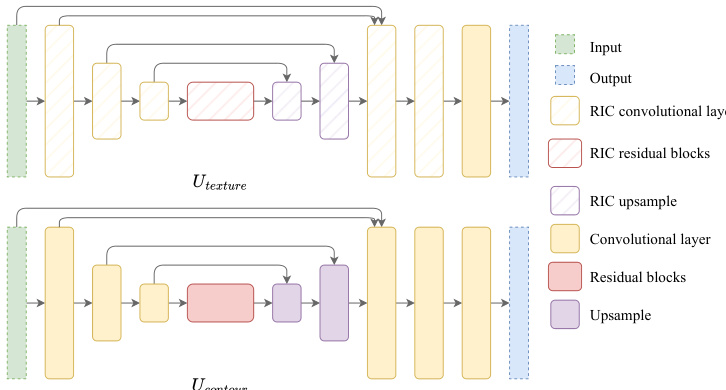
The final stage of the pipeline is stylized contour restoration, which aims to transfer the original drawing style back onto the animated sequence. This is achieved through a two-stage, geometry-aware stylization network. The network consists of two cascaded modified U-Nets, Utexture and Ucontour, as illustrated in Fig. 9. The first U-Net, Utexture, restores internal texture details, while the second, Ucontour, focuses on restoring external contour lines. To enhance stability under motion, all convolutional layers in Utexture (except the final layer) are replaced with rotation-invariant coordinate (RIC) convolutions. The network is trained in a patch-based manner, using small k×k patches from the guidance channels and ground truth to learn the stylization task. The inputs to the stylization network are designed to maintain multi-view consistency. For each animation frame F, the network takes the original color frame, the foreground mask Gmask, a positional hint Gpos derived from the character's rest posture coordinates, and an edge map Gedge extracted from the Z-depth using the Canny detector. The first U-Net Utexture takes (F,Gmask,Gpos) to generate a middle stylized frame O′. Then, the edge map Gedge is overlaid on O′, and the second U-Net Ucontour takes (O′+Gedge,Gmask,Gpos) to produce the final stylized frame O. This two-stage approach allows for the sequential restoration of texture and contour details. The entire process is depicted in Fig. 4 (c), showing how the animated, contour-free character is transformed into a stylized animation sequence.
Experiment
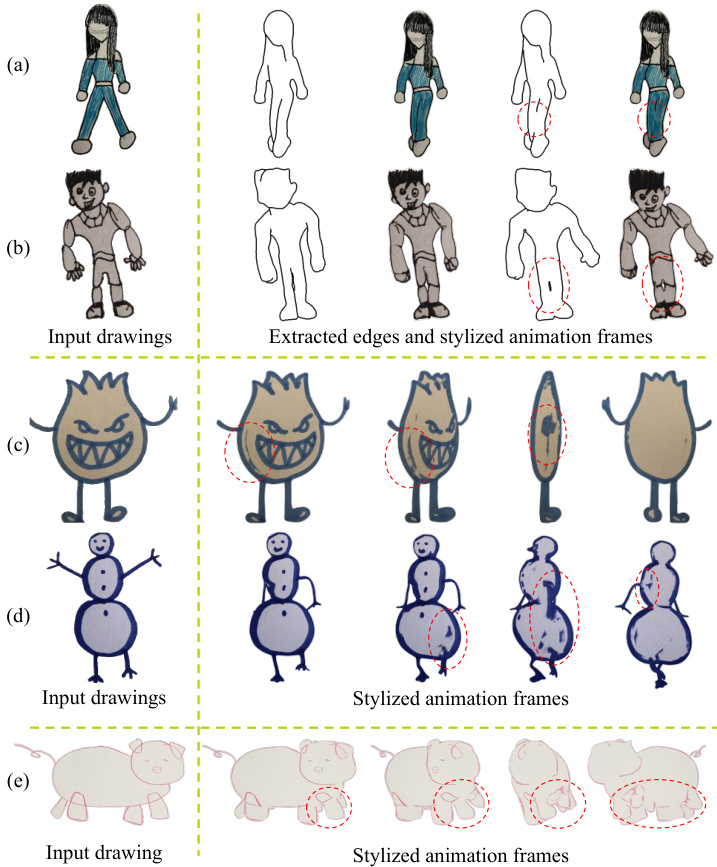
The evaluation assesses computational efficiency through stage-by-stage timing, qualitative performance via direct visual comparisons with existing methods, perceptual quality through a controlled user study, and architectural necessity through component removal tests. Runtime measurements confirm the pipeline enables efficient character modeling and rapid animation generation, while comparative demonstrations show the method successfully produces 3D-aware results that faithfully track input motions and preserve original artistic styles. User ratings and ablation tests further validate that the system significantly outperforms competitors in motion consistency and style retention, confirming that contour removal, structural refinement, and rotation-invariant processing are essential for maintaining visual coherence across diverse poses.