Command Palette
Search for a command to run...
DeBERTa-v3-base Baseline Model [Training]
Abstract
One-sentence Summary
To address dataset scarcity and domain variation in pedestrian attribute recognition, this paper introduces MSP60K, a 60,122-image benchmark featuring 57 attributes across eight scenarios with synthetic degradation, evaluates seventeen representative models under random and cross-domain splits, and proposes LLM-PAR, a framework that employs a Vision Transformer backbone with a multi-embedding query Transformer and integrates large language models for ensemble learning and visual feature augmentation.
Key Contributions
- To address domain shift and dataset saturation in pedestrian attribute recognition, this paper introduces MSP60K, a large-scale cross-domain dataset comprising 60,122 images with 57 attribute annotations across eight scenarios. The dataset incorporates synthetic image degradation to simulate real-world conditions and establishes a rigorous evaluation protocol by benchmarking seventeen representative recognition models under random and cross-domain split protocols.
- The work presents LLM-PAR, a recognition framework that combines a Vision Transformer backbone with a Multi-Embedding Query Transformer to extract global and part-aware visual features. This architecture integrates a large language model to perform ensemble learning and augment feature representations through instruction-guided text processing.
- Extensive evaluations on MSP60K and established benchmarks validate the framework, achieving state-of-the-art performance across multiple datasets. The method records 92.20 mA and 90.02 F1 on the PETA dataset, alongside 91.09 mA and 90.41 F1 on PA100K.
Introduction
Pedestrian attribute recognition powers essential computer vision applications like surveillance tracking and person re-identification by mapping captured images to semantic labels such as clothing and demographics. Despite its practical value, the field has stalled because existing benchmarks approach performance saturation, rely on simplistic random splits, and ignore cross-domain variations or real-world imaging defects like motion blur and low light. To overcome these limitations, the authors introduce MSP60K, a large-scale cross-domain dataset featuring over 60,000 images across eight diverse scenarios and augmented with synthetic degradations to mirror deployment challenges. Building on this benchmark, they develop LLM-PAR, a framework that combines a Vision Transformer with a multi-embedding query module and leverages a large language model to enrich visual features and drive robust ensemble learning for attribute classification.
Dataset

-
Dataset Composition and Sources: The authors introduce MSP60K, a pedestrian attribute recognition benchmark comprising 60,122 images captured across eight diverse real-world environments, including markets, schools, kitchens, ski resorts, and various outdoor and construction sites. The data originates from multiple cameras and handheld devices, encompassing over 5,000 unique individuals with varied nationalities, seasonal variations, and front, back, and side viewpoints.
-
Key Details for Each Subset: The dataset is organized into three primary configurations for evaluation. The standard random partition divides the data into 30,298 training, 6,002 validation, and 23,822 testing images with a uniform scene distribution. The cross-domain partition allocates 34,128 images from five specific scenarios to training and 24,994 images from three outdoor scenarios to testing. Additionally, a robustness subset is created by intentionally degrading one-third of the images in each partition through simulated lighting shifts, random occlusions, motion blur, and noise.
-
Data Usage and Processing: The authors utilize these splits to benchmark pedestrian attribute recognition models under both standard and generalized conditions. The random split supports conventional training and evaluation, while the cross-domain split specifically tests domain generalization and zero-shot performance. The degraded subset allows researchers to measure model resilience against real-world imaging challenges. The authors also leverage the full dataset to analyze long-tail attribute distributions and train feature extractors for domain visualization.
-
Metadata and Annotation Details: Each image is annotated with 57 distinct attributes organized into 11 categories, such as gender, age, body size, viewpoint, headwear, upper and lower body clothing, footwear, bags, body movement, and sports equipment. The authors construct comprehensive metadata that includes scene identifiers, domain labels, and statistical records of attribute co-occurrence frequencies. While no explicit cropping pipeline is described, the raw images span a wide resolution range from 30 by 80 to 2005 by 3008 pixels, requiring downstream normalization during model training.
Method
The authors present a multi-modal framework for pedestrian attribute recognition, LLM-PAR, which integrates visual and textual reasoning through three primary components: visual feature extraction, image caption generation, and a classification module. The overall architecture leverages a pre-trained vision Transformer backbone for visual feature extraction, a large language model (LLM) branch for generating descriptive captions, and a model aggregation mechanism to combine outputs from both branches. As shown in the framework diagram, the process begins with an input pedestrian image, which is partitioned into patches and projected into visual tokens. These tokens are augmented with positional embeddings before being processed by a visual encoder, such as EVA-ViT-G, to produce a global visual representation FV. To enable efficient tuning, the visual encoder parameters are frozen, and LoRA is applied to adaptively fine-tune the model.
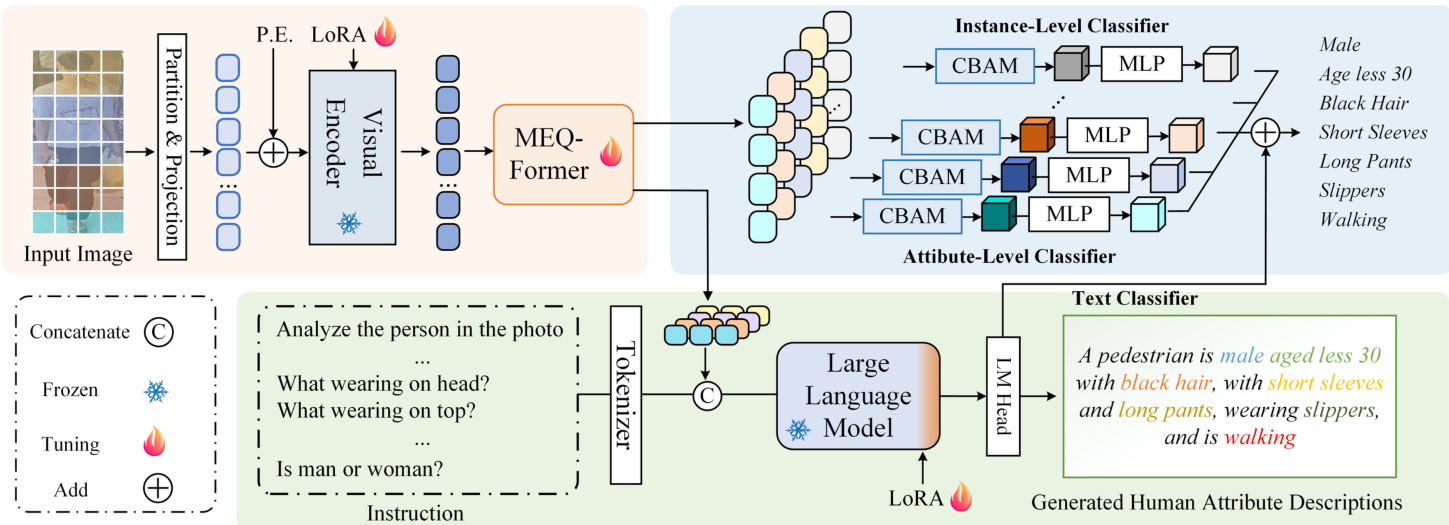
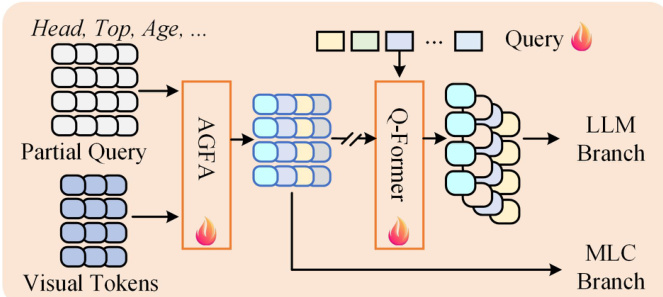
The visual features are then fed into a Multi-Embedding Query Transformer (MEQ-Former), designed to extract specific features for different attribute groups. The attributes are categorized into groups Aj based on semantic types such as head, upper body clothing, or actions. For each group, a set of partial queries Qp is generated and processed through an Attributes Group Features Aggregate (AGFA) module, which consists of stacked feed-forward networks and cross-attention layers. This module computes Fq=FFN(CrossAttn(Q=Qp,K=FV,V=FV)), producing group-specific features Fg. These features are further processed by a Q-Former, which acts as a bridge between visual and language modalities, generating text-related information Fqj. To capture fine-grained details, Convolutional Block Attention Modules (CBAM) are applied to the group features, enabling attribute-specific predictions.
The LLM branch enhances attribute recognition by leveraging natural language reasoning. Instructions are constructed for each attribute group, such as "Analyze the person's photo, and categorize it into attributes. What are wearing on their head?" These instructions are tokenized to produce instruction embeddings TE, which are concatenated with the visual features Fq to form instruction features FI. During training, the ground truth description is embedded and concatenated with FI as the initial input to the LLM, which is typically a Vicuna-7B or OPT-6.7B model. The LLM is fine-tuned using LoRA, with the low-rank dimension r set to 32, and the last hidden state is used to generate a textual description of the pedestrian attributes. The generated caption is then processed by a Language Model Head to produce logits for attribute classification.
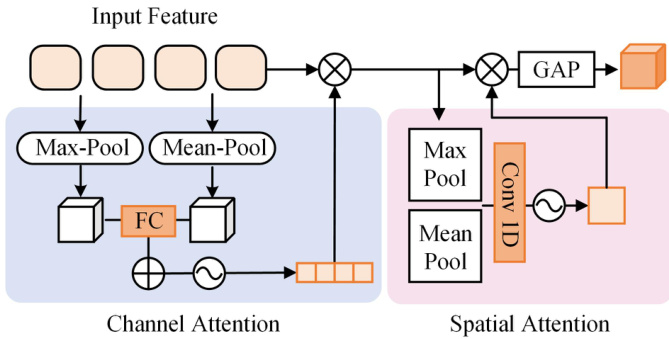
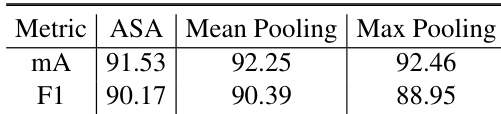
The final classification results are obtained by aggregating predictions from the visual and language branches. The framework employs two visual classifiers: an attribute-level classifier and an instance-level classifier, both utilizing multi-layer perceptrons (MLP) and CBAM modules. The predictions from these classifiers, along with the results from the language branch, are fused using one of three strategies: Attributes-Specific Aggregation (ASA), Mean Pooling, or Max Pooling. In the default configuration, Mean Pooling is used to average the logits from the three branches. The training process employs a weighted cross-entropy loss for the attribute prediction branches and a cross-entropy loss for the caption generation in the LLM branch. The loss functions are formulated to account for class imbalance and are optimized using the AdamW optimizer with a learning rate of 0.00002 and a weight decay of 0.0001.
Experiment
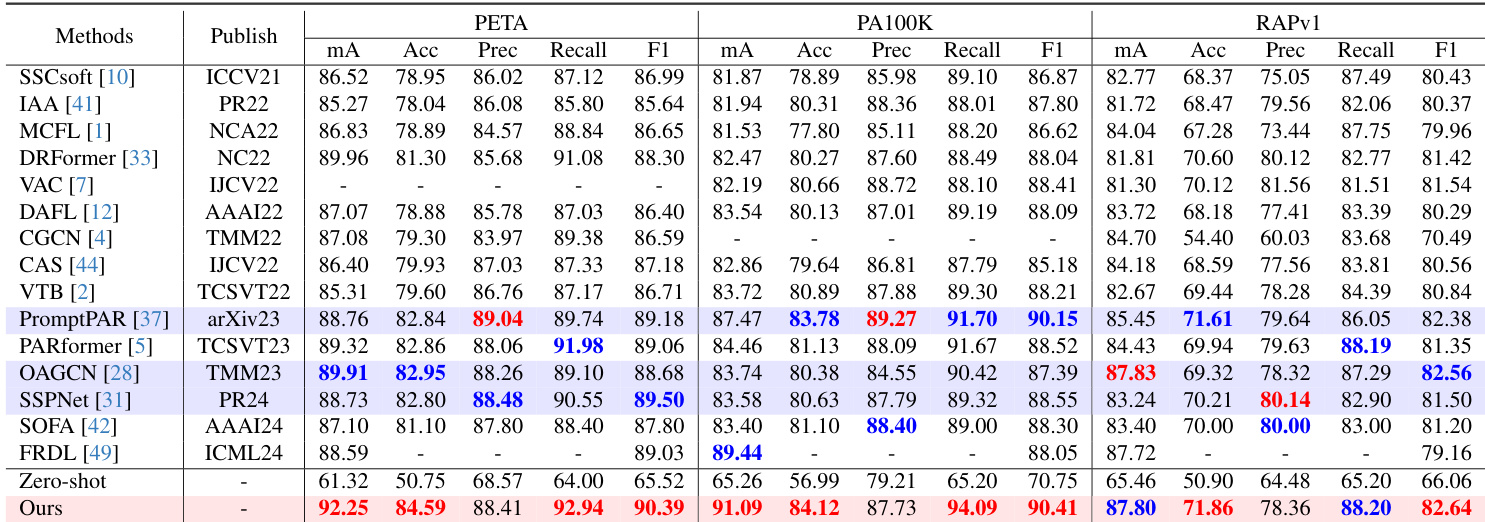
The evaluation benchmarks the proposed LLM-PAR framework against 17 state-of-the-art pedestrian attribute recognition methods across multiple public datasets and cross-domain splits. Comparative experiments validate the overall effectiveness of combining visual classification with large language models, while ablation studies confirm that the AGFA module, optimized grounding strategies, and tailored aggregation techniques significantly improve feature integration and recognition reliability. Component analyses further demonstrate that carefully balancing architectural complexity with targeted feature learning yields robust performance and effectively mitigates common generative hallucinations.
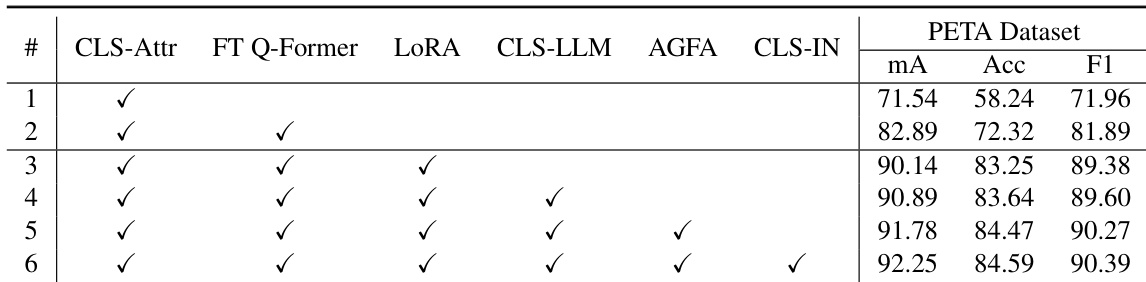
The authors conduct ablation studies on the PETA dataset to evaluate the contributions of various components in their LLM-PAR framework. Results show that adding each component sequentially improves performance, with the full model achieving the highest scores across all metrics. The integration of the AGFA module and CLS-IN module provides consistent gains, and combining all components leads to the best overall results. Adding the AGFA module improves performance across all metrics compared to the baseline. The CLS-IN module contributes to performance gains, particularly in fine-grained attribute recognition. The full model with all components achieves the highest scores on the PETA dataset.
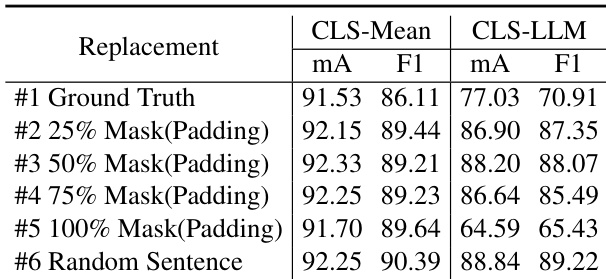
The authors analyze the impact of different ground truth replacement strategies on model performance, focusing on the use of masking and random sentence substitution. Results show that replacing ground truth with random sentences from the training set achieves the best performance, while direct use of ground truth leads to poor generalization. The optimal strategy involves a 50% masking rate, which improves recognition metrics compared to other approaches. Replacing ground truth with random sentences from the training set yields the best performance. A 50% masking rate improves recognition metrics compared to other masking strategies. Direct use of ground truth results in poor generalization and lower performance.
{"summary": "The authors conduct a comprehensive evaluation of their proposed LLM-PAR method against various state-of-the-art pedestrian attribute recognition models across multiple datasets. The results demonstrate that LLM-PAR achieves superior performance, particularly in cross-domain settings, and that its effectiveness is enhanced by specific design choices such as the AGFA module and attribute-specific aggregation strategies. The ablation studies further validate the contributions of individual components, highlighting the importance of the visual branch, LLM branch, and feature aggregation mechanisms.", "highlights": ["LLM-PAR achieves state-of-the-art results on multiple benchmarks, outperforming existing methods in both random and cross-domain splits.", "The AGFA module and attribute-specific aggregation strategy significantly improve recognition performance by enhancing feature representation and fusion.", "Ablation studies confirm that combining visual and language modeling components effectively boosts attribute recognition accuracy."]
The authors evaluate the impact of different large language models (LLMs) on their proposed framework, comparing performance across multiple metrics. Results show that while both models achieve high performance, Vicuna-7B slightly outperforms OPT-6.7B in most cases, indicating that the choice of LLM affects recognition outcomes. The comparison highlights the importance of selecting appropriate LLMs for effective attribute recognition. Vicuna-7B achieves higher performance than OPT-6.7B across key metrics. The performance difference between the two LLMs is small but consistent, suggesting model choice has a measurable impact. The results confirm that different large language models influence the overall effectiveness of the framework.

The authors evaluate their proposed method, LLM-PAR, against a range of state-of-the-art pedestrian attribute recognition models across multiple datasets, demonstrating superior performance in terms of accuracy and F1-score. The method leverages a combination of visual classification and large language model capabilities, with component analysis showing the effectiveness of specific design choices such as the AGFA module and the integration of the LLM branch. Results indicate that LLM-PAR achieves state-of-the-art results on all evaluated datasets, outperforming existing methods in both random and cross-domain settings. LLM-PAR achieves state-of-the-art results on PETA, PA100K, and RAPv1 datasets, outperforming previous methods in multiple metrics. The integration of a large language model branch significantly enhances performance, with ablation studies showing its complementary role to the visual backbone. The AGFA module and attribute-specific aggregation strategies are crucial for improving recognition accuracy and handling attribute group features effectively.
The authors evaluate their LLM-PAR framework against state-of-the-art pedestrian attribute recognition models across multiple datasets to validate its robustness in both standard and cross-domain environments. Ablation studies on the PETA dataset confirm that sequentially integrating the visual branch, language modeling branch, and specialized modules like AGFA and CLS-IN consistently enhances feature representation and recognition accuracy. Complementary experiments on training data strategies demonstrate that strategic masking and random sentence substitution significantly improve generalization compared to direct label usage, while comparisons across different large language models indicate that model architecture choice moderately impacts final performance. Ultimately, these findings establish that synergizing visual and linguistic capabilities through targeted feature aggregation and robust data manipulation yields a highly effective attribute recognition system.