Command Palette
Search for a command to run...
RWKV — The Best of Transformers and RNNs Combined
Abstract
One-sentence Summary
The authors evaluate cross-language structural priming in Chinese-English, demonstrating that Transformer architectures outperform Recurrent Neural Networks with accuracy rates exceeding 25.84% to 33.33%, thereby challenging the assumption that human sentence processing relies primarily on recurrent mechanisms and highlighting the role of cue-based retrieval.
Key Contributions
- This study evaluates recurrent neural networks and multilingual auto-regressive transformer models on cross-language structural priming between Chinese and English.
- Experimental results demonstrate that transformer architectures outperform recurrent counterparts in generating primed sentence structures, achieving accuracy rates exceeding 25.84% to 33.33%.
- Measuring probability shifts across source and target sentences reveals that these models exhibit abstract structural priming effects despite consistent semantic content. These findings challenge the conventional assumption that human sentence processing relies primarily on immediate recurrent mechanisms.
Introduction
Structural priming, the phenomenon where exposure to a specific syntactic pattern increases the likelihood of its subsequent use, serves as a valuable probe for evaluating how language models capture hierarchical syntax and approximate human sentence processing. While both recurrent neural networks and transformers have demonstrated priming effects in monolingual settings, prior research has not systematically compared their cross-linguistic capabilities, particularly across typologically distant languages. To address this gap, the authors evaluate both architectures on a Chinese-to-English priming task and demonstrate that transformers more effectively generate structurally primed outputs. This finding challenges the long-held assumption that human syntactic processing depends primarily on recurrent mechanisms and provides new insights into how computational models represent syntax across distinct linguistic families.
Dataset
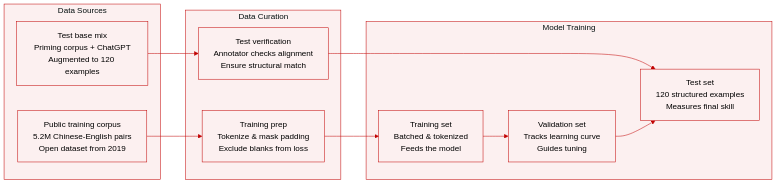
- The authors use a publicly available Chinese-English parallel corpus containing 5.2 million sentence pairs from Xu (2019) as the primary training dataset.
- For evaluation, they construct a test set sourced from the Cross-language Structural Priming Corpus (Michaelov et al., 2023), initially sampling five sentences across four syntactic structures (Active Voice, Passive Voice, Prepositional Object, and Double Object).
- They augment this test set using ChatGPT 3.5 through a one-shot learning prompt, expanding each structure to 30 sentences for a total of 120 test instances.
- Each Chinese test sentence is paired with both a correct and an incorrect English translation to assess syntactic alignment.
- A bilingual annotator manually reviews all LLM-generated outputs to verify translation equivalence and ensure the correct answers maintain strict structural correspondence with the source Chinese sentences.
- During preprocessing, the training data is batched using a standard DataLoader and tokenized with the Helsinki-NLP tokenizer.
- The authors configure the tokenizer context manager to apply target-language rules, preventing incorrect word splitting in the English output.
- Padding tokens in the training sequences are assigned a value of -100 to exclude them from loss calculations during model training.
- The training corpus contains no demographic or identity data, though the authors note potential cultural nuance loss in certain translated terms.
Method
The authors leverage an encoder-decoder architecture to examine structural priming in translation models, comparing the performance of recurrent neural networks (RNNs) and transformers in generating syntactically diverse English outputs from Chinese inputs. The overall framework consists of three main phases: training, experimentation, and testing. During training, raw bilingual data undergo preprocessing, where Chinese sentences are processed using Helsinki NLP and English sentences are prepared through English preprocessing. The resulting token pairs are then fed into either a GRU-based encoder-decoder or a transformer-based encoder-decoder model for training. 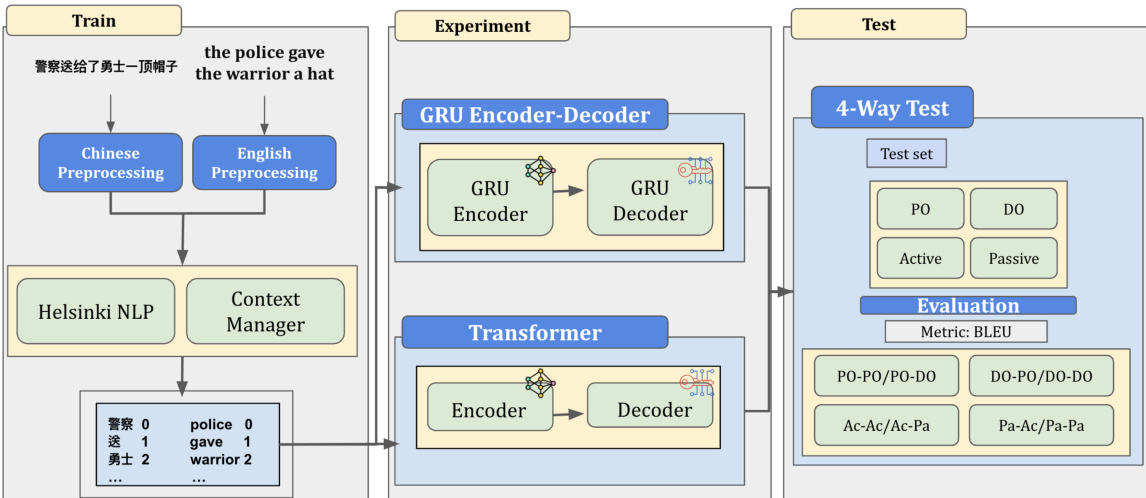
In the experimental phase, both models are trained on the same dataset, with the GRU encoder-decoder and transformer encoder-decoder operating under the same conditions. The GRU encoder-decoder model utilizes Gated Recurrent Units, which incorporate update and reset gates to manage long-distance dependencies and mitigate the vanishing gradient problem. The update gate controls the blending of the current input with the previous hidden state, enabling the model to selectively incorporate relevant information during decoding. The reset gate regulates how the current input interacts with the previous state, allowing the model to forget outdated information and focus on more pertinent features. Additionally, an attention mechanism is integrated into the GRU decoder to enhance its ability to focus on relevant parts of the input sequence, improving prediction accuracy and structural pattern recognition.
The transformer model employs a self-attention mechanism to capture sentence structure by identifying dependencies between different positions in the input sequence. The attention function is defined as:
Attention(Q,K,V)=softmax(dkQKT)Vwhere Q, K, and V are derived from linear transformations of the input sequence, each with learnable weight matrices. In the encoder, these matrices are derived from the same source sequence, while in the decoder, Q comes from the target sequence and K, V from the encoder's output. This allows the model to simultaneously focus on all positions and capture structural relationships. To enhance feature representation, the transformer uses multi-head attention, where multiple attention heads capture different levels of sentence features. The multi-head attention output is computed as:
MH(Q,K,V)=Concat(head1,…,headh)⋅WOwhere WO is a trainable weight matrix and head1,…,headh represent the attention weights of each head. The model also employs learnable positional embeddings instead of fixed sinusoidal encodings to better capture positional relationships relevant to structural priming.
In the testing phase, both models are evaluated using a 4-way test that assesses performance across four sentence structures: propositional object (PO), double object (DO), active (Ac), and passive (Pa). The evaluation is conducted using the BLEU metric, comparing the system-generated English output with both a structurally correct reference and an incorrect reference. The difference in BLEU scores between these two references is used to quantify the priming effect. This setup enables a direct comparison of how well each model preserves syntactic structure from the input Chinese sentence during translation.
Experiment
This study evaluates GRU-based RNN and Transformer models by training them on Chinese-English sentence pairs and testing their ability to replicate cross-language structural priming through comparisons with structurally aligned and misaligned reference sentences. The experimental design validates whether the models preferentially reproduce syntactic structures from priming inputs regardless of semantic content, revealing that both architectures develop abstract crosslingual grammatical representations. Qualitatively, Transformers consistently demonstrate a stronger structural priming effect and more reliable syntactic adaptation than RNNs, challenging the traditional assumption that recurrent processing better mirrors human sentence comprehension. These results instead support attention-based cue-retrieval mechanisms as a cognitively plausible framework for modeling how neural networks capture and apply abstract grammatical patterns across typologically distinct languages.
The authors compare the performance of GRU-based RNN and transformer models in replicating cross-language structural priming effects between Chinese and English. Results show that the transformer model generally achieves higher BLEU scores for correct structural alignments, particularly with longer n-grams, indicating a stronger ability to preserve syntactic structure, while the GRU model exhibits less deviation in incorrect priming scenarios. The transformer model achieves higher BLEU scores for correct structural alignments compared to the GRU model. The GRU model shows less deviation in predictions for incorrect priming structures than the transformer. Both models perform better on active-passive structures than on PO-DO structures in cross-language priming.
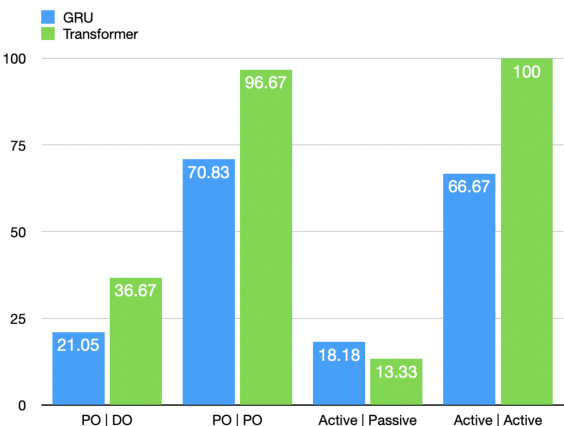
The evaluation compares GRU-based RNN and transformer architectures in replicating cross-language structural priming effects between Chinese and English to validate their respective capacities for syntactic preservation and priming adaptation. The results indicate that transformers demonstrate a stronger inherent ability to maintain accurate structural alignments, while GRU models exhibit greater predictive stability when handling incorrect priming patterns. Overall, both architectures show consistent structural biases, performing more reliably on active-passive constructions than on prepositional object-ditransitive patterns.