Command Palette
Search for a command to run...
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Yupeng Zhou Daquan Zhou Ming-Ming Cheng Jiashi Feng Qibin Hou
One-click Deployment of StoryDiffusion
Abstract
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pre-trained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents.
One-sentence Summary
StoryDiffusion augments pre-trained text-to-image diffusion models in a zero-shot manner by integrating Consistent Self-Attention to maintain cross-image subject consistency and a Semantic Motion Predictor that estimates inter-frame transitions in semantic space to generate long-range videos with stable, smooth visual progression.
Key Contributions
- The paper introduces Consistent Self-Attention, a training-free and pluggable mechanism that establishes cross-image connections within a batch to preserve subject identity and complex details across multiple generated images in a zero-shot manner.
- A Semantic Motion Predictor is proposed to extend the framework to long-range video generation by estimating transition conditions between start and end frames directly in semantic spaces, producing smoother and more stable sequences than latent-space-only approaches.
- These components are integrated into StoryDiffusion, a unified framework that narrates text-based stories through consistent image sequences or videos while effectively handling large-scale movements and complex transitions.
Introduction
Diffusion models have revolutionized visual content generation, but maintaining subject consistency across multiple frames for storytelling applications remains difficult. Existing methods typically force a trade-off between text controllability and visual fidelity, struggle to preserve both identity and attire simultaneously, or rely on computationally expensive temporal modules. The authors overcome these limitations by introducing Consistent Self-Attention, a zero-shot plug-in that incorporates reference tokens directly into the attention mechanism to enforce cross-image character consistency without additional training. They further pair this module with a sliding window for extended narratives and a Semantic Motion Predictor that generates smooth video transitions by modeling motion in semantic space, delivering a lightweight and highly controllable pipeline for automated story visualization.
Dataset
- Dataset composition and sources: The authors use external datasets, but the provided excerpt does not specify their composition or origins.
- Key details for each subset: The provided text does not list subset sizes, sources, or filtering criteria.
- How the paper uses the data: The authors apply the data for model training, but the excerpt omits details on training splits, mixture ratios, and usage pipelines.
- Cropping strategy, metadata construction, or other processing details: The provided excerpt does not describe any cropping methods, metadata generation, or preprocessing steps.
Method
The proposed framework, StoryDiffusion, operates in two distinct stages to generate consistent image sequences and transition videos based on a text-based story. The first stage focuses on generating subject-consistent images in a training-free manner, while the second stage converts these images into smooth, consistent videos using a novel motion prediction module.
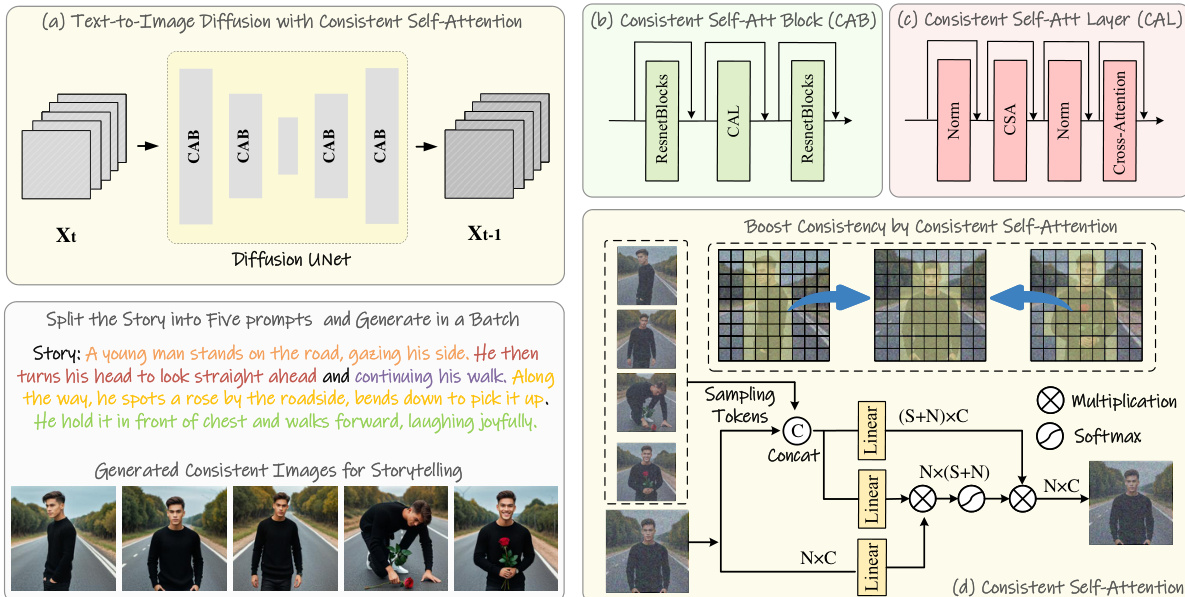
As shown in the figure below, the initial stage leverages a pre-trained text-to-image diffusion model to generate a sequence of images corresponding to a story. The narrative is split into multiple prompts, which are processed in a batch to generate a set of images. To ensure consistency across this batch, the authors introduce a training-free module called Consistent Self-Attention. This module is integrated into the U-Net architecture of the diffusion model, replacing the standard self-attention mechanism. The key innovation lies in its ability to establish connections between different images within the batch during the generation process. Given a batch of image features I∈RB×N×C, the original self-attention operates independently on each image feature Ii. In contrast, Consistent Self-Attention samples tokens Si from other images in the batch and pairs them with the tokens from the target image Ii to form a new set of tokens Pi. The query Qi remains unchanged, but the key and value are derived from the combined set Pi. This process allows the self-attention function to compute interactions across the entire batch, thereby promoting the convergence of shared attributes such as character identity, facial features, and clothing. This training-free approach enables the model to generate subject-consistent images without requiring additional training, making it a hot-pluggable enhancement to existing diffusion models.
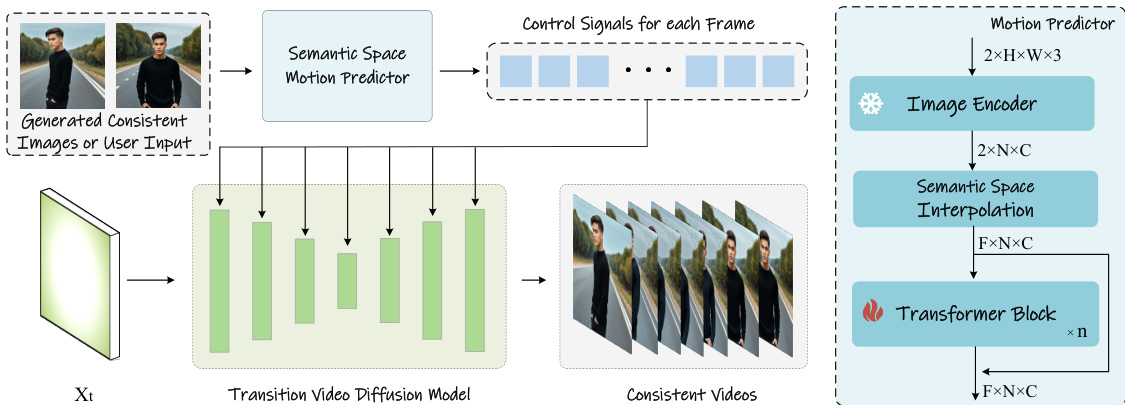
The second stage of StoryDiffusion transforms the generated sequence of consistent images into a video by predicting the intermediate frames between each pair of adjacent images. This is achieved through a novel module named the Semantic Motion Predictor. The core challenge addressed by this module is the instability that arises when generating transitions between images with large differences, a limitation observed in existing methods that rely solely on temporal modules. To overcome this, the Semantic Motion Predictor operates in the semantic space. It first encodes the start and end frames, Fs and Fe, into vectors Ks and Ke using a pre-trained CLIP image encoder, which captures spatial information effectively. These semantic vectors are then interpolated to form a sequence K1,K2,...,KL corresponding to the desired frame length. A transformer-based structure predictor processes this sequence to generate predicted transition embeddings P1,P2,...,PL. These embeddings are then used as control signals in the transition video diffusion model. Specifically, the predicted embeddings are projected into keys and values and incorporated into the cross-attention mechanism of the U-Net, guiding the generation of each frame. This approach leverages the generative power of the video diffusion model while ensuring that the motion is guided by a coherent semantic trajectory, leading to smoother and more stable transitions, especially for long-range videos. The framework is designed to be modular, allowing the consistent images from the first stage to be used as input for the video generation stage, enabling the creation of coherent visual stories.
Experiment
Evaluated on standard diffusion architectures against leading baselines, the experiments validate subject-consistent image generation and smooth transition video creation. Qualitative assessments demonstrate that the method reliably preserves character identity, attire, and prompt adherence across varied scenarios, while competing models frequently exhibit visual artifacts, inconsistent clothing, or broken temporal continuity. Complementary ablation tests confirm the effectiveness of the pluggable design and sampling parameters, and a blind user study reinforces these observations through strong participant preference. Collectively, these results establish the approach as a robust, training-free framework for maintaining visual consistency in both static and dynamic generation tasks.
The authors evaluate their method for generating consistent images and videos by comparing it with recent state-of-the-art models. Results show that their approach achieves superior performance in both qualitative and quantitative assessments, with the highest user preference across different tasks. StoryDiffusion outperforms IP-Adapter and PhotoMaker in generating consistent images, as shown by higher user preference. StoryDiffusion achieves the highest user preference in transition video generation compared to SparseCtrl and SEINE. The method demonstrates strong performance in maintaining subject consistency and text controllability across both image and video generation tasks.

The authors evaluate their method for generating consistent transition videos by comparing it with state-of-the-art approaches. Results show that their method outperforms the competitors across multiple quantitative metrics, demonstrating superior continuity and consistency in video generation. The findings are supported by both quantitative data and user study results. the method achieves the best performance on all four quantitative metrics for transition video generation compared to the baselines. The results indicate improved continuity and consistency in generated videos, with fewer corrupted intermediate frames. The user study confirms the superior performance of the method in generating consistent transition videos.

The authors compare their method with existing approaches for generating consistent images and videos, evaluating both qualitative and quantitative performance. Results show that their method achieves superior consistency and alignment with text prompts in both image and video generation tasks. The user study further confirms the effectiveness of their approach over state-of-the-art baselines. StoryDiffusion outperforms IP-Adapter and PhotoMaker in maintaining subject consistency and text controllability for image generation. StoryDiffusion generates smoother and more physically plausible transition videos compared to SparseCtrl and SEINE. User study results indicate a clear preference for StoryDiffusion in both image and video generation tasks.

The evaluation compares the proposed StoryDiffusion method against state-of-the-art baselines across image and transition video generation tasks to validate subject consistency and text controllability. Qualitative assessments and user studies demonstrate that the approach maintains superior prompt adherence and visual coherence while producing smoother, more physically plausible video sequences with fewer corrupted frames. Overall, the method consistently outperforms existing techniques in both media types, confirming its effectiveness for generating high-quality, temporally consistent content.