Command Palette
Search for a command to run...
Finetuning with Very-large Dropout
Finetuning with Very-large Dropout
Jianyu Zhang Léon Bottou
Fine-tuning GPT with nanoGPT on the Shakespeare Dataset
Abstract
It is impossible today to pretend that the practice of machine learning is always compatible with the idea that training and testing data follow the same distribution. Several authors have recently used ensemble techniques to show how scenarios involving multiple data distributions are best served by representations that are both richer than those obtained by regularizing for the best in-distribution performance, and richer than those obtained under the influence of the implicit sparsity bias of common stochastic gradient procedures. This contribution investigates the use of very high dropout rates instead of ensembles to obtain such rich representations. Although training a deep network from scratch using such dropout rates is virtually impossible, fine-tuning a large pre-trained model under such conditions is not only possible but also achieves out-of-distribution performances that exceed those of both ensembles and weight averaging methods such as model soups. This result has practical significance because the importance of the fine-tuning scenario has considerably grown in recent years. This result also provides interesting insights on the nature of rich representations and on the intrinsically linear nature of fine-tuning a large network using a comparatively small dataset.
One-sentence Summary
Fine-tuning large pre-trained models with very large dropout rates yields richer representations that exceed the out-of-distribution performance of both ensembles and weight averaging methods like model soups, while providing insights into the intrinsically linear nature of adapting large networks to small datasets.
Key Contributions
- This work introduces a fine-tuning strategy that applies very high dropout rates, randomly masking above 90% of units in the representation layer, to force large pre-trained models to learn richer representations without explicit diversity engineering.
- Evaluations on out-of-distribution scenarios demonstrate that this approach surpasses the performance of both traditional ensemble methods and weight-averaging techniques such as model soups.
- The analysis provides concrete insights into the composition of rich representations by empirically confirming that fine-tuning large networks on comparatively small datasets operates as an intrinsically linear process.
Introduction
Modern machine learning increasingly relies on pre-training large models on broad datasets before fine-tuning them for specific tasks and evaluating them under distribution shifts. This departure from strict i.i.d. assumptions makes it essential to develop representations that generalize robustly across diverse data regimes. Prior methods attempt to build these richer feature sets through ensembles, adversarial sampling, or weight averaging, but they impose heavy computational costs and struggle against the implicit sparsity bias of standard gradient descent. The authors leverage extremely high dropout rates during the fine-tuning phase to force the network to retain weakly relevant and redundant features. By applying this approach to pre-trained models instead of training from scratch, they achieve superior out-of-distribution performance compared to ensembles and model soups while demonstrating a computationally efficient path that highlights the near-linear dynamics of fine-tuning large architectures.
Method
The authors leverage a three-distributions setup to analyze the transfer learning process, where a pre-trained model serves as a base model trained on a large, controlled distribution Tp. This base model produces features Ψ, which are then incorporated into a new model ωd∘Ψ that undergoes fine-tuning on a second distribution Td. The ultimate performance is evaluated on a third distribution Td, which may differ from the fine-tuning distribution in terms of data distribution or feature availability, simulating real-world out-of-distribution (o.o.d.) scenarios. The goal is to identify fine-tuning strategies that enhance robustness under such distribution shifts.
As shown in the figure below: the framework consists of a pre-trained base model with residual connections, which is fine-tuned on a target task using a modified training procedure. The model architecture leverages skip connections to expose inner-layer features to the final classification layer, enabling a near-linear utilization of learned representations during fine-tuning. This decomposition, as formalized by Veit et al. (2016), expresses the penultimate layer representation Φ(x) as an additive sum of contributions from individual residual blocks:
where fi denotes the function implemented by the i-th residual block. This additive structure is critical for the proposed method, as it allows dropout applied to Φ(x) to simultaneously block contributions from all residual blocks. The authors apply a very-large dropout rate—approximately 90%—to the penultimate layer representation Φ, modifying it as:
Φdropout(x)=1−λm(λ)⊙Φ(x)where m(λ) is a vector of Bernoulli variables with probability λ of being zero. This mechanism forces the model to rely on a broader set of features during fine-tuning, mitigating the gradient starving phenomenon observed in linear models where optimization tends to overfit to a single dominant feature. While L2 regularization and dropout are equivalent in the linear case for encouraging feature diversity, this equivalence breaks down in deep networks. In such settings, very-large dropout applied during fine-tuning, rather than pre-training, promotes more robust representations for o.o.d. generalization.
The method is implemented using standard stochastic optimization procedures such as SGD or ADAM. Notably, the large dropout rate is applied only during fine-tuning, not during the initial pre-training phase, as such high rates would degrade performance during the initial learning stage. The authors demonstrate that this simple technique is compatible with other fine-tuning strategies, including weight averaging and ensemble methods, and significantly enhances o.o.d. performance even when combined with these techniques. However, the very-large dropout approach alone already dominates performance improvements, suggesting its central role in improving robustness under distribution shifts.
Experiment
The experiments validate the impact of high dropout rates on out-of-distribution generalization by fine-tuning pre-trained vision models across multiple datasets, diverse hyperparameter configurations, and varying levels of pre-training representation richness. Results demonstrate that applying a very-large dropout rate on the penultimate layer consistently yields superior out-of-distribution performance compared to ensemble and weight averaging baselines, while maintaining robustness across different hyperparameter and dropout rate selections. Further analysis confirms that this technique is ineffective for training from scratch but highly beneficial for fine-tuning pre-trained models, as it selectively leverages rich, pre-existing feature representations rather than attempting to learn new ones. Ultimately, the findings establish very-large dropout as the primary driver for out-of-distribution robustness and highlight a fundamental divergence between optimization strategies for in-distribution versus out-of-distribution generalization.
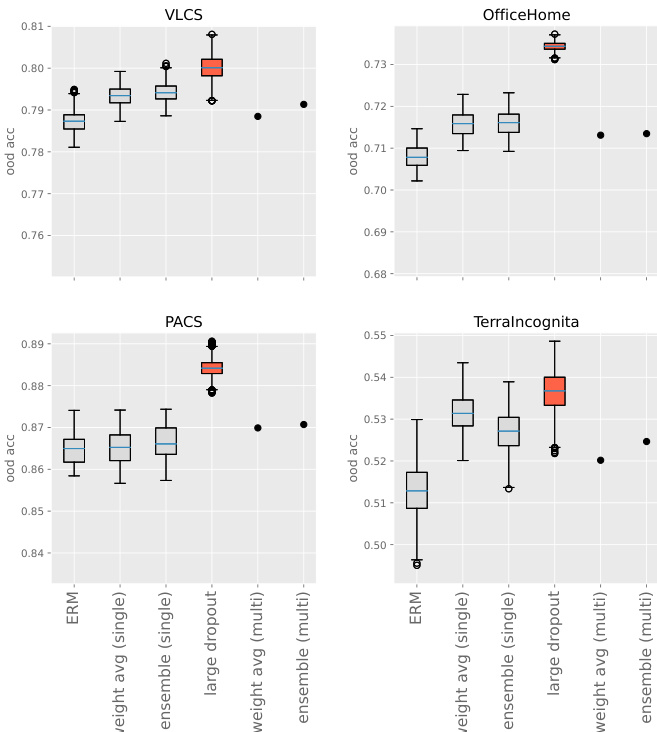
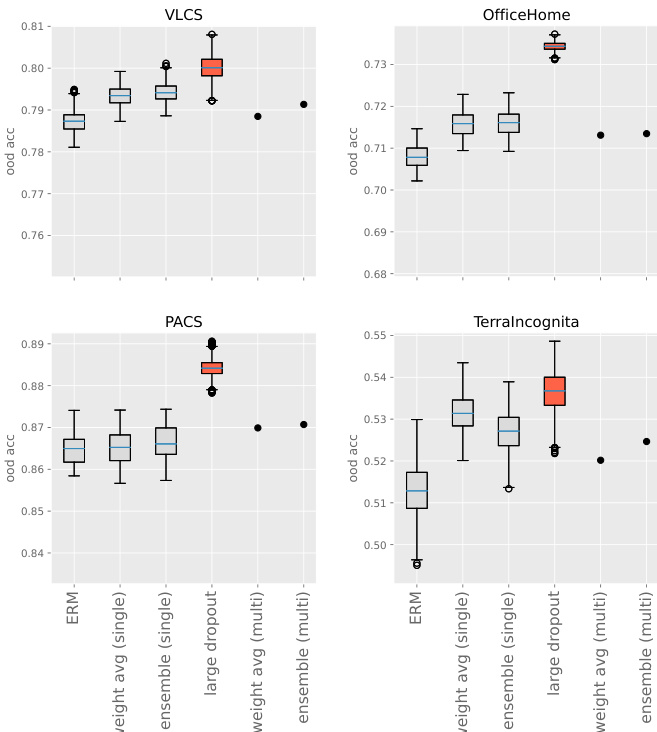
The authors compare various fine-tuning methods on out-of-distribution tasks, focusing on the performance of very-large dropout compared to ensemble and weight averaging techniques. Results show that very-large dropout consistently outperforms baseline methods, and its effectiveness increases with richer representations in the pre-trained model. The method is robust to hyperparameter selection and provides significant improvements even when combined with other techniques. Very-large dropout achieves better out-of-distribution performance than ensemble and weight averaging methods. The method is compatible with other techniques but acts as the leading factor in performance improvement. Performance improves with richer representations in the pre-trained model, and the approach is robust to hyperparameter selection.
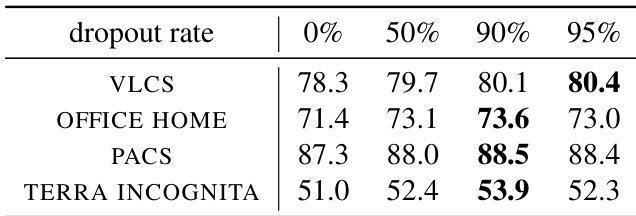
The authors investigate the impact of dropout rates on out-of-distribution performance, finding that very-large dropout rates consistently improve performance across multiple datasets compared to standard or lower dropout rates. The results show that higher dropout rates lead to better o.o.d. performance, with optimal rates around 90% or higher, and that this approach is robust and effective even when combined with other techniques like ensembles or weight averaging. The method is particularly effective when applied to models with rich representations, such as those pre-trained with extensive data augmentations. Very-large dropout rates consistently outperform standard dropout rates across multiple datasets. The optimal dropout rate for o.o.d. performance is around 90% or higher, and the performance remains stable across this range. The very-large dropout approach is compatible with ensembles and weight averaging, providing consistent improvements over baseline fine-tuning methods.
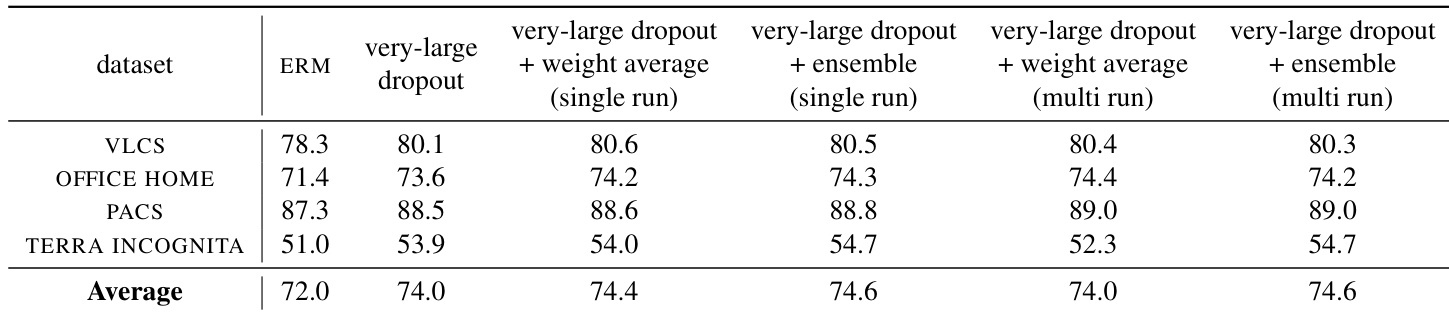
The authors compare various fine-tuning methods on out-of-distribution tasks, focusing on the effectiveness of very-large dropout and its combination with ensemble and weight averaging techniques. Results show that very-large dropout consistently improves performance over baseline methods, and its benefits are more pronounced when applied to models with richer representations. Ensemble and weight averaging provide only marginal improvements when combined with very-large dropout. Very-large dropout outperforms baseline methods and provides a significant improvement over standard fine-tuning. Combining very-large dropout with ensemble or weight averaging techniques yields only marginal gains in performance. The effectiveness of very-large dropout increases with the richness of the pre-trained model's representation.
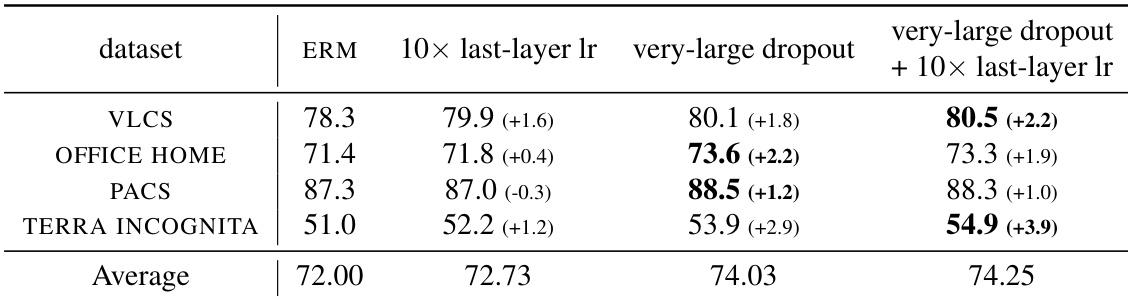
The authors compare various fine-tuning methods on out-of-distribution performance across multiple datasets. Results show that very-large dropout consistently outperforms other methods, including ensembles and weight averaging, and the performance gap is particularly pronounced on certain datasets. The method is robust to hyperparameter selection and maintains strong performance across different scenarios. Very-large dropout achieves superior out-of-distribution performance compared to ensemble and weight averaging methods. The method is robust to hyperparameter choices, with consistent performance across different datasets. Ensemble and weight averaging techniques provide only marginal improvements when applied after very-large dropout fine-tuning.
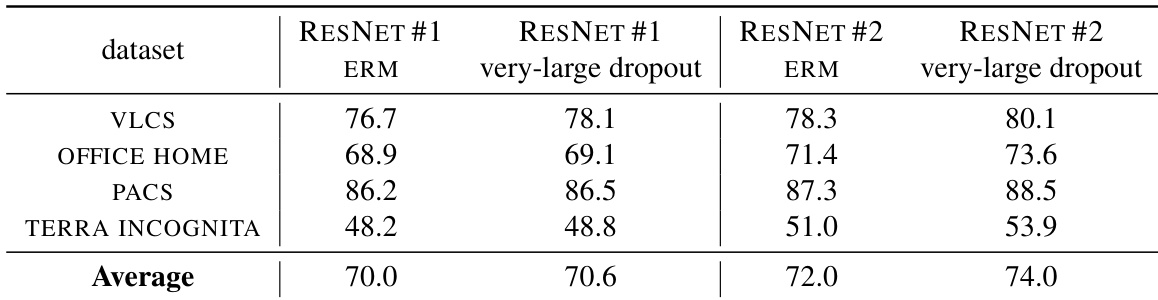
The authors compare the out-of-distribution performance of very-large dropout against baseline methods on two pre-trained ResNet models. Results show that very-large dropout consistently improves o.o.d. performance over standard fine-tuning, and this improvement is more pronounced on the model with richer representations. The method also demonstrates robustness to hyperparameter selection. Very-large dropout consistently improves out-of-distribution performance compared to standard fine-tuning on both pre-trained models. The performance gain from very-large dropout is more significant on the model with richer representations. The method shows robustness to hyperparameter selection, with the worst results still outperforming the best results of baseline methods.
The experiments evaluate various fine-tuning strategies on out-of-distribution tasks across multiple datasets and pre-trained models, specifically validating the generalization efficacy of very-large dropout. Qualitative findings reveal that this approach consistently surpasses standard fine-tuning, ensembles, and weight averaging in robustness and transfer capability. The method demonstrates remarkable stability across hyperparameter choices and delivers progressively stronger gains when applied to models with richer learned representations. Ultimately, it serves as the dominant factor for performance improvement, rendering supplementary ensemble techniques largely redundant.