Command Palette
Search for a command to run...
CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Canonicalization
CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Canonicalization
Hao-Yang Peng Jia-Peng Zhang Meng-Hao Guo Yan-Pei Cao Shi-Min Hu
One-click Deployment of CharacterGen: High-Quality 3D Characters from a Single Image
Abstract
In the field of digital content creation, generating high-quality 3D characters from single images is challenging, especially given the complexities of various body poses and the issues of self-occlusion and pose ambiguity. In this paper, we present CharacterGen, a framework developed to efficiently generate 3D characters. CharacterGen introduces a streamlined generation pipeline along with an image-conditioned multi-view diffusion model. This model effectively calibrates input poses to a canonical form while retaining key attributes of the input image, thereby addressing the challenges posed by diverse poses. A transformer-based, generalizable sparse-view reconstruction model is the other core component of our approach, facilitating the creation of detailed 3D models from multi-view images. We also adopt a texture-back-projection strategy to produce high-quality texture maps. Additionally, we have curated a dataset of anime characters, rendered in multiple poses and views, to train and evaluate our model. Our approach has been thoroughly evaluated through quantitative and qualitative experiments, showing its proficiency in generating 3D characters with high-quality shapes and textures, ready for downstream applications such as rigging and animation.
One-sentence Summary
The authors present CharacterGen, a framework that efficiently generates high-quality 3D characters from single images by combining an image-conditioned multi-view diffusion model for pose canonicalization, a transformer-based generalizable sparse-view reconstruction model, and a texture-back-projection strategy, with quantitative and qualitative evaluations on a curated anime character dataset demonstrating its ability to produce detailed shapes and textures ready for rigging and animation.
Key Contributions
- CharacterGen introduces an image-conditioned multi-view diffusion model that calibrates diverse input poses into a canonical form while preserving key visual attributes for single-image character generation.
- The framework integrates a transformer-based sparse-view reconstruction model with a texture-back-projection strategy to synthesize detailed 3D geometry and high-fidelity texture maps from multi-view images.
- A curated dataset of 13,746 anime characters rendered across multiple poses and viewpoints is provided for training and evaluation, with quantitative and qualitative experiments validating the model's capability for downstream rigging and animation.
Introduction
The rapid expansion of digital entertainment and virtual reality has made efficient 3D asset creation essential, yet manual modeling remains a significant production bottleneck. While single-image to 3D generation offers a promising solution, existing methods struggle with the complex articulations, severe self-occlusion, and diverse posing typical of stylized characters. Prior approaches heavily rely on realistic human body priors that fail to capture exaggerated proportions and loose clothing, and they often lack the flexibility to handle arbitrary input poses or suffer from multi-face generation artifacts. To overcome these hurdles, the authors leverage a two-stage pipeline called CharacterGen that transforms any single input image into a clean 3D character model. The method first canonicalizes arbitrary poses into a standardized A-pose and generates consistent multi-view images through a diffusion model, then feeds these views into a transformer-based reconstruction network to produce a detailed, animation-ready mesh. This approach effectively bypasses pose ambiguity and occlusion issues while streamlining downstream rigging and animation workflows.
Dataset
- Dataset Composition & Sources: The authors use the Anime3D dataset to enhance 3D character understanding in diffusion models and mitigate the "Janus" problem. Sourced from VRoid-Hub, the collection began with nearly 14,500 anime characters and was filtered to retain only 13,746 strictly humanoid models.
- Subset Details & Pose Generation: The data is divided into A-pose and posed categories. A-pose models feature fixed joint rotations with both arms set to 45° and both upper legs set to 6° along the Z-axis. Posed models are animated using 10 Mixamo skeleton clips including walking and sitting with randomly sampled frames, while mouth and eye joints are randomized to generate varied facial expressions.
- Processing & Rendering Pipeline: All assets are converted to images using the
three-vrmframework to support 2D diffusion model fine-tuning. The authors normalize character bounding boxes to a [-0.5, 0.5]^3 volume, position cameras 1.5 units from the scene origin with a 40° field of view, and apply combined ambient and directional lighting. - Training Usage & View Configuration: The model is trained on image pairs combining four A-pose views and one posed view. The standard A-pose configuration renders four orthographic images at azimuth angles of 0°, 90°, 180°, and 270° with zero elevation. To improve spatial layout comprehension, three additional A-pose groups use random initial azimuth angles. For generalizable reconstruction fine-tuning, the authors also generate four posed views with fully randomized azimuth and elevation angles.
Method
The authors leverage a two-stage framework for efficient 3D character generation from a single input image, designed to produce high-quality, pose-canonicalized models suitable for downstream animation tasks. The overall pipeline begins with a multi-view diffusion model that generates consistent orthographic views of the character in a standardized A-pose, followed by a coarse-to-fine reconstruction process to build a detailed 3D mesh with enhanced appearance.
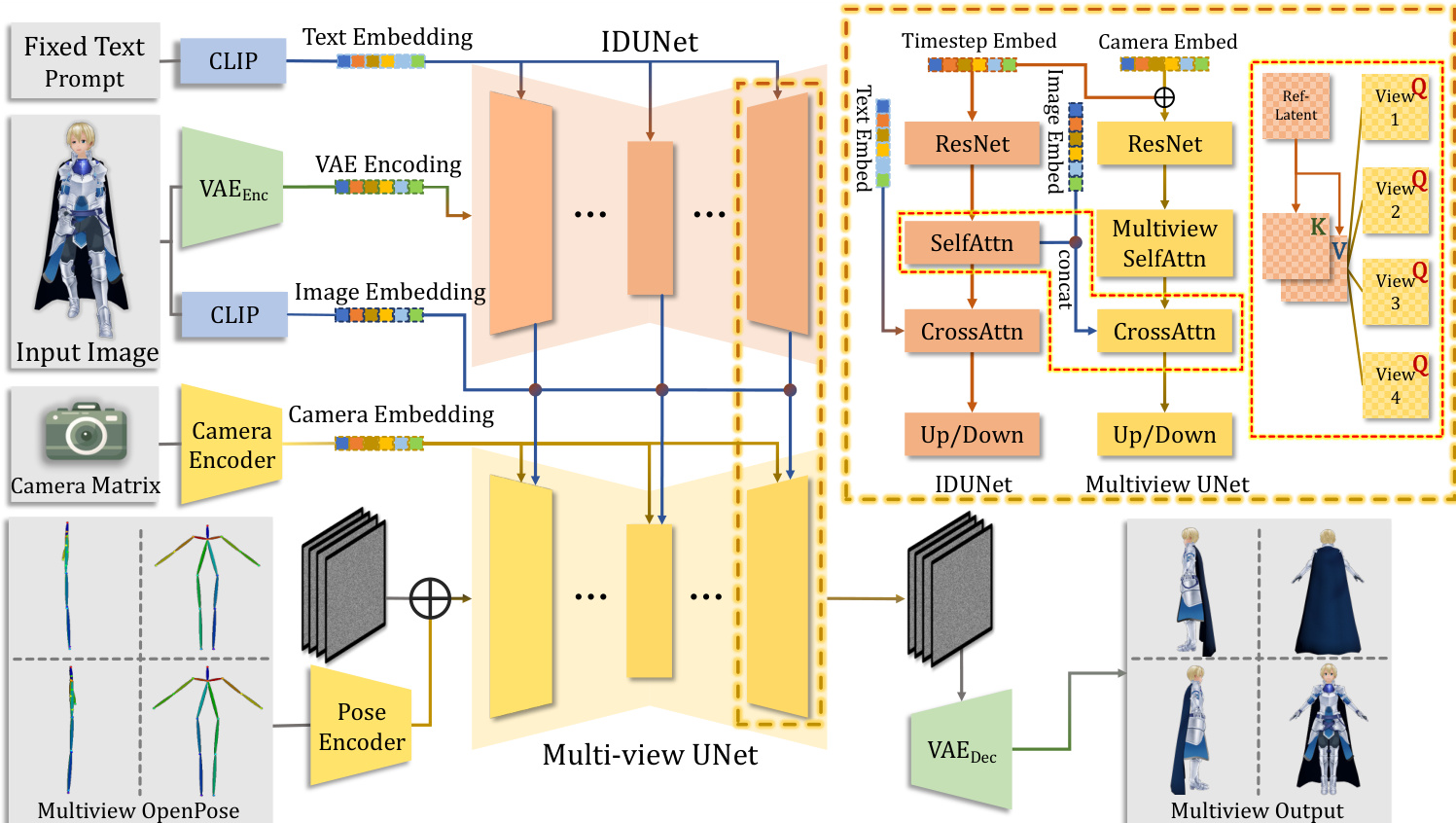
The first stage focuses on multi-view image generation and pose canonicalization. This process is driven by a diffusion model architecture that takes a single input image and synthesizes four-view images in a canonical pose. The framework employs an IDUNet module to transfer pixel-level appearance features from the input image to the diffusion process, ensuring high fidelity to the original texture. Unlike prior methods that rely on global image embeddings, IDUNet uses cross-attention between latent tokens and condition image tokens to enable patch-level interaction, preserving fine-grained details. This is combined with a Multi-view UNet, which performs a joint denoising process on the four-view latent representations. The UNet incorporates spatial self-attention to model cross-view relationships by reshaping the latent tokens, allowing the model to capture global consistency across the generated views. Condition features are constructed by concatenating the IDUNet output with CLIP-encoded image features, which are then introduced via cross-attention. To improve generation quality, the model is trained with a zero-sample-noise-ratio (SNR) approach at the final timestep, optimizing for velocity prediction. Pose canonicalization is achieved by jointly training the diffusion models with pose embeddings derived from OpenPose, which provide structural guidance to prevent layout misplacement and ensure the generated character adheres to anatomical constraints.
The second stage of the pipeline reconstructs a 3D character from the generated multi-view images. The authors adopt a transformer-based reconstruction network, inspired by LRM, which is pre-trained on a general object dataset and fine-tuned on their Anime3D dataset to capture character-specific priors. The reconstruction proceeds in two stages: first, a triplane NeRF representation is used to establish coarse geometry and appearance; then, the decoder is modified to predict signed distance functions (SDFs), enabling the generation of smoother and more precise surface geometry. This stage is supervised by a combination of MSE, mask, and LPIPS losses to ensure accurate shape and appearance reconstruction. The resulting mesh is further refined using Laplacian smoothing to reduce surface noise.
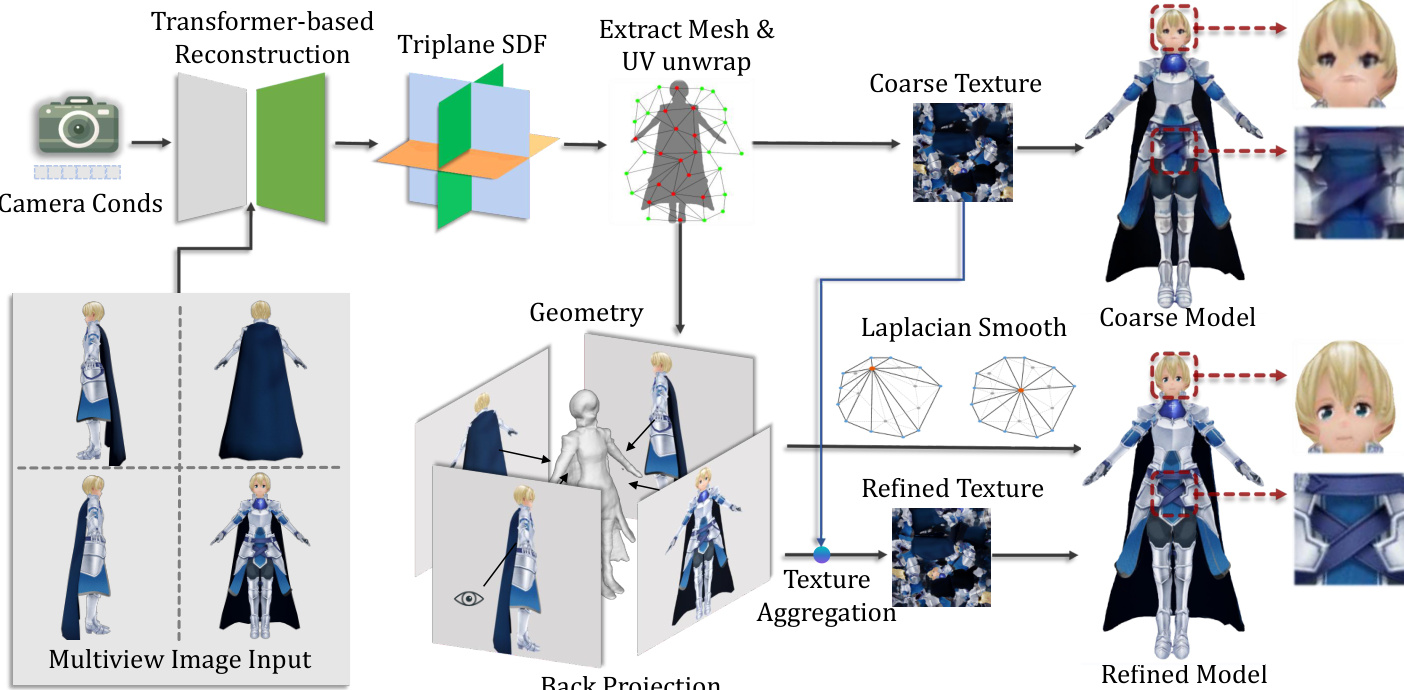
To enhance the texture quality, the framework employs a texture back-projection strategy. The generated high-resolution multi-view images are projected onto the coarse UV map of the reconstructed mesh. To mitigate noise from occlusion and overlapping texels during differentiable rendering, the system performs a depth test to remove occluded texels and discards texels near the silhouette using a normal-based filter. For overlapping texels, the RGB value closest to the coarse texture is selected. Finally, Poisson Blending is applied to aggregate the projected texels with the original texture, effectively reducing seams and producing a high-quality, refined texture map. This entire process results in a complete 3D character model ready for animation.
Experiment
The evaluation setup tests the model on 2D multi-view image generation and 3D mesh reconstruction by benchmarking against established baselines, conducting user preference studies, and performing component ablation to validate overall generation quality and architectural design choices. Qualitative assessments and user voting confirm that the framework effectively calibrates canonical poses, preserves spatial and appearance consistency across views, and produces clean meshes that avoid common artifacts like the Janus problem. Ablation experiments further demonstrate that jointly training the identity network and incorporating pose embedding are critical for accurate feature extraction and layout stability, while downstream application tests verify that the resulting A-pose characters seamlessly support automatic rigging and animation workflows.
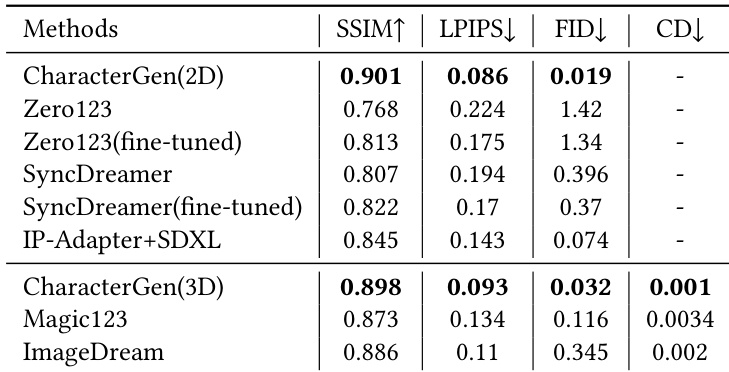
The authors evaluate their CharacterGen method against several baselines on both 2D multi-view image generation and 3D character generation tasks. Results show that CharacterGen achieves significantly higher performance in 2D style and multi-view consistency, as well as 3D geometry and texture quality, compared to other methods. The evaluation highlights the effectiveness of the proposed framework in generating consistent multi-view images and high-quality 3D models. CharacterGen outperforms other methods in 2D multi-view style consistency and 3D character geometry and texture quality. CharacterGen achieves superior performance in both 2D and 3D generation tasks compared to baselines like Zero123 and ImageDream. The method demonstrates high consistency in generating multi-view images and robust 3D character reconstruction, leading to better downstream applications.

The authors evaluate their CharacterGen method through quantitative metrics and user studies, comparing it against several baseline models for both 2D multi-view image generation and 3D character generation. Results show that CharacterGen achieves higher quality and consistency in generating images and 3D models, with superior performance in style and appearance similarity to input conditions. CharacterGen outperforms baseline methods in both 2D and 3D generation tasks according to quantitative metrics. CharacterGen demonstrates superior style consistency and appearance modeling compared to other methods. The user study confirms that CharacterGen is preferred over alternatives for both 2D and 3D generation tasks.

The authors evaluate their CharacterGen method on both 2D multi-view image generation and 3D character generation tasks, comparing it against several baseline models. Results show that CharacterGen achieves superior performance in generating consistent multi-view images and high-quality 3D character meshes, with notable improvements in geometric and textural fidelity compared to other methods. The user study and quantitative metrics further support its effectiveness and robustness. CharacterGen outperforms baseline methods in generating consistent multi-view images and high-quality 3D character meshes. The method demonstrates superior geometric and textural fidelity, particularly in handling complex character poses. User studies and quantitative metrics confirm the robustness and effectiveness of CharacterGen in both 2D and 3D generation tasks.
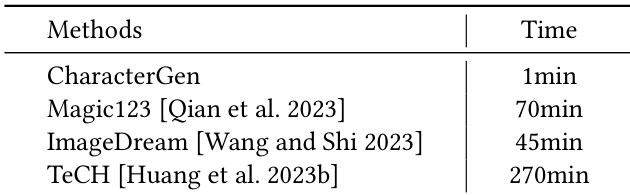
The authors compare the generation speed of their method with other image-prompt 3D character generation approaches, showing that their method completes the process significantly faster than alternatives. The results demonstrate that CharacterGen achieves efficient 3D character generation while maintaining high consistency and quality across multi-view images and reconstructed meshes. CharacterGen generates 3D characters faster than other image-prompt methods. The method produces consistent multi-view images and high-quality 3D meshes. It outperforms alternatives in both speed and visual quality for character generation tasks.
The authors evaluate CharacterGen against multiple baseline models for both 2D multi-view image generation and 3D character reconstruction, assessing performance through quantitative metrics and user studies. These experiments validate the framework's ability to maintain strong style consistency, accurate multi-view alignment, and high geometric and textural fidelity, particularly across complex character poses. User feedback and efficiency benchmarks further confirm that the method delivers superior visual quality and significantly faster generation speeds compared to existing approaches. Ultimately, the results establish CharacterGen as a robust and highly effective solution for producing consistent, high-quality 3D characters from single image prompts.