Command Palette
Search for a command to run...
Quick Back-Translation for Unsupervised Machine Translation
Quick Back-Translation for Unsupervised Machine Translation
Benjamin Brimacombe Jiawei Zhou
Quick Deployment of ChatGLM2-6b-32k
Abstract
The field of unsupervised machine translation has seen significant advancement from the marriage of the Transformer and the back-translation algorithm. The Transformer is a powerful generative model, and back-translation leverages Transformer's high-quality translations for iterative self-improvement. However, the Transformer is encumbered by the run-time of autoregressive inference during back-translation, and back-translation is limited by a lack of synthetic data efficiency. We propose a two-for-one improvement to Transformer back-translation: Quick Back-Translation (QBT). QBT re-purposes the encoder as a generative model, and uses encoder-generated sequences to train the decoder in conjunction with the original autoregressive back-translation step, improving data throughput and utilization. Experiments on various WMT benchmarks demonstrate that a relatively small number of refining steps of QBT improve current unsupervised machine translation models, and that QBT dramatically outperforms standard back-translation only method in terms of training efficiency for comparable translation qualities.
One-sentence Summary
The authors propose Quick Back-Translation (QBT), an unsupervised machine translation method that repurposes the Transformer encoder as a generative model to train the decoder alongside standard autoregressive back-translation, thereby enhancing data throughput and training efficiency while maintaining comparable translation quality across WMT benchmarks.
Key Contributions
- Quick Back-Translation (QBT) repurposes the Transformer encoder as a non-autoregressive generative model to produce synthetic sequences for decoder training alongside standard autoregressive back-translation.
- The method inverts conventional knowledge distillation by leveraging a bidirectional encoder to generate training data for a strong autoregressive decoder, thereby increasing synthetic data throughput and utilization.
- Experiments across multiple WMT benchmarks demonstrate that QBT significantly improves training efficiency over standard back-translation while maintaining comparable translation quality with only a few refining steps.
Introduction
Unsupervised machine translation enables neural models to learn cross-lingual mappings from monolingual corpora alone, making automated translation viable for low-resource languages where curated parallel datasets are unavailable. Existing approaches primarily rely on iterative back-translation with autoregressive decoders, which generate tokens sequentially and become computationally expensive for longer texts, while also facing persistent challenges in maintaining sufficient synthetic data diversity. The authors leverage the Transformer encoder as a standalone non-autoregressive model to rapidly generate synthetic translations, introducing a dual-phase distillation framework that injects highly diverse signals directly into the decoder. This strategy preserves the standard encoder-decoder architecture while delivering substantial training speedups and competitive translation quality, particularly for long sequences.
Dataset
- Dataset composition and sources: The authors do not provide dataset composition or source information in the submitted text.
- Key details for each subset: The authors do not specify subset sizes, sources, or filtering rules.
- How the paper uses the data: The authors do not describe training splits, mixture ratios, or data usage workflows.
- Processing details: The authors do not outline cropping strategies, metadata construction, or other preprocessing steps.
Method
The proposed Quick Back-Translation (QBT) framework restructures the standard back-translation pipeline by repurposing the Transformer encoder as a non-autoregressive (NAR) generative model, thereby enabling faster and more efficient data utilization. The overall architecture integrates three key components: Encoder Back-Translation (EBT), Encoder Back-Translated Distillation (EBTD), and standard Back-Translation (BT), which are applied either in a synchronized or staged manner depending on the training objective. As shown in the figure below, the framework begins with a standard Transformer encoder-decoder setup, where the encoder processes the input sequence in a bidirectional manner and the decoder generates output autoregressively. The core innovation lies in modifying this process to leverage the encoder's ability to generate translations directly, eliminating the bottleneck of autoregressive inference during synthetic data generation.
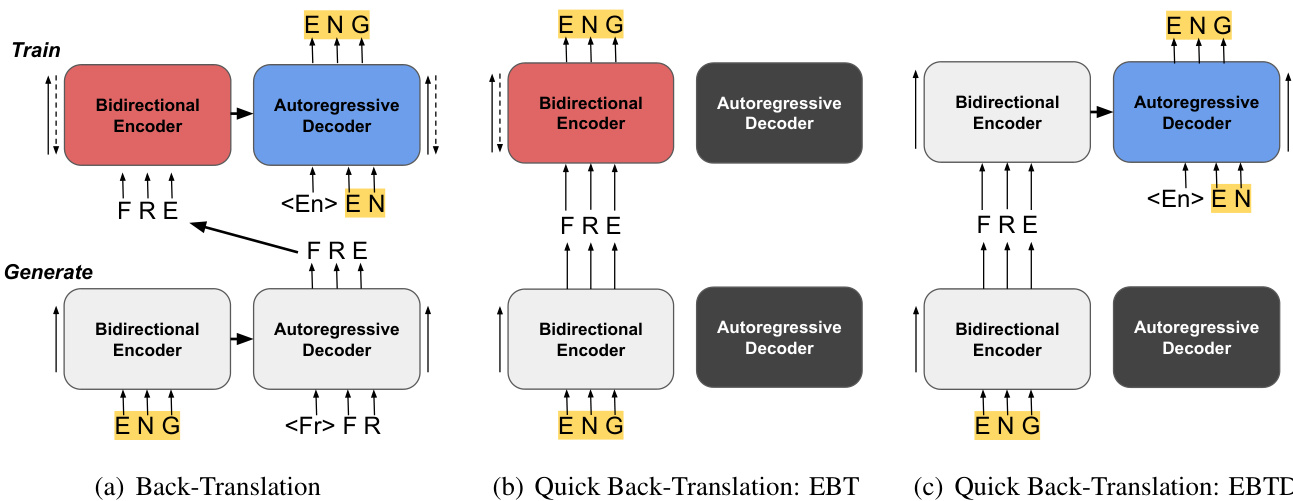
The first component, Encoder Back-Translation (EBT), is designed to train the encoder to perform translation in a non-autoregressive fashion. In this phase, the encoder is used to generate source sequences from target sequences, effectively treating it as a stripped-down NAR model. The generated sequences are then used as synthetic parallel data to update the encoder parameters and embeddings. This process is applied iteratively in both translation directions, alternating between source-to-target and target-to-source generation, thereby aligning the encoder with translation objectives. The resulting encoder can then serve as a fast generator of synthetic data for subsequent training steps.
The second component, Encoder Back-Translated Distillation (EBTD), leverages the encoder's output to improve the decoder. In this step, the encoder is used to generate source sequences from target sequences, and these pairs are then fed into the full encoder-decoder model. The decoder is trained to predict the original target sequences using the encoder-generated source as input, with the encoder parameters frozen to preserve the quality of its translations. This distillation process injects diverse training signals into the decoder, enhancing its generative capability without relying on the slow autoregressive sampling of standard back-translation.
The final component, standard Back-Translation (BT), is used to fine-tune the full model and ensure high-quality translations. It operates in the traditional manner, using the decoder to generate synthetic target sequences from source sequences, which are then used to supervise the encoder-decoder model. The QBT framework combines these components in two configurations: QBT-Synced, where EBT and EBTD are applied synchronously after the model has converged under standard BT training to boost performance, and QBT-Staged, where the components are applied in sequence during training from scratch to gradually build translation capability in the encoder and decoder. This staged approach ensures that the encoder first acquires basic translation skills before being used to generate high-quality synthetic data for the decoder.
Experiment
Evaluated across standard WMT benchmarks and a programming language task, the study tests the proposed synchronized and staged back-translation frameworks under large-scale, resource-constrained, and long-sequence conditions. The large-scale trials validate the method's capacity to consistently refine existing models with minimal computational overhead, while the limited-resource and long-sequence experiments confirm its superior training efficiency and convergence stability. Qualitative assessments and representation alignment analysis further demonstrate that the approach effectively prevents syntactic degradation and strengthens encoder-decoder consistency. Ultimately, the findings establish that repurposing the encoder for back-translation provides a robust, highly scalable alternative to traditional baselines across diverse translation tasks.
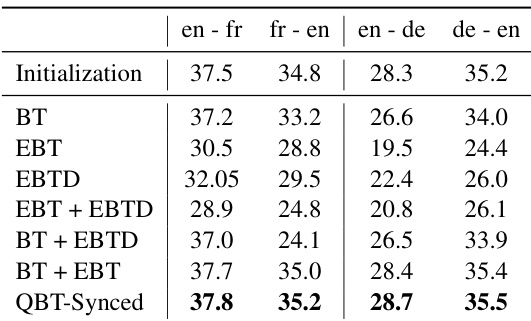
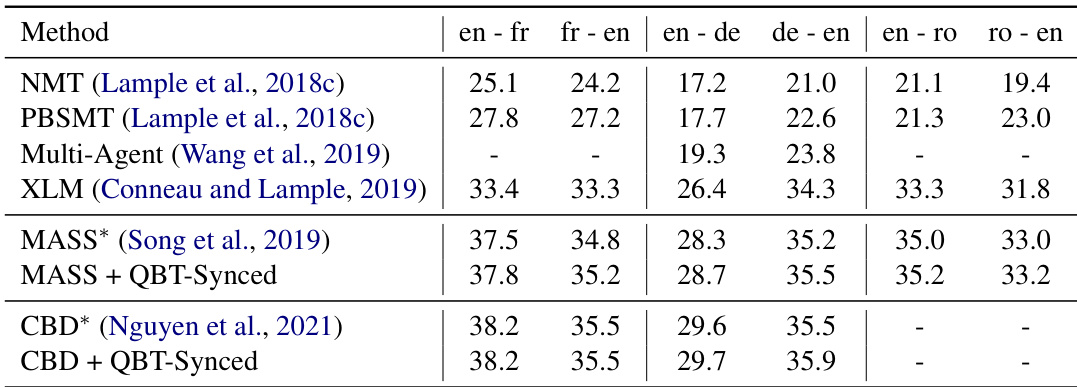
The authors evaluate their proposed QBT-Synced method on unsupervised machine translation tasks using the WMT datasets, comparing it against baseline models initialized with pre-trained UMT checkpoints. Results show that the method achieves consistent improvements across different language pairs, particularly in the English-French and English-German directions, with enhancements over the baseline models. QBT-Synced improves baseline performance on multiple language pairs, showing gains in both English-French and English-German translation. The method consistently outperforms the original UMT model across different translation directions, indicating robust improvements. The improvements are most notable in the English-French direction, where the proposed method achieves higher scores than the baseline.
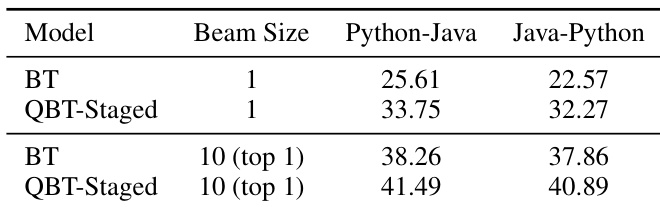
The authors evaluate their proposed QBT-Staged method on unsupervised programming language translation tasks, comparing it against a baseline BT approach. Results show that QBT-Staged achieves higher BLEU scores than the baseline across both Python-Java and Java-Python directions, with improvements becoming more pronounced at higher beam sizes. The method demonstrates consistent gains when using larger beam sizes for decoding. QBT-Staged outperforms the baseline BT model in both programming language translation directions. The performance gap between QBT-Staged and the baseline increases with higher beam sizes. QBT-Staged achieves higher BLEU scores than the baseline for both Python-Java and Java-Python translations.
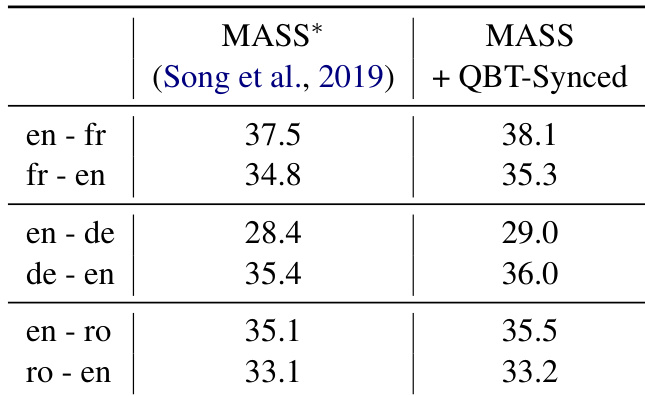
The authors evaluate their proposed QBT-Synced method on unsupervised machine translation tasks using WMT datasets, comparing it against various baselines and ablations. Results show that the QBT-Synced approach consistently achieves competitive or improved performance across language pairs, with notable gains in certain configurations. The method demonstrates effectiveness in both large-scale and limited-resource settings, and its efficiency is highlighted through faster training and improved data throughput. QBT-Synced achieves the best performance across all language pairs, outperforming or matching other methods including BT, EBT, and EBTD combinations. The QBT-Synced method shows consistent improvements over the initialization, particularly in the English-French and English-German directions. The approach is effective in both large-scale and limited-resource scenarios, demonstrating robustness and efficiency in training and inference.
The authors compare their proposed QBT-Synced method with existing unsupervised machine translation approaches on multiple language pairs, using BLEU scores as the evaluation metric. Results show that QBT-Synced achieves competitive performance, particularly when fine-tuning pre-trained models, with improvements over baseline methods in several translation directions. The method consistently outperforms or matches the performance of established models across different language pairs. QBT-Synced improves upon baseline models in multiple translation directions, showing consistent gains across language pairs. The proposed method achieves comparable or better performance than state-of-the-art models, particularly in English-German and English-Romanian translations. QBT-Synced maintains strong performance when applied to pre-trained models without prior back-translation tuning, indicating its effectiveness in low-resource settings.
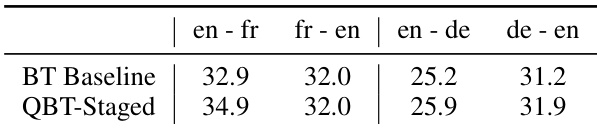
The authors evaluate their proposed QBT-Staged method on unsupervised machine translation tasks, comparing it to a BT baseline across multiple language pairs. Results show that QBT-Staged consistently outperforms the BT baseline, with improvements observed in both directions of translation. The method demonstrates robust performance across different language pairs and achieves higher scores on all evaluated tasks. QBT-Staged outperforms the BT baseline on all language pairs. The improvement is consistent across both translation directions for each language pair. QBT-Staged achieves higher BLEU scores compared to the baseline in all evaluated tasks.
The authors evaluate their proposed QBT-Synced and QBT-Staged methods on unsupervised machine translation and programming language translation tasks, comparing them against established baseline models across multiple language pairs. Experimental results demonstrate that both approaches consistently outperform or match existing methods, with QBT-Synced delivering robust quality improvements and training efficiency in both large-scale and low-resource settings. Meanwhile, QBT-Staged shows reliable gains in bidirectional code translation, with performance scaling positively under higher decoding beam sizes. Overall, the findings validate the effectiveness of the proposed synchronization and staged strategies for enhancing the stability and quality of unsupervised translation systems.