Command Palette
Search for a command to run...
One-click Deployment of MedGemma-27b-text-it Medical Reasoning LLM
Abstract
One-sentence Summary
The authors introduce an analysis framework that systematically evaluates AI bias in medical imaging by training a convolutional neural network (CNN) classifier on synthetic neuroimages with known disease and bias effects, enabling objective assessment of mitigation strategies in counterfactual data scenarios where reweighing proved most effective and explainable AI methods aided in investigating bias manifestations.
Key Contributions
- This work introduces a structured analysis framework that leverages synthetic three-dimensional neuroimages with known disease effects and controllable bias sources to systematically investigate how spurious correlations manifest in deep learning models. Ground-truth knowledge of injected biases enables objective measurement of mitigation efficacy without relying on unidentifiable clinical confounders.
- The methodology evaluates controlled bias impacts and systematically tests three bias mitigation strategies using counterfactual data scenarios on a convolutional neural network classifier. This experimental design isolates model learning behaviors from unknown real-world confounders to ensure reproducible benchmarking.
- Experimental results demonstrate that training on biased datasets produces expected subgroup performance disparities and identify reweighing as the most effective mitigation strategy for this configuration. The framework further shows that explainable artificial intelligence methods can effectively trace learned bias attributes within model decision-making processes.
Introduction
Artificial intelligence for medical imaging is increasingly deployed to assist clinical decision-making, but biased training data often causes models to perform unevenly across patient subgroups, threatening diagnostic fairness and patient safety. Evaluating these disparities and testing mitigation strategies remains difficult because real-world imaging datasets contain complex, uncontrolled spurious correlations that are nearly impossible to isolate. While simple benchmark datasets allow researchers to study intentional biases in controlled settings, they lack the anatomical scale and complexity of clinical 3D scans. To bridge this gap, the authors introduce a structured framework that combines the customizable control of benchmark datasets with the realistic dimensions of 3D medical imaging. This methodology enables researchers to systematically trace how hidden biases manifest in deep learning pipelines and objectively validate the robustness of fairness mitigation techniques prior to clinical adoption.
Dataset

• Dataset Composition and Sources: The authors generate synthetic T1-weighted brain MRI scans using the SimBA framework. The base template is the SRI24 atlas annotated with LPBA40 labels, featuring a 173 by 211 by 155 voxel grid at 1 mm isotropic resolution. All morphological variations are derived from principal component analysis models trained on stationary velocity fields from 50 real T1-weighted MRIs from the IXI database, which were non-linearly registered to the atlas.
• Subset Details and Structure: Each generated dataset contains 2002 three-dimensional images divided into two target classes: disease (1000 images) and non-disease (1002 images). These are further split into two bias groups based on the presence of an additional localized morphological effect. The bias group comprises 70% of the disease class and 30% of the non-disease class. The authors create three paired scenarios to act as counterfactuals: a no-bias condition, a near-bias condition where the effect targets the left putamen adjacent to the disease region, and a far-bias condition where the effect targets the right postcentral gyrus in the opposite hemisphere.
• Data Usage and Training Setup: The synthetic images train a convolutional neural network to predict disease status. The deliberate imbalance in bias representation is designed to evaluate whether deep learning models exploit the bias effect as a predictive shortcut. To ensure fair evaluation across scenarios, the authors maintain identical subject and disease effects within each paired dataset and apply stratified sampling to keep the magnitude distributions of subject and disease effects consistent across all classes and bias groups.
• Processing and Metadata Construction: Disease status is encoded by applying localized deformations to the left insular cortex. Global brain morphology varies uniquely for each simulated subject through non-linear deformations. The authors pre-stratify the sampling distributions to prevent effect magnitude from introducing confounding variables. All generated datasets, along with the train, validation, and test splits, are provided publicly alongside the generation code.
Method
The authors leverage a systematic analysis framework to investigate the impact of biases in medical imaging AI models, using synthetic neuroimages generated with the Simulated Bias in Artificial Medical Images (SimBA) tool. This framework enables controlled in silico trials by introducing user-defined biases into structured neuroimaging datasets, allowing for the evaluation of how such biases affect deep learning pipelines. The core of the methodology centers on generating counterfactual subject-paired synthetic datasets that either contain known biases in specific spatial regions of the brain or are free from bias altogether. These datasets are then used to train a convolutional neural network (CNN) classifier under identical conditions, enabling a direct assessment of bias effects on model performance across different subgroups.
As shown in the figure below: the overall pipeline begins with the generation of synthetic neuroimages using SimBA, which allows for precise control over bias introduction. The generated datasets are then used to train a CNN classifier, with the model architecture consisting of a feature encoder and a final dense classification layer. The training process is consistent across all experimental conditions, ensuring that any observed differences in performance can be attributed to the presence or absence of bias.
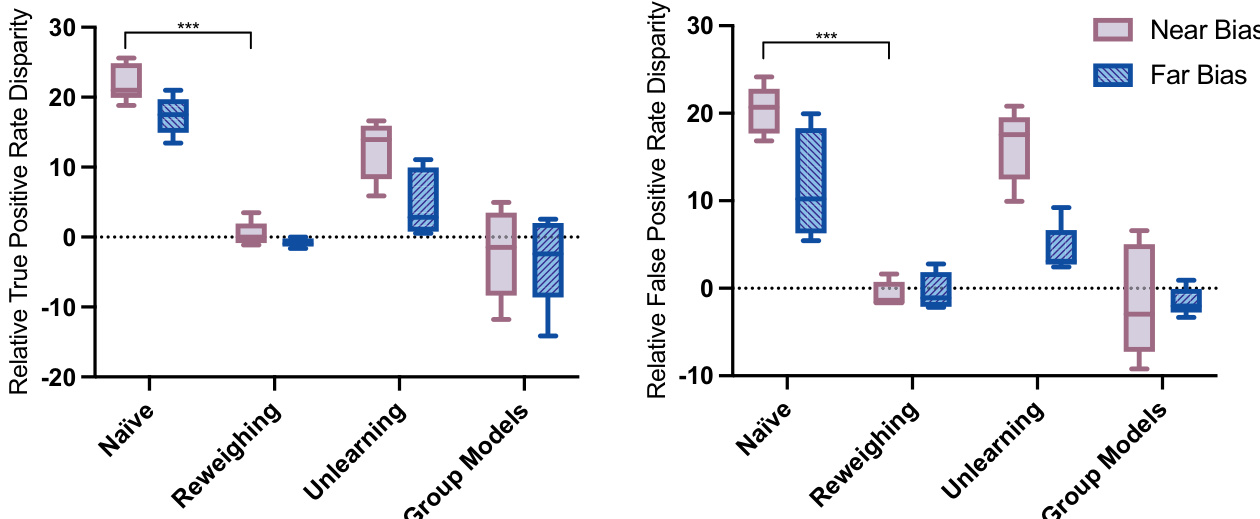
To evaluate the effectiveness of bias mitigation strategies, three distinct approaches are applied. Reweighing is implemented as proposed by Calders et al., where sample weights are adjusted based on the combination of bias group and disease class. This method aims to balance the influence of different subgroups during training, thereby reducing the model's reliance on biased features. The second approach, bias unlearning, follows the method described by Dinsdale et al. This technique involves training a dual-headed CNN, with one head for disease classification and another for bias group prediction. After initial convergence of the disease classification head, the bias prediction head is trained, and the model undergoes an iterative process where the loss for disease prediction is minimized while the loss for bias prediction is maximized. This forces the feature encoder to disentangle the bias-related features from the disease-related features, effectively unlearning the bias. The third strategy, the bias group model approach, involves pre-training the CNN on the full dataset and then training separate models on the bias and non-bias subgroups. Performance metrics such as accuracy, true positive rates, and false positive rates are computed for each subgroup model, and their differences are used to quantify subgroup performance disparities.
Experiment
The study utilizes a controlled counterfactual framework with simulated neuroimaging datasets to systematically evaluate how spatially localized morphological biases influence deep learning models and to test the efficacy of various mitigation strategies. Experimental results demonstrate that introduced bias triggers significant subgroup performance disparities by encouraging shortcut learning, with these effects weakening when bias regions are positioned farther from the target disease features. Comparative testing reveals that reweighing successfully eliminates performance gaps, while unlearning fails to disentangle bias from diagnostic features and group models exhibit disparities driven by class imbalance rather than the simulated bias. By aligning model explainability outputs with these controlled outcomes, the framework establishes a rigorous, objective baseline for assessing algorithmic bias and mitigation strategies before real-world deployment.
The authors evaluate the impact of simulated morphological bias on a CNN model's performance across different bias scenarios and assess the effectiveness of bias mitigation strategies. Results show that bias presence leads to significant performance disparities, with mitigation methods varying in their ability to reduce these disparities, and explainability analysis supports the model's reliance on bias-related features. Bias presence significantly increases performance disparities compared to the no bias scenario, with larger disparities observed when bias is closer to the disease region. Reweighting effectively mitigates performance disparities, while unlearning and group models show limited or inconsistent effectiveness. Saliency analysis reveals that models rely on bias-related regions for predictions, and the explainability results align with the observed performance outcomes.
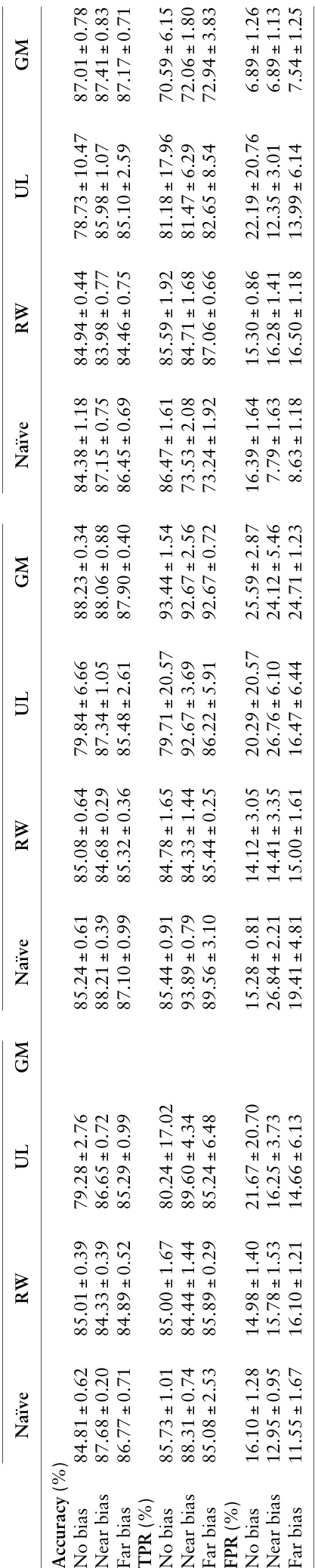
The experiments evaluate how simulated morphological bias affects a convolutional neural network and test various strategies to reduce its impact. Introducing bias creates notable performance disparities that intensify when located near disease regions, a pattern confirmed by explainability analysis showing the model relies heavily on these biased features. Among the tested interventions, reweighting successfully narrows performance gaps, while unlearning and group-based approaches yield limited or inconsistent improvements. Overall, the study demonstrates that morphological bias substantially compromises model reliability and identifies reweighting as the most effective mitigation strategy.