Command Palette
Search for a command to run...
GAN Using the MedNIST Dataset
Abstract
One-sentence Summary
This work presents a combined Pix2Pix and CycleGAN framework that colorizes Fakemon line art using automatic color hint extraction and specialized anime-style training, producing feasible visual results that indicate room for further improvement.
Key Contributions
- The work proposes novel algorithms for adaptive line art extraction and automatic color hint generation to automate the colorization process for anime-style illustrations.
- This study introduces a hybrid architecture that merges the outputs of Pix2Pix and CycleGAN to produce a single colorized image, marking the first integration of these generative adversarial networks for this task.
- The methodology is trained and evaluated specifically on Fakemon line art, establishing the first automated colorization framework for monster-like creatures while demonstrating feasible visual outputs.
Introduction
The authors tackle automated line art colorization, a vital step for streamlining 2D asset production in digital games and animation. While deep learning has largely replaced manual optimization techniques, existing GAN-based pipelines still face notable bottlenecks. Prior methods typically depend on manually defined color palettes, struggle with high-resolution inputs due to memory and training constraints, and frequently generate visual artifacts like repeating color patterns. Additionally, most existing models are trained on humanoid characters rather than fantasy creatures, and they lack mechanisms for automatic color hint extraction. To address these gaps, the authors propose a fully automated pipeline that extracts both line art and color hints directly from source images. They train the system specifically on anime-style monster designs and introduce a novel architecture that merges Pix2Pix and CycleGAN outputs into a single, refined colorization result.

Dataset
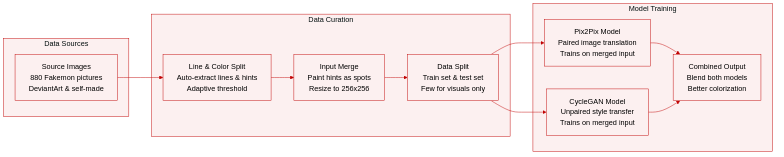
- The authors collected 880 colorized images of Fakemon characters primarily from DeviantArt, supplemented by a few self-created examples. All selected works carry Creative Commons licenses, and the authors explicitly note they do not hold copyright to the characters.
- The full collection is partitioned into a training set and a held-out test subset. A small number of images were reserved exclusively for result visualization and excluded from the training pipeline.
- The dataset trains both Pix2Pix and CycleGAN architectures for automatic colorization. Because of the limited scale, the authors combine both models to improve output quality, framing the task as a specialized image-to-image translation and style transfer problem.
- Line art and color hints are automatically extracted using a custom adaptive threshold algorithm that dynamically adjusts tolerance based on character pixel density. The authors manually verify and refine a few extracted line arts, though this step is noted as unnecessary for real-world workflows. Instead of separate inputs or palettes, the extracted color hints are painted onto the line art as circular spots, forming a single composite input image. All images are standardized to a 256x256 resolution, with no cropping applied.
Method
The authors leverage a hybrid approach combining Pix2Pix and CycleGAN for line art colorization, building upon established image-to-image translation frameworks. The core of the method relies on the Pix2Pix framework, which employs a conditional generative adversarial network (cGAN) architecture. In this setup, a U-Net-based generator produces colorized images from input line art, while a PatchGAN discriminator evaluates the realism of the generated outputs. The generator and discriminator are trained jointly, with the generator minimizing a loss function that encourages the production of realistic, colorized images that are indistinguishable from real examples. This framework enables structured learning, where the classification of pixel values propagates across neighboring regions, allowing for coherent colorization that respects spatial relationships in the input.
The process begins with the extraction of line art from the original artwork using an adaptive thresholding algorithm. This algorithm converts the input image to grayscale, constructs a histogram, and determines a threshold value based on the average pixel intensity and a user-defined tolerance parameter. The threshold is applied to generate a binary image that isolates the line art. Following this, color hints are automatically extracted using a two-stage k-Medoid clustering approach. In the first stage, k-Medoid clustering is applied with k=35 to quantize the image into a maximum of 35 distinct colors, using a custom distance function that emphasizes hue and saturation differences while ignoring spatial coordinates. This step reduces color complexity and prepares the image for further processing.
The second stage refines the color hint set by applying k-Medoid clustering again with k=10 and a Euclidean distance metric that incorporates color (r, g, b) and spatial (x, y) information equally. This results in ten uniformly spaced color hints, each represented as a circular spot of radius 15 pixels. These color hints serve as the guidance for the colorization process, providing the generator with key color information without requiring extensive manual input. The resulting color hints are combined with the line art to form the input pair for the image-to-image translation models.
While Pix2Pix is the primary framework used for colorization, CycleGAN is also evaluated and incorporated in certain stages. Unlike Pix2Pix, which requires aligned input-output pairs, CycleGAN is designed for unpaired image-to-image translation and is better suited for style transfer. However, due to its unpaired nature, CycleGAN is not ideal for direct line art colorization but is used in combination with Pix2Pix to generate shaded and colorized outputs. The authors empirically adjust the generator and discriminator filter parameters (ngf and ndf) to 150, which improves performance without significantly affecting the overall result. This adjustment enhances the model's capacity to capture finer details in the colorization process. The combination of these components enables a robust and efficient pipeline for automated line art colorization with minimal user intervention.
Experiment
The experiments were conducted on a standard desktop GPU setup and evaluated primarily through human visual inspection rather than quantitative metrics. Pix2Pix demonstrated strong color fidelity and clean boundary adherence suitable for game art, while CycleGAN excelled at capturing tonal variation and subtle shading effects. Combining both models through a division blend mode successfully integrated their respective strengths to produce softer, more balanced results. Although manually adding color hints to Pix2Pix yielded minor localized improvements, the overall qualitative gains remained modest, confirming that the automated approaches provide viable baseline colorization for creative applications.