Command Palette
Search for a command to run...
Zero-shot Text Classification Using Hugging Face
Abstract
One-sentence Summary
DetectLLM introduces two zero-shot detection methods, DetectLLM-LRR and DetectLLM-NPR, that leverage log rank information to optimize for speed and accuracy respectively, achieving absolute AUROC improvements of 3.9 and 1.75 points over the state of the art across three datasets and seven language models while requiring fewer perturbations than prior approaches.
Key Contributions
- This paper introduces DetectLLM-LRR and DetectLLM-NPR, two zero-shot methods that detect machine-generated text by leveraging log rank information. DetectLLM-LRR optimizes for rapid inference, while DetectLLM-NPR improves accuracy through targeted perturbations of the underlying log probability distribution.
- Experiments across three datasets and seven language models show that DetectLLM-LRR and DetectLLM-NPR surpass existing baselines by 3.9 and 1.75 AUROC points, respectively. The perturbation-based approach also achieves comparable detection performance with fewer perturbations than prior techniques, lowering practical computational costs.
- The work analyzes the efficiency-performance trade-offs between the two pipelines, providing practical deployment guidelines for zero-shot detectors based on specific speed or accuracy requirements.
Introduction
The rapid proliferation of large language models has created a pressing need to automatically distinguish human-written content from AI-generated text, as unchecked misuse threatens academic integrity and spreads misinformation across digital platforms. Previous detection methods typically rely on supervised black-box classifiers that require expensive retraining for new models, while existing zero-shot approaches either sacrifice accuracy or demand prohibitive computational costs through extensive perturbation. To overcome these barriers, the authors leverage log rank statistics to propose DetectLLM, a framework containing two complementary zero-shot detectors. DetectLLM-LRR delivers rapid classification by combining log-likelihood with log-rank ratios, while DetectLLM-NPR improves detection accuracy using a perturbation strategy that converges faster than prior techniques. The authors validate their methods across multiple models and datasets, demonstrating consistent performance gains and offering practical guidance for balancing detection speed with accuracy.
Dataset

- Dataset Composition and Sources: The authors use three established datasets to represent domains where large language models may cause significant impact: XSum for news articles, SQuAD for Wikipedia paragraphs, and WritingPrompts for creative stories. Each subset provides human-written reference texts.
- Subset Details and Pairing: Every experiment relies on exactly 300 paired samples. Each pair consists of an original human-written passage alongside a corresponding machine-generated counterpart.
- Processing and Cropping Strategy: To standardize generation, the authors truncate each human text to its first 30 tokens and feed this prefix into the target LLM as the initial prompt. This controlled cropping ensures consistent context across all subsets.
- Data Usage and Reproducibility: The paired texts serve strictly as an evaluation benchmark rather than a training or mixing corpus. The complete synthetic data generation pipeline is implemented in open-source code and released alongside the paper to guarantee full reproducibility.
Method
The authors leverage two complementary zero-shot detection features—Log-Likelihood Log-Rank Ratio (LRR) and Normalized Perturbed Log-Rank (NPR)—to improve the identification of machine-generated text. These features are designed to capture different aspects of text generation patterns, particularly those that distinguish synthetic outputs from human-written content.
The Log-Likelihood Log-Rank Ratio (LRR) is defined as the absolute ratio of the average log-likelihood to the average log-rank over the sequence tokens. Specifically, it is computed as:
LRR=t1∑i=1tlogrθ(xi∣x<i)t1∑i=1tlogpθ(xi∣x<i)=−∑i=1tlogrθ(xi∣x<i)∑i=1tlogpθ(xi∣x<i),where pθ(xi∣x<i) denotes the model’s predicted probability for token xi given the preceding context, and rθ(xi∣x<i)≥1 represents the rank of the token under the same condition. The numerator captures the absolute confidence of the model in generating the correct token, while the denominator reflects the relative confidence, emphasizing how well the correct token is ranked among the vocabulary. This combination allows LRR to leverage both global confidence (log-likelihood) and positional confidence (log-rank), providing a more robust signal. As shown in the figure below, machine-generated texts typically exhibit higher LRR values due to their tendency to produce tokens with lower log-likelihoods but more discernible log-ranks, making LRR an effective discriminative feature. The zero-shot detection method based on LRR is referred to as DetectLLM-LRR.
Experiment
The experiments evaluate the proposed LRR and NPR zero-shot detection methods against established baselines across varying LLM sizes, decoding strategies, and perturbation configurations. These tests validate how detection accuracy scales with perturbation quantity and model size, how generation settings like temperature and sampling strategy influence performance, and the inherent trade-off between detection precision and computational cost. Qualitatively, NPR consistently outperforms comparable perturbation-based detectors by achieving higher accuracy with significantly fewer perturbations, while the perturbation-free LRR method often matches or exceeds perturbation-based performance, particularly under low-temperature generation. Ultimately, the findings demonstrate that both methods achieve state-of-the-art results within their categories and provide actionable guidance for balancing efficiency and accuracy based on resource constraints.
The authors analyze the performance of zero-shot text detection methods under various conditions, including different decoding strategies and temperatures. Results show that certain perturbation-free methods achieve high performance comparable to or exceeding perturbation-based methods, particularly in low-temperature scenarios. The efficiency of these methods varies significantly, with perturbation-free approaches being substantially faster than those requiring multiple perturbations. Perturbation-free methods can achieve performance comparable to or better than perturbation-based methods, especially under low temperature settings. Perturbation-based methods are significantly more computationally expensive than perturbation-free methods due to the need for multiple perturbations. Different decoding strategies and temperatures have varying impacts on method performance, with some methods showing stability across conditions.
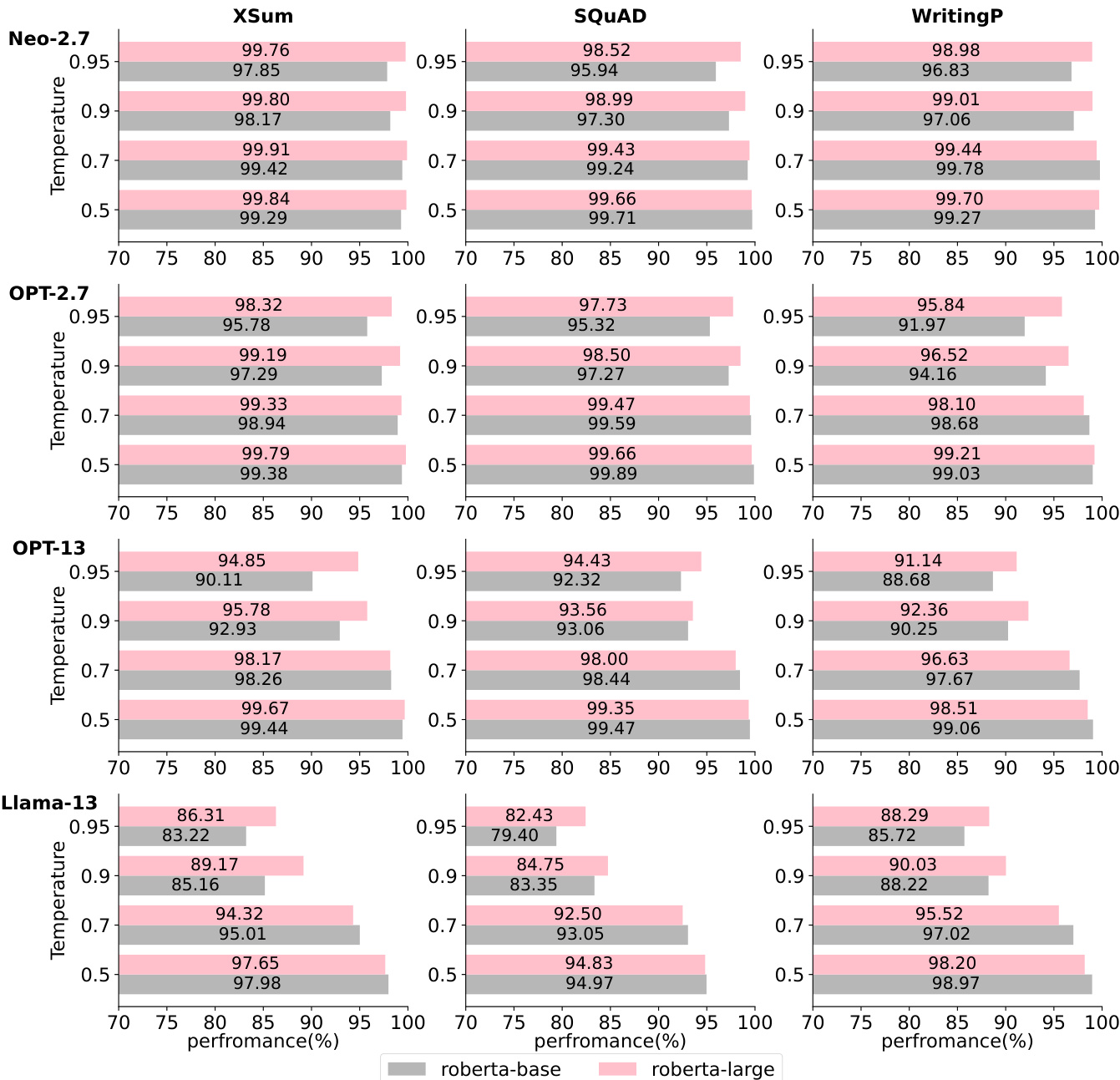
The authors evaluate various zero-shot methods for detecting machine-generated text, comparing perturbation-based and perturbation-free approaches across different language models and datasets. Results show that the proposed method, NPR, consistently outperforms DetectGPT in perturbation-based methods, while the proposed LRR method achieves strong performance among perturbation-free methods, often surpassing perturbation-based methods under certain conditions. NPR consistently outperforms DetectGPT across all datasets and models in perturbation-based methods. LRR achieves the best performance among perturbation-free methods and can outperform perturbation-based methods on certain datasets and conditions. The proposed methods show varying sensitivity to temperature and decoding strategies, with LRR being stable across different decoding strategies.
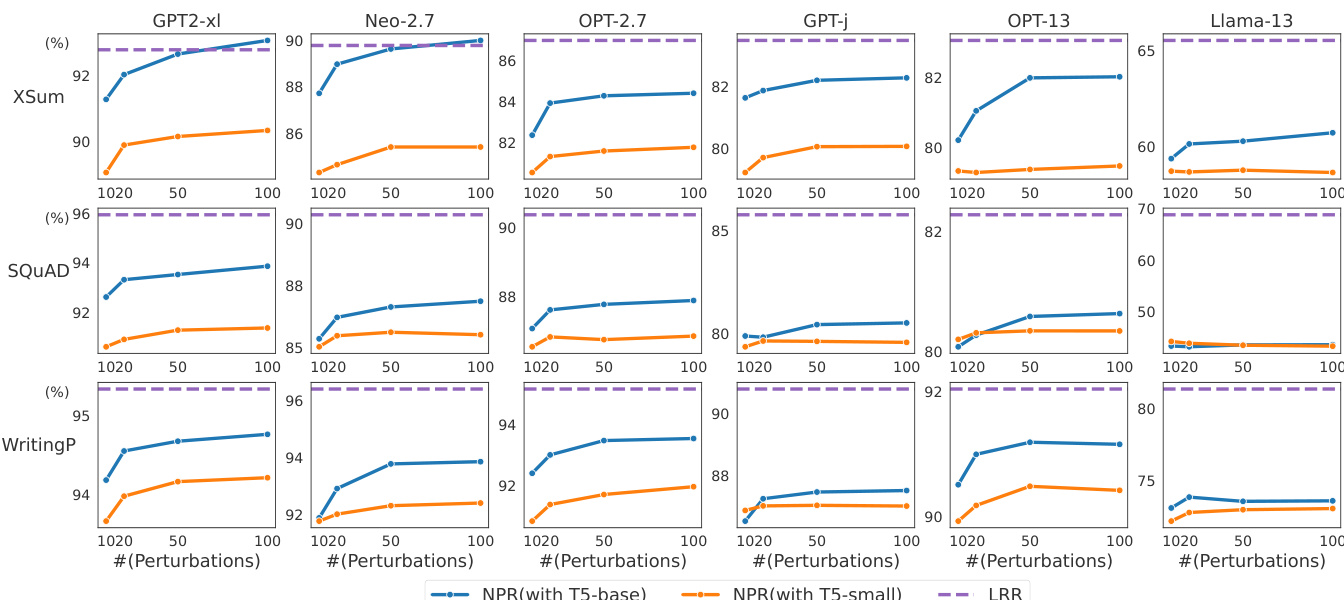
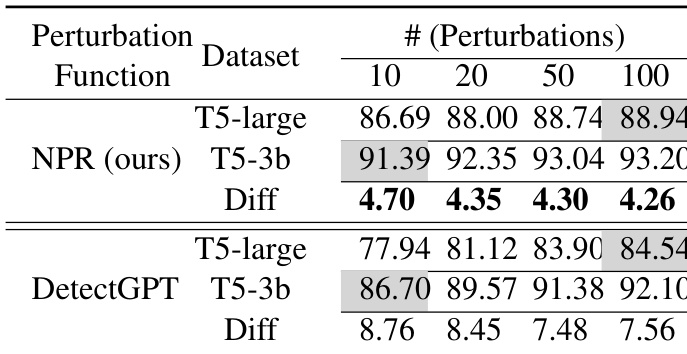
The authors compare the performance of their proposed methods, NPR and LRR, with existing zero-shot detection methods under varying conditions. Results show that NPR consistently outperforms DetectGPT across different numbers of perturbations and perturbation functions, while LRR achieves competitive performance with lower computational cost. The analysis highlights trade-offs between performance and efficiency, particularly in terms of the number of perturbations and the size of the perturbation function used. NPR consistently outperforms DetectGPT across different numbers of perturbations and perturbation functions. LRR achieves competitive performance with lower computational cost compared to perturbation-based methods. The performance of perturbation-based methods is sensitive to the size of the perturbation function, with larger functions yielding better results.
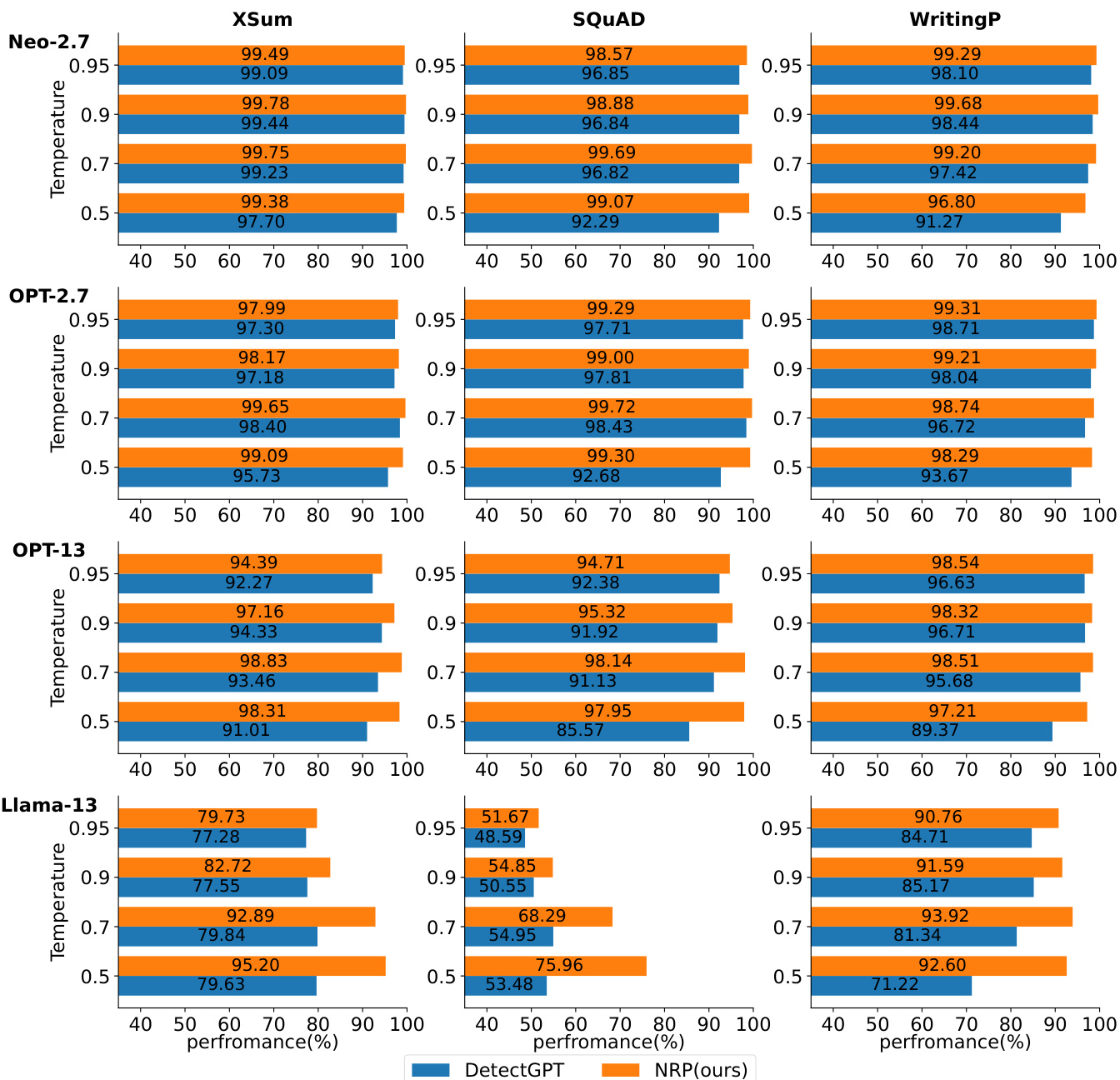
The authors compare their proposed methods, LRR and NPR, with existing zero-shot detection approaches across multiple datasets and LLMs. Results show that LRR consistently achieves high performance among perturbation-free methods, often outperforming some perturbation-based methods, while NPR consistently outperforms DetectGPT in perturbation-based settings. The study also highlights that LRR offers a strong balance of performance and efficiency, requiring significantly fewer computational resources than perturbation-based methods. LRR achieves top performance among perturbation-free methods, outperforming DetectGPT and other baselines on several datasets. NPR consistently outperforms DetectGPT across all datasets and LLMs in perturbation-based detection. LRR provides high detection accuracy with significantly lower computational cost compared to perturbation-based methods like NPR and DetectGPT.
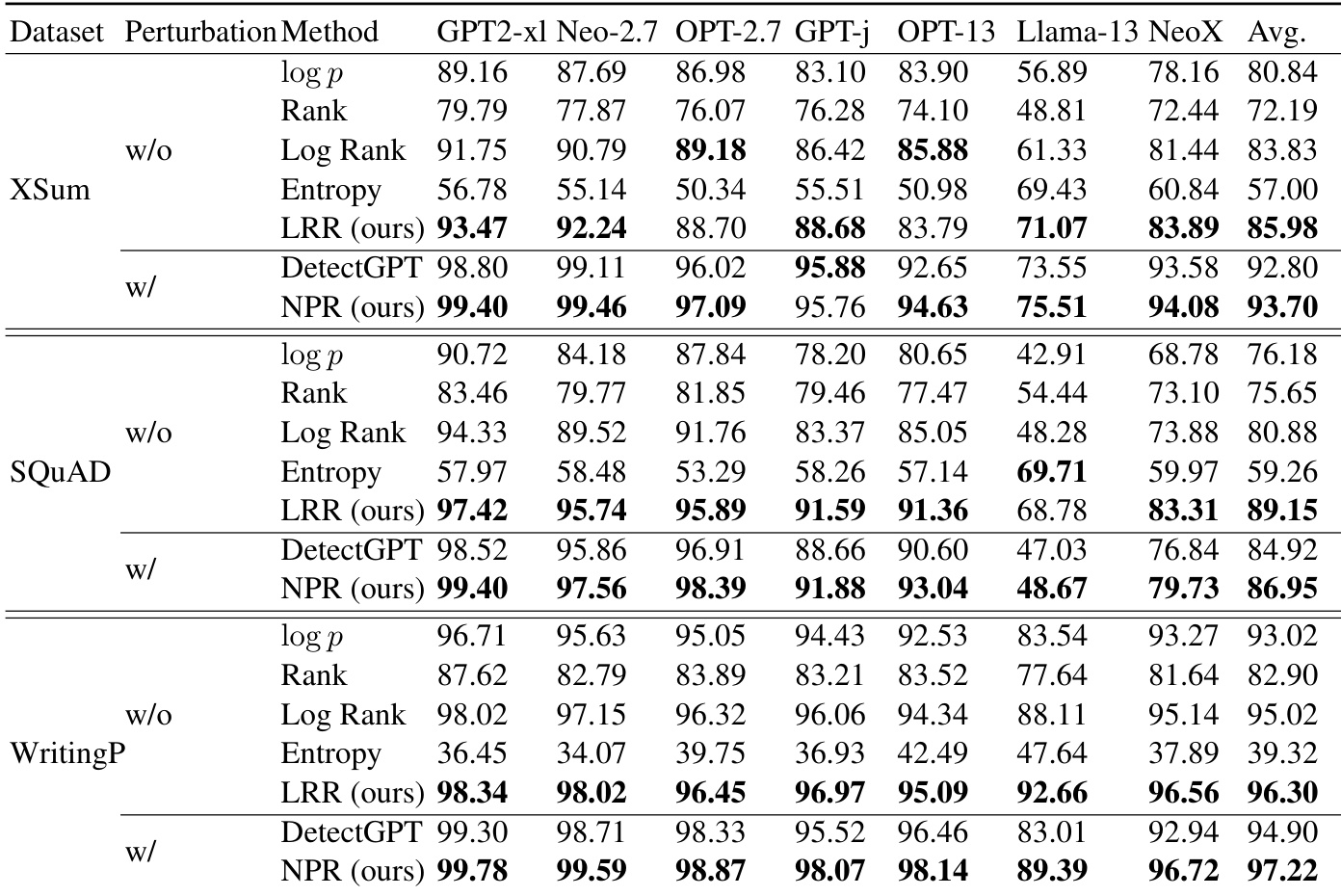
The authors compare their proposed methods, LRR and NPR, with existing zero-shot detection approaches across multiple datasets and language models. Results show that NPR consistently outperforms DetectGPT in perturbation-based methods, while LRR achieves strong performance among perturbation-free methods, often rivaling or surpassing perturbation-based approaches. The study also highlights the trade-off between performance and computational efficiency, particularly in relation to the number of perturbations and the size of the perturbation function. NPR consistently outperforms DetectGPT across all datasets and models in perturbation-based methods. LRR achieves high performance among perturbation-free methods, often surpassing perturbation-based methods like DetectGPT. The performance of perturbation-based methods is sensitive to the size of the perturbation function, with larger models yielding better results but at higher computational cost.
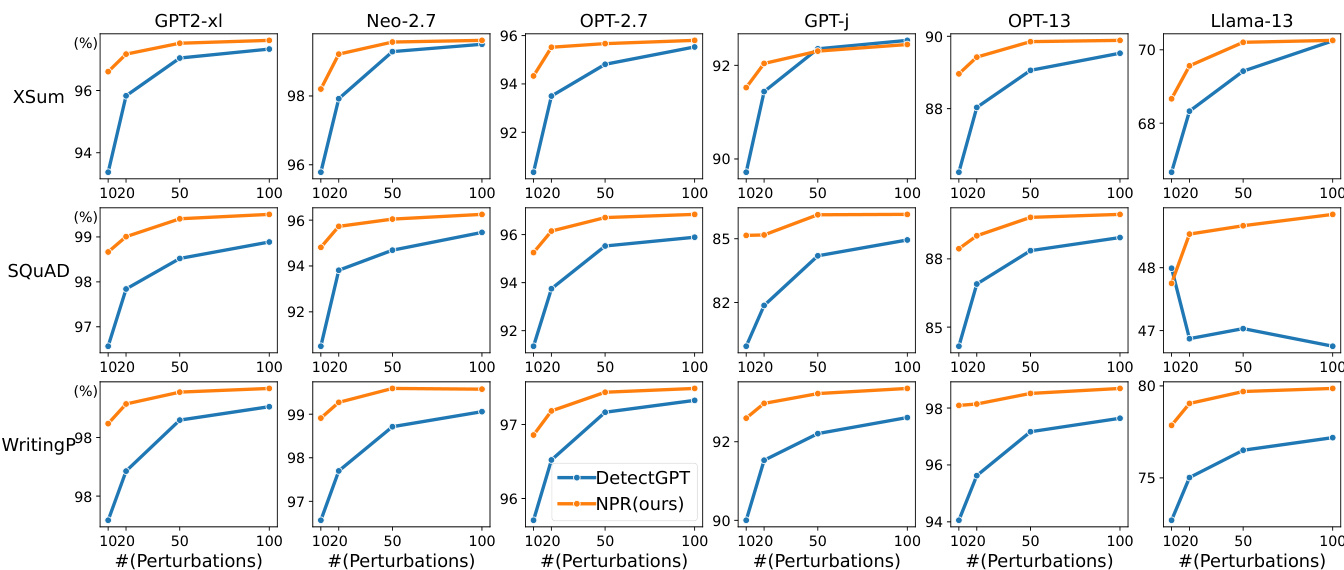
The experiments evaluate zero-shot machine-generated text detection methods across multiple datasets and language models, comparing perturbation-based and perturbation-free approaches under varying decoding strategies, temperatures, and perturbation function sizes to validate their relative performance, computational efficiency, and robustness. The results demonstrate that perturbation-free methods, particularly LRR, achieve high detection accuracy while requiring significantly fewer computational resources than perturbation-based alternatives. Furthermore, the proposed NPR method consistently outperforms existing perturbation-based baselines, and both approaches exhibit varying sensitivity to generation parameters, with perturbation-free techniques offering superior stability. Ultimately, the findings establish a clear trade-off between detection accuracy and computational cost, positioning perturbation-free methods as a highly efficient and reliable alternative.