Command Palette
Search for a command to run...
One-click Deployment of Multilingual TTS Model Orpheus TTS
Abstract
One-sentence Summary
The proposed method conditions a zero-shot text-to-speech model directly on a self-supervised speech representation model and separately conditions acoustic features and a phoneme duration predictor to disentangle rhythm and timbre characteristics, yielding improved speaker similarity and speech-rhythm transfer for unseen speakers as confirmed by objective and subjective evaluations.
Key Contributions
- This work introduces a zero-shot text-to-speech framework that extracts speaker embedding vectors directly from a self-supervised speech representation model trained on large-scale audio data.
- The architecture employs separate conditioning pathways for acoustic features and a phoneme duration predictor to generate disentangled embeddings that isolate rhythm-based characteristics from acoustic properties.
- Objective and subjective evaluations demonstrate that the method improves speaker similarity for unseen speakers and enables effective speech-rhythm transfer across different reference utterances.
Introduction
Zero-shot text-to-speech synthesis enables systems to generate natural speech for unseen speakers or languages without requiring target-specific training data, making it highly valuable for scalable voice cloning and multilingual deployment. Prior approaches typically struggle with inconsistent prosody transfer, demand extensive adaptation recordings, or lose speaker identity when relying exclusively on linguistic encoders. The authors address these bottlenecks by leveraging self-supervised speech representations as conditioning signals, effectively extracting speaker and prosodic characteristics directly from unlabeled audio. Their framework demonstrates that these pretrained models can reliably guide synthesis networks to produce high-fidelity voice output without any zero-shot fine-tuning.
Dataset
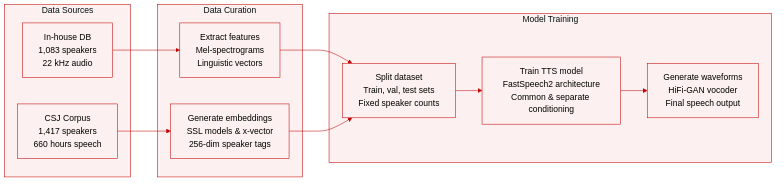
- Dataset Composition and Sources: The authors combine an in-house proprietary Japanese speech database with the publicly available Corpus of Spontaneous Japanese (CSJ).
- Subset Details and Splits: The in-house collection features 1,083 speakers, blending professional talent such as newscasters and voice actors with non-professional participants. It is partitioned into training (135,202 utterances across 978 speakers), validation (7,243 utterances across 52 speakers), and test sets (6,421 utterances across 53 speakers). The CSJ dataset contributes 660 hours of spontaneous speech recorded by 1,417 speakers.
- Data Processing and Usage: The in-house recordings are sampled at 22.05 kHz and manually annotated with accentual information. The authors extract 80-dimensional mel-spectrograms with a 5.0 ms frame shift and align them against 303-dimensional linguistic vectors to train a FastSpeech2 model. The CSJ corpus is used to pretrain w2v2 and HuBERT self-supervised models, as well as a conventional x-vector baseline. These models convert 16 kHz audio into 256-dimensional speaker embeddings that are frozen and fed into the TTS pipeline.
- Conditioning and Synthesis Details: The authors evaluate common versus separate conditioning strategies, routing speaker embeddings through either average pooling or an attention-based LSTM. Final waveforms are reconstructed using a HiFi-GAN vocoder across all experimental configurations.
Method
The authors leverage a non-autoregressive text-to-speech (TTS) model, specifically based on FastSpeech2, as the core synthesis framework. This model operates by first encoding the input text into a sequence of acoustic features, which are then processed by a duration predictor to determine the timing of phonemes, and by separate predictors for pitch and energy. The output of these predictors, along with the encoded text, is fed into a decoder to generate the final speech waveform. The key innovation lies in how speaker conditioning is applied through a self-supervised learning (SSL) model, such as HuBERT or wav2vec 2.0, which is used to extract rich speaker-specific embeddings.
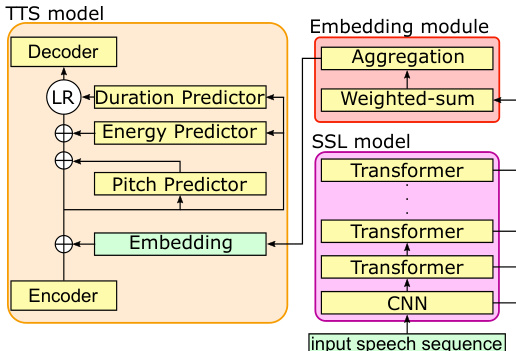
As shown in the figure below, the input speech sequence is processed by the SSL model, which produces a frame-level sequence of speech representation vectors. Each vector in this sequence is derived from the outputs of the SSL model's various layers, resulting in a high-dimensional representation. This sequence is then passed to an embedding module designed to condense it into a fixed-length vector that captures the speaker's characteristics.
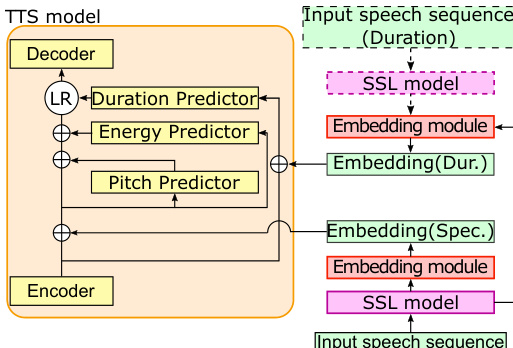
The embedding module is composed of two stages. The first stage, a weighted-sum operation, combines the outputs from different layers of the SSL model for each time frame, producing a weighted-sum speech representation vector. The second stage, aggregation, reduces this frame-level sequence to a single fixed-length embedding vector. Two aggregation methods are considered: average pooling, which computes the mean of the sequence, and soft-attention over LSTM outputs, which uses an attention mechanism to selectively focus on more salient frames, thereby better capturing temporal dynamics like speech rhythm. This attention-based approach is expected to yield more discriminative embeddings for speaker characteristics.
Furthermore, the authors introduce a separate conditioning mechanism to disentangle the speaker's rhythm from their acoustic features. This is achieved by obtaining distinct embedding vectors for the duration predictor and the other acoustic predictors (pitch and energy). By conditioning each predictor with its own dedicated embedding, the model can independently model the rhythmic properties (governed by the duration predictor's embedding) and the acoustic properties (governed by the other predictors' embeddings). This separation enables the system to perform speech-rhythm transfer, where the acoustic characteristics of one speaker can be combined with the rhythm of another.
Experiment
The evaluation compares a zero-shot text-to-speech method using self-supervised learning models with separate conditioning against conventional speaker embedding techniques across parallel and non-parallel synthesis conditions. Objective and subjective experiments validate that this approach successfully disentangles rhythm-based and acoustic features, yielding superior speaker similarity and robust performance for out-of-domain speakers. Additional assessments confirm the model's ability to explicitly transfer speech rhythm, its limited dependency on training language, and improved generalization when scaled with larger architectures. Overall, the results demonstrate that isolating prosodic and acoustic representations significantly enhances synthesis fidelity and enables precise vocal control.
The authors conducted subjective evaluations to compare the proposed method with conventional approaches in zero-shot TTS, focusing on naturalness and similarity under non-parallel conditions. Results indicate that the proposed method achieves higher preference scores and better alignment with reference speech rhythm compared to the baseline, particularly in capturing speaker-specific rhythmic characteristics. The proposed method achieves higher preference scores than the baseline in speech-rhythm transfer evaluations. The proposed method demonstrates better alignment with reference speech rhythm compared to the baseline. The proposed method shows improved performance in capturing speaker-specific rhythmic characteristics compared to the baseline.

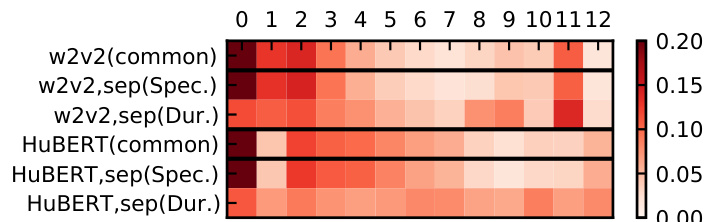
The authors analyze the contribution of different layers in SSL models for speaker conditioning in zero-shot TTS, focusing on how separate conditioning for acoustic features and phoneme duration leads to disentangled embeddings. The results show that the proposed method effectively separates rhythm-based and acoustic-feature-based speaker characteristics by leveraging different layers of the SSL model, with deeper layers contributing more to duration conditioning and shallower layers to acoustic features. Separate conditioning enables disentanglement of rhythm-based and acoustic-feature-based speaker characteristics. The proposed method uses different layers of SSL models for different conditioning tasks, with deeper layers influencing duration prediction more. Weight visualization indicates that common conditioning relies on shallower layers, similar to x-vector, while separate conditioning extracts distinct information for each task.
The authors conducted subjective evaluations to compare the naturalness and similarity of a proposed method using HuBERT embeddings with an x-vector baseline. Results show that the proposed method achieves comparable naturalness to x-vector while significantly improving similarity, particularly in capturing rhythm-based speaker characteristics. The LSTM-based aggregation of HuBERT embeddings outperforms the average aggregation in similarity, indicating better disentanglement of speaker features. The proposed method achieves higher similarity than x-vector while maintaining comparable naturalness. HuBERT (LSTM) outperforms HuBERT (average) in similarity, indicating better disentanglement of speaker characteristics. The proposed method shows improved similarity for out-of-domain speakers, particularly voice actors and children.

The authors compare the proposed zero-shot TTS method using SSL models with conventional x-vector methods under parallel and non-parallel conditions. Results show that the proposed method, particularly with separate conditioning and LSTM aggregation, achieves better performance in both melspectrogram and phoneme duration metrics under parallel conditions, while showing comparable or improved results in non-parallel settings. The proposed method demonstrates superior rhythm transfer capabilities and better handling of out-of-domain speakers. The proposed method with separate conditioning and LSTM aggregation outperforms x-vector in melspectrogram and phoneme duration under parallel conditions. Under non-parallel conditions, the proposed method shows comparable or improved performance in melspectrogram while maintaining similar phoneme duration accuracy. The proposed method enables effective speech-rhythm transfer and achieves higher similarity scores, especially for out-of-domain speakers, compared to x-vector.
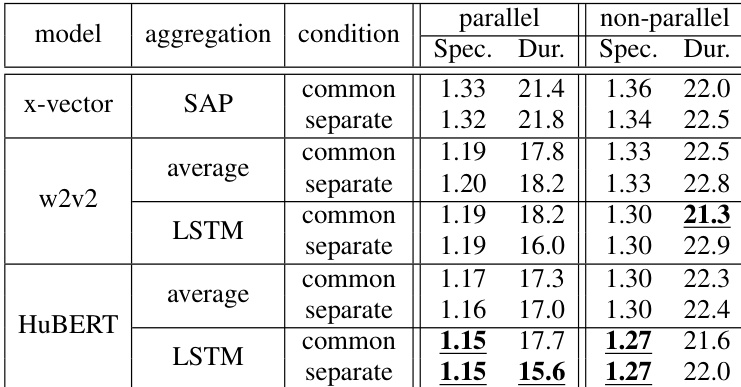
The authors evaluate a proposed zero-shot TTS method using SSL models under parallel and non-parallel conditions, comparing it to a conventional x-vector approach. The results show that the proposed method achieves better performance in certain aspects, particularly in capturing rhythm-based speaker characteristics and enabling speech-rhythm transfer, while the effectiveness varies depending on the data conditions and model configurations. The proposed method outperforms the conventional approach in capturing rhythm-based speaker characteristics under both parallel and non-parallel conditions. The proposed method enables effective speech-rhythm transfer, as indicated by higher preference scores and closer speaking rates to the reference speech. Model performance varies with training data and size, with larger models trained on more extensive datasets showing improved results in reproducing speech features.
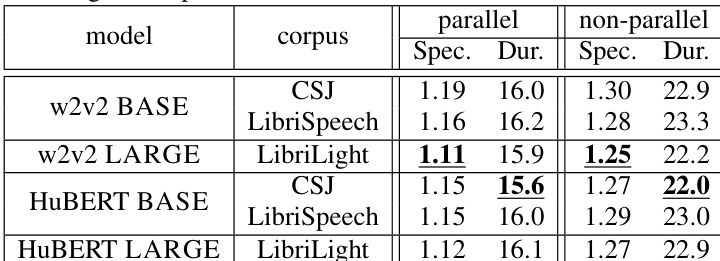
Subjective and objective evaluations compare the proposed zero-shot TTS framework, which leverages SSL embeddings with separate acoustic and duration conditioning, against a conventional x-vector baseline under both parallel and non-parallel training conditions. Experimental analysis validates that this architecture effectively disentangles rhythmic and acoustic speaker characteristics by assigning distinct roles to different model layers, with deeper layers primarily governing phoneme duration and shallower layers capturing acoustic features. Qualitative assessments consistently demonstrate that the proposed approach achieves superior speech-rhythm transfer, higher listener preference, and improved similarity for out-of-domain speakers while maintaining comparable naturalness. Overall, the findings confirm that decoupled conditioning and optimized feature aggregation significantly enhance rhythmic fidelity and cross-condition generalization compared to traditional speaker modeling techniques.