Command Palette
Search for a command to run...
Learn All Object Detection Techniques in One Article
Abstract
One-sentence Summary
This comprehensive survey examines deep learning advancements in oriented object detection for optical remote sensing by tracing the evolution from horizontal detection, categorizing methods into detection frameworks, oriented bounding box regression techniques, and feature representation approaches to address feature and spatial misalignment challenges, and providing a structured comparison of state-of-the-art algorithms, public datasets, and evaluation protocols alongside identified future research directions.
Key Contributions
- The paper establishes a systematic taxonomy that categorizes oriented object detection methods into detection frameworks, oriented bounding box regression techniques, feature representation approaches, and specialized solutions for remote sensing challenges. This classification details how current architectures mitigate feature misalignment, spatial misalignment, and angular boundary discontinuity inherent to OpenCV and long edge definitions.
- The survey compiles a comprehensive inventory of publicly available remote sensing datasets alongside standardized evaluation protocols to establish consistent benchmarking standards. This consolidated reference facilitates reproducible experimental setups and enables direct performance comparisons across diverse task configurations.
- The work presents an extensive comparative analysis of state-of-the-art detection models to identify remaining technical bottlenecks and outline prioritized directions for future research. These findings synthesize empirical evaluation trends across multiple benchmarks to guide subsequent methodological development.
Introduction
The authors present a comprehensive survey of oriented object detection in optical remote sensing imagery, a critical capability for applications ranging from precision agriculture to urban planning and military reconnaissance. Because these images are captured from a bird's eye view, objects appear at arbitrary angles, rendering traditional horizontal bounding boxes inefficient due to excessive background inclusion and high overlap in dense scenes. Directly adapting standard detectors to this domain introduces significant hurdles, including feature misalignment from axis-aligned convolutions, spatial misalignment caused by poor anchor overlap, and regression instability stemming from angular periodicity and vertex ordering issues. To bridge these gaps, the authors systematically categorize existing methodologies into detection frameworks, oriented bounding box regression techniques, and advanced feature representation strategies while providing a rigorous benchmark of state-of-the-art models. They also identify persistent research bottlenecks and outline promising future directions, including lightweight architectures, multimodal datasets, and large-scale foundation models.
Dataset
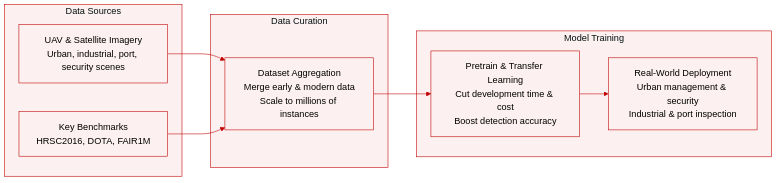
-
Dataset Composition and Sources: The authors organize oriented object detection data into early and modern benchmarks, primarily sourced from UAV and satellite imagery across urban traffic management, industrial inspection, port operations, and security surveillance. Key collections include HRSC2016, FGSD, ShipRSImageNet, DOTA-V1.0, DOTA-V2.0, and FAIR1M.
-
Subset Details: Early datasets like HRSC2016 contain limited instances and narrow scenarios, while modern benchmarks scale to millions of instances and fine-grained categories. Images feature complex backgrounds and can reach resolutions up to 20,000 by 20,000 pixels. DOTA-V1.0 serves as the standard evaluation benchmark, DOTA-V2.0 emphasizes large-scale high-challenge scenarios, and FAIR1M targets fine-grained oriented detection.
-
Data Usage and Processing: The authors leverage these large-scale datasets for pretraining and transfer learning. This strategy significantly reduces model development time and computational costs while improving recognition accuracy across different oriented object detection methods.
-
Preprocessing and Metadata: The provided text does not specify cropping strategies, metadata construction, explicit filtering rules, or training split ratios. The discussion focuses on dataset scale, scenario diversity, and their alignment with real-world deployment rather than detailed preprocessing pipelines.
Method
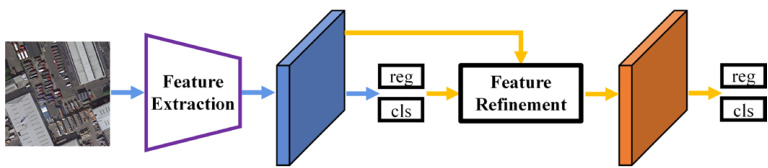
The authors leverage a two-stage detection framework as a foundational approach for oriented object detection, building upon the well-established Faster R-CNN architecture. This framework is designed to address the challenges of detecting objects with arbitrary orientations in aerial imagery. The overall process begins with a feature extraction module that processes the input image to generate a multi-level feature map. This feature map is then fed into a Region Proposal Network (RPN), which operates at each spatial location to predict a set of region proposals. The RPN outputs both classification (cls) and regression (reg) predictions for these proposals, generating a sparse set of high-quality regions that potentially contain objects.
As shown in the figure below, the proposed framework extends the standard two-stage architecture by incorporating a Region of Interest (RoI) alignment step. Following the RPN, the region features for each proposal are extracted and passed to an RoI Align module. This module ensures that the features are spatially aligned with the proposed regions, which is critical for accurate classification and regression. The aligned features are then fed into an RCNN module, which performs the final classification and refined regression for each proposal. This stage outputs the final detection results, which undergo post-processing operations such as Non-Maximum Suppression (NMS) to finalize the predictions.
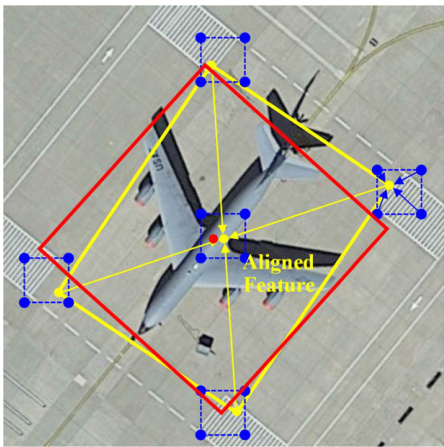
To handle the specific challenges of oriented objects, the framework is adapted to generate rotated region proposals. The standard RPN, which only generates horizontal proposals, is modified to produce rotated proposals that better match the orientation of the objects. This adaptation involves either using rotated anchors to generate proposals or introducing a lightweight module that transforms horizontal anchors into high-quality rotated proposals. This design aims to alleviate the feature misalignment that occurs when using horizontal region proposals to detect objects with arbitrary orientations, as illustrated in the provided diagram. The feature misalignment between the horizontal region proposal and the oriented object significantly harms feature representations, making it difficult for the detector to identify objects and regress precise oriented bounding boxes.
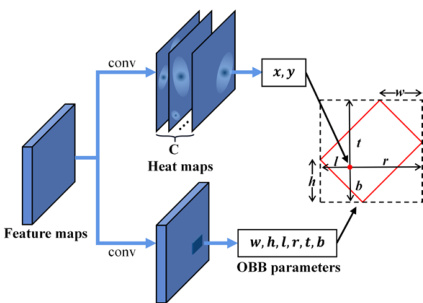
The framework's design is further enhanced by integrating a feature refinement stage. This stage takes the initial feature map and applies a refinement process to improve the quality of the features before they are used for detection. This refinement helps to mitigate the feature misalignment and spatial misalignment issues, particularly in scenarios where objects have large aspect ratios or complex orientations. By refining the features, the model can achieve more accurate localization and classification, leading to improved detection performance. The refined features are then used for the final classification and regression tasks, resulting in a more robust and accurate oriented object detection system.
Experiment
The evaluation compares state-of-the-art oriented object detectors on the DOTA-V1.0 dataset to analyze how different architectural choices and training strategies address core challenges like arbitrary orientations, scale variations, and extreme aspect ratios. Two-stage frameworks consistently yield the highest accuracy, while one-stage methods achieve comparable performance through refined alignment stages, whereas DETR-based approaches struggle with rotated object coverage. The analysis further demonstrates that advanced loss functions and specialized bounding box representations significantly enhance regression stability, and transformer-based backbones provide superior feature extraction despite higher computational demands. Ultimately, integrating attention mechanisms, reweighted assignment strategies, and multiscale training proves essential for mitigating background noise and scale-related issues, though these improvements often come with increased training and inference overhead.
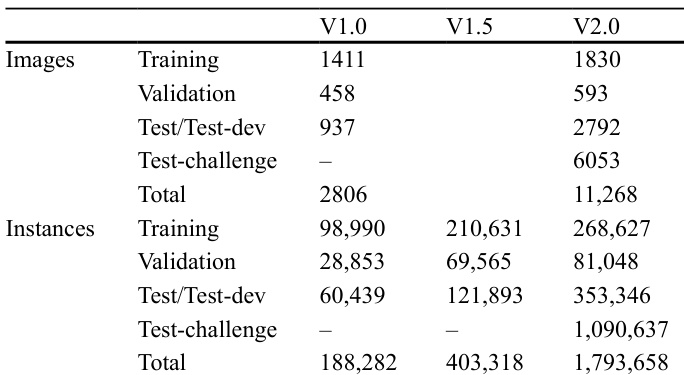
The authors present a comparison of state-of-the-art oriented object detection methods on the DOTA-V1.0 dataset, focusing on performance metrics and key methodological components. The dataset is structured across different versions with varying numbers of images and instances, reflecting updates in scale and complexity. The dataset versions show a significant increase in the number of training and total instances, indicating a larger and more complex benchmark for evaluation. The number of validation images and instances grows substantially from V1.0 to V2.0, suggesting enhanced validation capacity. The test-challenge set is introduced in later versions, providing a dedicated evaluation set for benchmarking new methods.
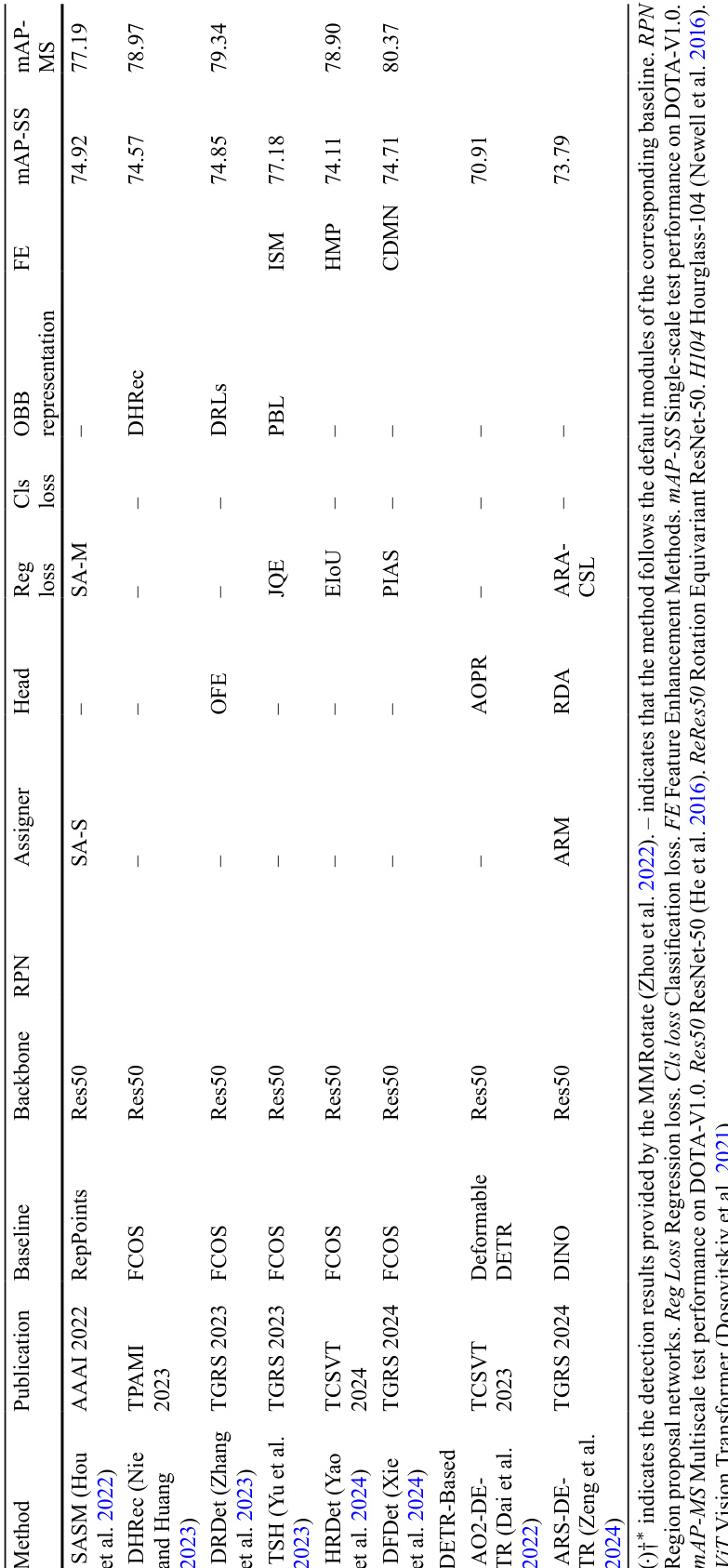
The authors compare state-of-the-art oriented object detection methods on the DOTA-V1.0 dataset, focusing on different detection frameworks, OBB representation techniques, feature representation approaches, and solutions to common issues. Results show that two-stage detectors achieve the highest performance, and transformer-based backbones outperform CNN-based ones despite higher computational costs. The use of multiscale training and testing improves accuracy but significantly increases training and inference time. Two-stage detectors achieve the highest performance compared to one-stage and DETR-based methods. Transformer-based backbones outperform CNN-based backbones in terms of accuracy, though they require longer training times. Multiscale training and testing improve detection accuracy but result in substantially longer training and inference times.
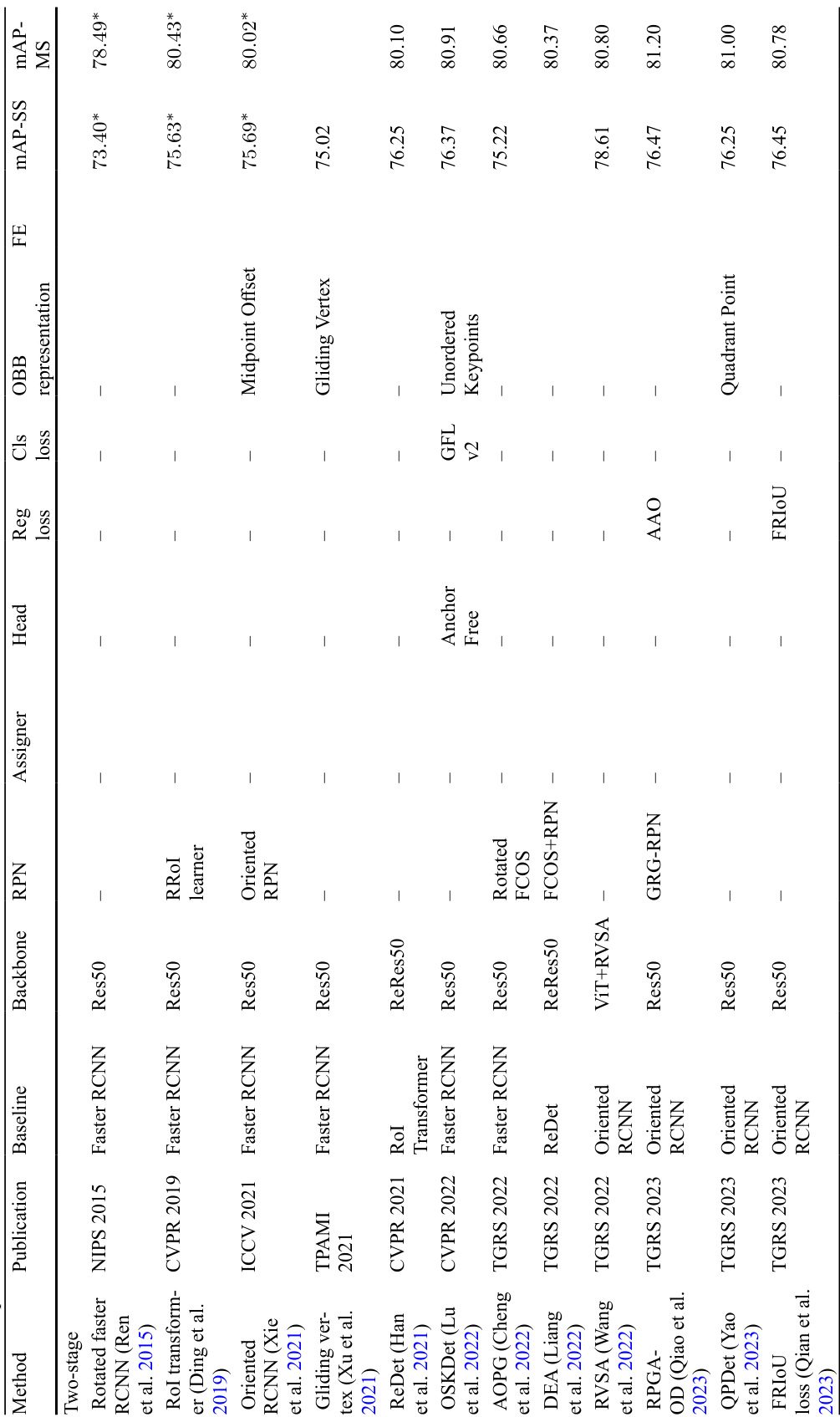
The authors compare state-of-the-art oriented object detection methods on the DOTA-V1.0 dataset, analyzing their performance based on detection frameworks, OBB representation techniques, feature representation approaches, and solutions to common challenges. Results show that two-stage detectors generally achieve higher accuracy, with transformer-based models outperforming CNN-based ones despite longer training times, and that multiscale training provides a significant performance boost at the cost of increased computational demands. Two-stage detectors achieve higher performance compared to one-stage and anchor-free methods. Transformer-based backbones outperform CNN-based models in terms of accuracy, though they require longer training times. Multiscale training improves detection accuracy, but significantly increases training and inference duration.
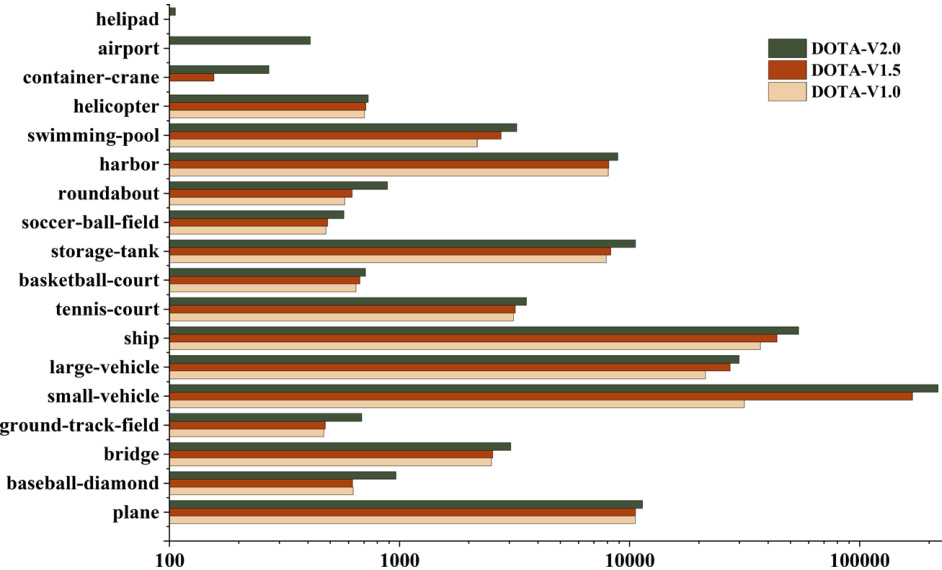
The authors compare the performance of state-of-the-art oriented object detection methods on the DOTA-V1.0 dataset, using a bar chart to show results across different object categories. The chart indicates that detector performance varies significantly by category, with some methods showing substantial improvements on certain classes while others perform less consistently. The results highlight differences in detection accuracy between datasets, particularly between DOTA-V1.0 and DOTA-V2.0, with some categories showing marked improvements in the newer version. Performance varies significantly across object categories, with some classes showing much higher detection accuracy than others. Detectors achieve better results on certain categories in DOTA-V2.0 compared to DOTA-V1.0, indicating dataset-specific improvements. The performance gap between methods is more pronounced in specific categories, suggesting that detection challenges differ by object type.
The authors compare state-of-the-art oriented object detection methods on the DOTA-V1.0 dataset, analyzing performance across different object categories and data splits. Results show variations in detection accuracy and distribution patterns, with certain categories exhibiting higher detection difficulty, as indicated by the spread and position of the data points in the box plots. Performance varies significantly across different object categories, with some categories showing more challenging detection distributions. Different data splits exhibit distinct performance trends, suggesting variations in detection difficulty based on dataset version and coverage. The box plots reveal differences in detection accuracy and consistency, highlighting the impact of category-specific characteristics on model performance.
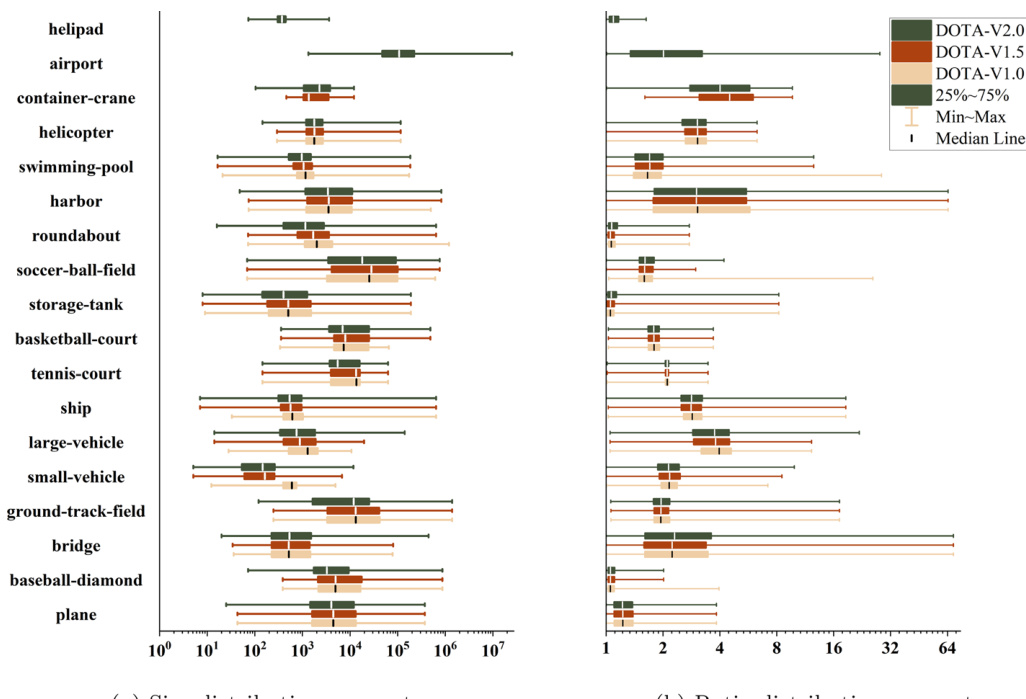
The experiments evaluate state-of-the-art oriented object detection methods on the DOTA-V1.0 dataset to assess how detection frameworks, backbone architectures, and training strategies influence overall performance. Qualitative analysis reveals that two-stage detectors and transformer-based backbones consistently yield higher accuracy than one-stage and CNN-based alternatives, though these advantages are offset by substantially greater computational and time requirements. Multiscale training further enhances detection quality but significantly extends both training and inference durations. Furthermore, category-specific evaluations demonstrate that detection difficulty varies widely across object types, with performance gains between dataset versions underscoring the evolving complexity and class-dependent challenges of oriented detection benchmarks.