Command Palette
Search for a command to run...
Attention Mechanisms and Transformers
Abstract
One-sentence Summary
The authors propose the Personalized Attention Mechanism (PersAM), a Transformer-based method that adaptively adjusts attention regions in medical images according to patient clinical records by encoding cross-modal relationships, and they evaluate its effectiveness on identifying subtypes across 842 malignant lymphoma patients using gigapixel whole slide images.
Key Contributions
- The Personalized Attention Mechanism (PersAM) utilizes a Transformer architecture to encode cross-modal relationships between gigapixel whole slide images and tabular clinical records, enabling dynamic adjustment of attention regions based on patient-specific factors.
- The framework computes bidirectional attention between image patches and clinical data to generate personalized diagnostic focus regions that adapt to individual patient records, effectively mimicking the prior-knowledge-driven examination process of expert pathologists.
- Application to a cohort of 842 malignant lymphoma patients demonstrates the effectiveness of the approach for identifying subtypes using whole slide images and clinical records, while generating attention maps that reflect patient-specific diagnostic priorities.
Introduction
Digital pathology relies on analyzing massive whole slide images using multiple instance learning to detect tumors without pixel-level annotations. While attention-based models and multimodal frameworks that combine histology with clinical records have improved diagnostic accuracy, existing approaches primarily treat patient data as auxiliary inputs to optimize performance metrics. These prior methods rarely investigate how specific clinical factors actively reshape the model's focus on image regions, leaving a gap in clinically grounded interpretability. The authors leverage a Transformer architecture to fuse histological patches with tabular patient records, enabling dynamic cross-attention that personalizes image focus based on individual clinical histories. This approach generates interpretable attention maps that closely mirror how expert pathologists integrate medical records during diagnosis, advancing both diagnostic reasoning and clinical transparency.
Dataset

-
Dataset Composition and Sources
- The authors use a clinical database of 842 malignant lymphoma cases confirmed by expert hematopathologists.
- Each case pairs a gigapixel whole-slide image of an H&E-stained tissue specimen with a structured clinical record.
- All WSIs were digitized at 40x magnification (0.26 μm/pixel) using an Aperio GT 450 scanner, with maximum dimensions around 100,000 by 100,000 pixels.
-
Key Details for Each Subset
- The cohort includes 277 DLBCL cases featuring large tumor cells across broad tissue regions, 270 FL cases showing follicular structures with tumor cells, and 295 reactive lymphoid hyperplasia cases displaying diverse non-tumor cell morphology.
- Annotations are strictly case-level rather than patch-level, meaning the subtype label applies to the entire WSI and propagates to all derived patches.
-
Cropping Strategy and Metadata Construction
- The authors randomly extract 224 by 224 pixel patches from each WSI, grouping 100 patches into a single bag to balance computational load and memory usage.
- A maximum of 30 bags are sampled per WSI, with each bag inheriting the original case label.
- Clinical metadata containing 28 variables is compressed into two 512-dimensional vectors representing patient demographics and interview data (18 features) and blood test results (10 features).
- Image patches are encoded into 512-dimensional feature vectors using a pretrained ResNet50 backbone followed by a two-layer neural network with 1024 hidden units.
-
Data Usage and Training Configuration
- The dataset is partitioned into training, validation, and testing sets at a 3:1:1 ratio and evaluated through five-fold cross-validation.
- Input data is formatted for the Transformer by combining patch features, clinical vectors, and three 512-dimensional class tokens into a 512 by 105 matrix.
- Training applies random horizontal flips and 90-degree rotational augmentations, label smoothing (0.95 for correct classes, 0.05 for incorrect ones), and momentum SGD with component-specific learning rates over nine epochs.
Method
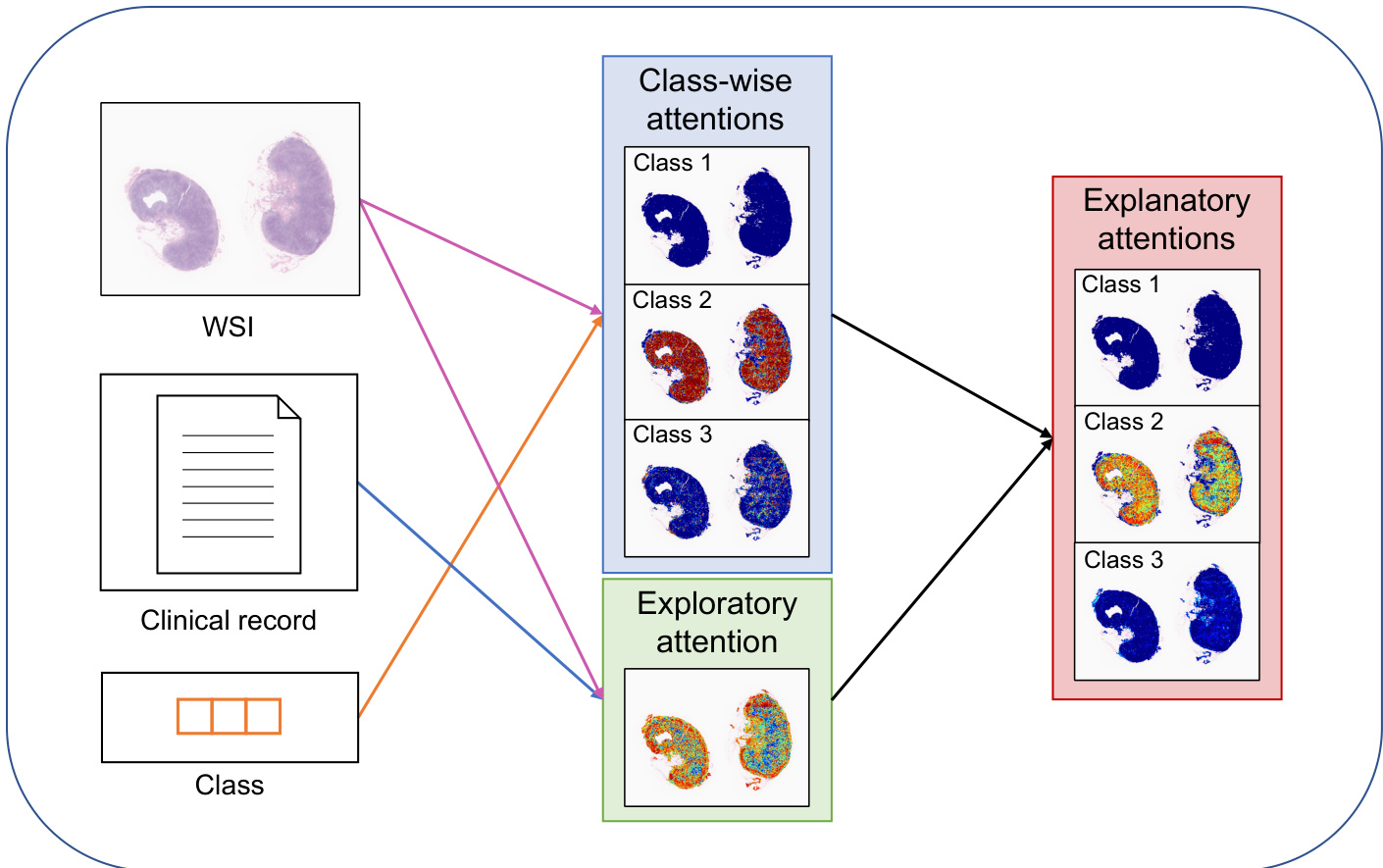
The proposed PersAM framework is designed to model the diagnostic process of human pathologists by integrating medical images and clinical records to produce personalized attention regions and subtype classifications. The overall architecture consists of three main components: a feature extractor, a multimodal encoder, and a multimodal aggregator. These components work together to encode and process multimodal information, enabling the model to generate both exploratory and explanatory attention maps that adapt to patient-specific clinical data.
As shown in the figure below, the input to the model comprises a whole slide image (WSI) and a clinical record for a given patient. The WSI is decomposed into a set of image patches, each of which is processed independently. 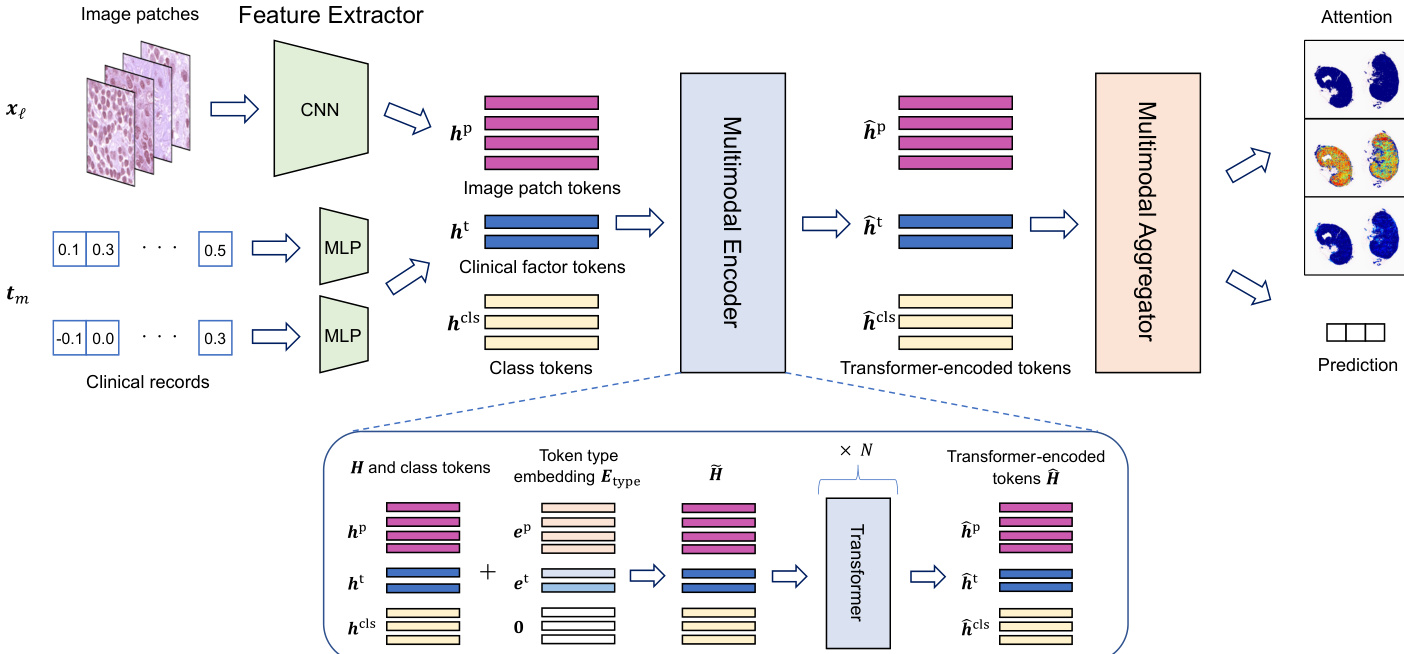
The feature extractor component computes feature vectors for both image patches and clinical factors, preparing them for multimodal integration. For image patches, a convolutional neural network (CNN) maps each patch xℓ to a feature vector hℓp∈RR. For clinical factors, a multi-layer perceptron (MLP) maps each factor tm to a feature vector hmt∈RR, ensuring that both modalities are represented in a common feature space. The resulting set of feature vectors, H={hℓp}ℓ∈[L]∪{hmt}m∈[M], forms the input to the multimodal encoder.
The multimodal encoder, implemented as a Transformer, characterizes the relationships among image patches, clinical factors, and class information. This component takes as input a sequence of tokens, including image patch tokens {hℓp}ℓ∈[L], clinical factor tokens {hmt}m∈[M], and class tokens {hccls}c∈[C]. To distinguish between these token types, a token type embedding Etype is added to each token, where Etype=[Lep,…,ep,e1t,…,eMt,C0,…,0]⊤, with ep and {emt}m∈[M] being trainable parameters. The Transformer processes this augmented input to produce a set of encoded tokens, H^={{h^ccls}c∈[C],{h^ℓp}ℓ∈[L],{h^mt}m∈[M]}.
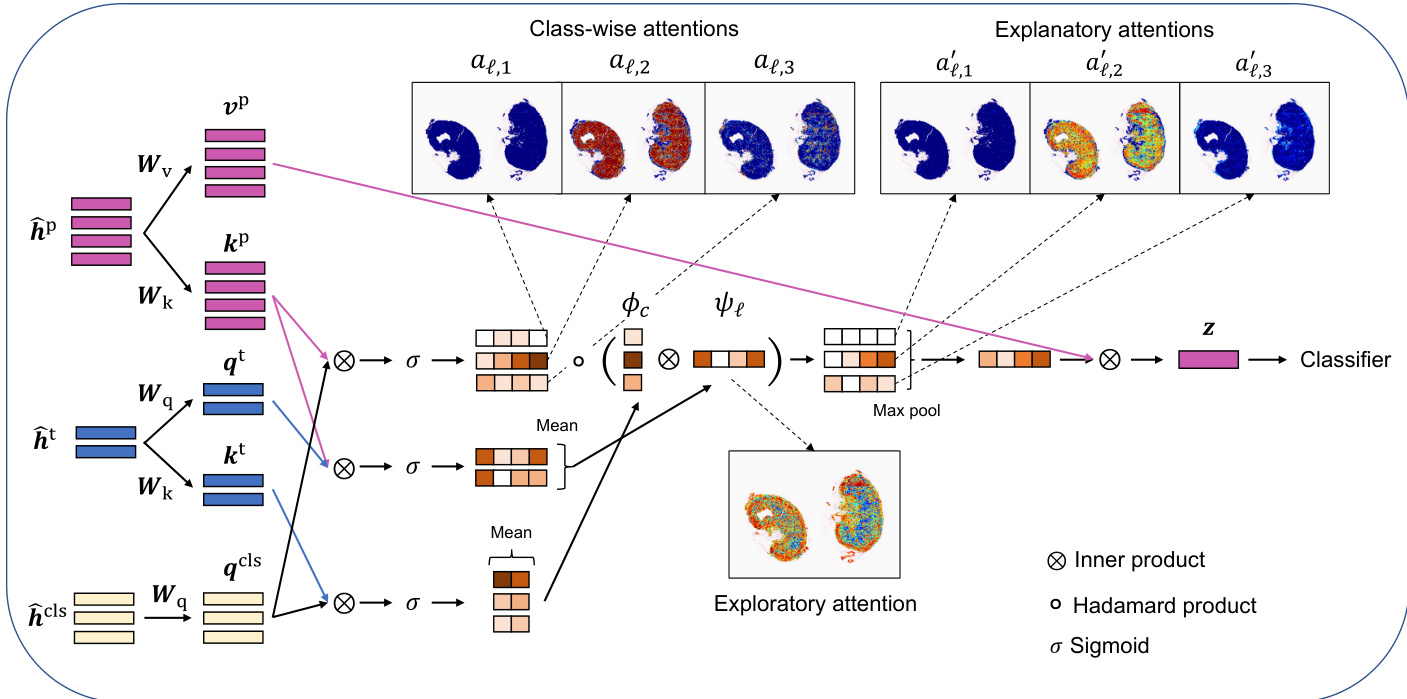
The multimodal aggregator processes the Transformer-encoded tokens to compute exploratory and explanatory attentions and to produce a classification prediction. It begins by computing queries, keys, and values for the class tokens, clinical factor tokens, and image patch tokens using trainable weight matrices Wq,Wk,Wv∈RR×R. The relevance between each image patch and each class token is determined by the inner product of their respective queries and keys, resulting in class-wise attentions aℓ,c=σ(qccls⊤kℓp), where σ(⋅) is the sigmoid function. The relevance between each image patch and the clinical factors is captured by the average relevance, ψℓ=M1∑m∈[M]σ(qmt⊤kℓp), which is defined as the exploratory attention. The relevance between each class and the clinical factors, ϕc=M1∑m∈[M]σ(qccls⊤kmt), is used to modulate the class-wise attentions. The explanatory attention for each patch and class is then computed as aℓ,c′=aℓ,cϕcψℓ.
The classification result is obtained by aggregating the feature vectors of the image patches weighted by the explanatory attention. Specifically, the aggregate feature vector z=∑ℓ∈[L]∑ρ=1Laρ′aℓ′vℓp is computed, where aℓ′=max(aℓ,1′,…,aℓ,C′). This vector is then passed through a neural network classifier gclf to produce the predicted class probabilities Y^. The model is trained end-to-end using a composite loss function that combines cross-entropy loss with a binary cross-entropy loss designed to account for the multiple instance learning (MIL) nature of the problem, where a bag is considered positive if any instance within it is positive.
Experiment
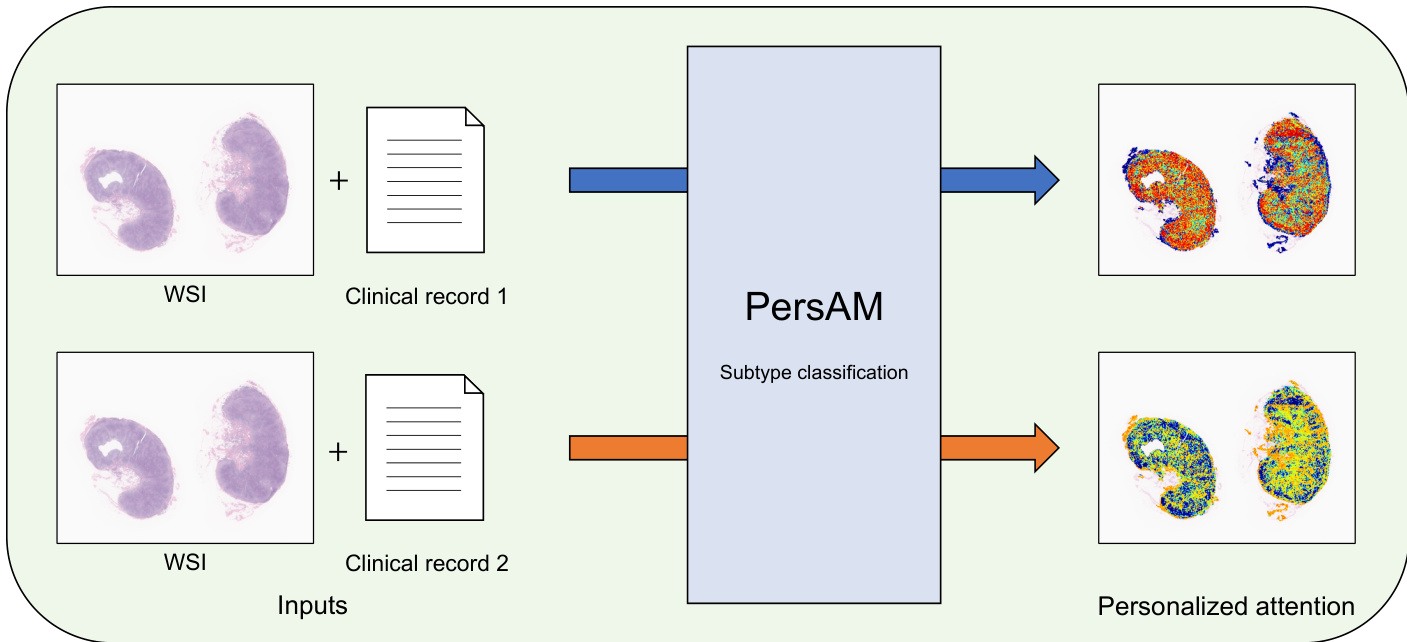
The evaluation setup comprises a three-class subtype classification task using five-fold cross-validation, supplemented by attention visualization experiments that process identical whole slide images with varying real and synthetic clinical records. These experiments validate that the proposed method achieves superior diagnostic accuracy by effectively integrating multimodal features, while its personalized attention mechanisms dynamically adapt to clinical context. Qualitative analysis demonstrates that attention shifts are primarily triggered in diagnostically ambiguous cases, allowing the model to prioritize relevant histological regions when visual features alone are insufficient. Expert hematopathologist review further confirms that these adaptive behaviors align with clinical reasoning, showing that the model reliably distinguishes typical cases from atypical ones by mirroring expert decision-making processes.
{"summary": "The authors compare the proposed method with several baseline approaches in a three-class classification task, showing that the proposed method achieves the highest accuracy. The results indicate that integrating image and clinical features through a multimodal aggregator improves classification performance compared to methods using either modality alone. The proposed method's attention mechanisms adapt based on input clinical records, particularly in cases with ambiguous histological features.", "highlights": ["The proposed method achieves the highest classification accuracy compared to all baseline methods.", "The proposed method outperforms baseline models that use only image or clinical data, indicating the benefit of multimodal feature integration.", "Attention mechanisms adapt to different clinical inputs, especially in cases with ambiguous tissue features, aligning with expert diagnostic reasoning."]
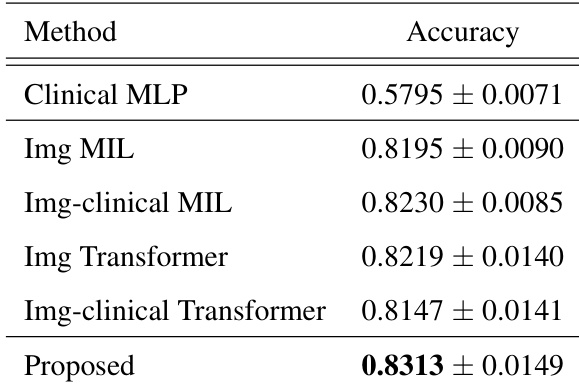
The evaluation compares the proposed framework against multiple baselines in a three-class classification task to assess the effectiveness of multimodal integration and adaptive attention mechanisms. The results indicate that fusing histological images with clinical records consistently yields superior classification performance compared to single-modality approaches. Additionally, the model dynamically adjusts its focus based on clinical context, effectively navigating ambiguous tissue characteristics in a manner that aligns with expert diagnostic reasoning.