Command Palette
Search for a command to run...
Image Captioning
Abstract
One-sentence Summary
The authors introduce FlexHDR, a high dynamic range imaging framework that models alignment and exposure uncertainties via an HDR-aware, uncertainty-driven attention map to jointly align and fuse multiple low dynamic range images, while its progressive, permutation-invariant fusion strategy robustly suppresses ghosting artifacts and achieves up to 1.1 dB PSNR improvement over state-of-the-art methods.
Key Contributions
- The paper introduces a lightweight HDR-specific optical flow network that estimates pixel correspondences across low dynamic range frames by sharing information through symmetric pooling operations and training with an HDR-aware self-supervised loss incorporating exposure uncertainty.
- Explicit exposure and alignment uncertainty models regulate contributions from unreliable pixels within a progressive, multi-stage fusion architecture that supports permutation-invariant processing of arbitrary input counts.
- The uncertainty-driven framework achieves up to a 1.1 dB PSNR improvement over state-of-the-art methods while delivering enhanced detail preservation, color fidelity, and reduced ghosting artifacts.
Introduction
High dynamic range imaging is fundamental to modern digital photography, enabling cameras to capture well-exposed details across scenes with extreme lighting variations by merging multiple low dynamic range exposures. Prior deep learning approaches, however, frequently struggle with motion-induced misalignment and overexposure, often relying on rigid reference frames, fixed input sequences, and alignment modules that are not optimized for exposure-bracketed imagery. The authors leverage a unified framework that jointly models alignment and exposure uncertainties to produce robust HDR reconstructions. They introduce an HDR-specific optical flow network that shares information across all inputs via symmetric pooling, uncertainty-driven attention maps to filter unreliable pixels, and a flexible, permutation-invariant fusion architecture capable of processing any number of LDR images in any order.
Method
The proposed method constructs an end-to-end trainable network for HDR image reconstruction from multiple LDR images, designed to handle arbitrary numbers of inputs and mitigate artifacts arising from motion and exposure uncertainties. The overall architecture, as illustrated in the framework diagram, processes a set of n input images {X1,X2,…,Xn} to predict a single HDR image H^. The network is permutation-invariant and operates in a self-supervised manner, with a modular design that explicitly models and mitigates the two primary sources of error in HDR fusion: motion misalignment and unreliable exposure levels.
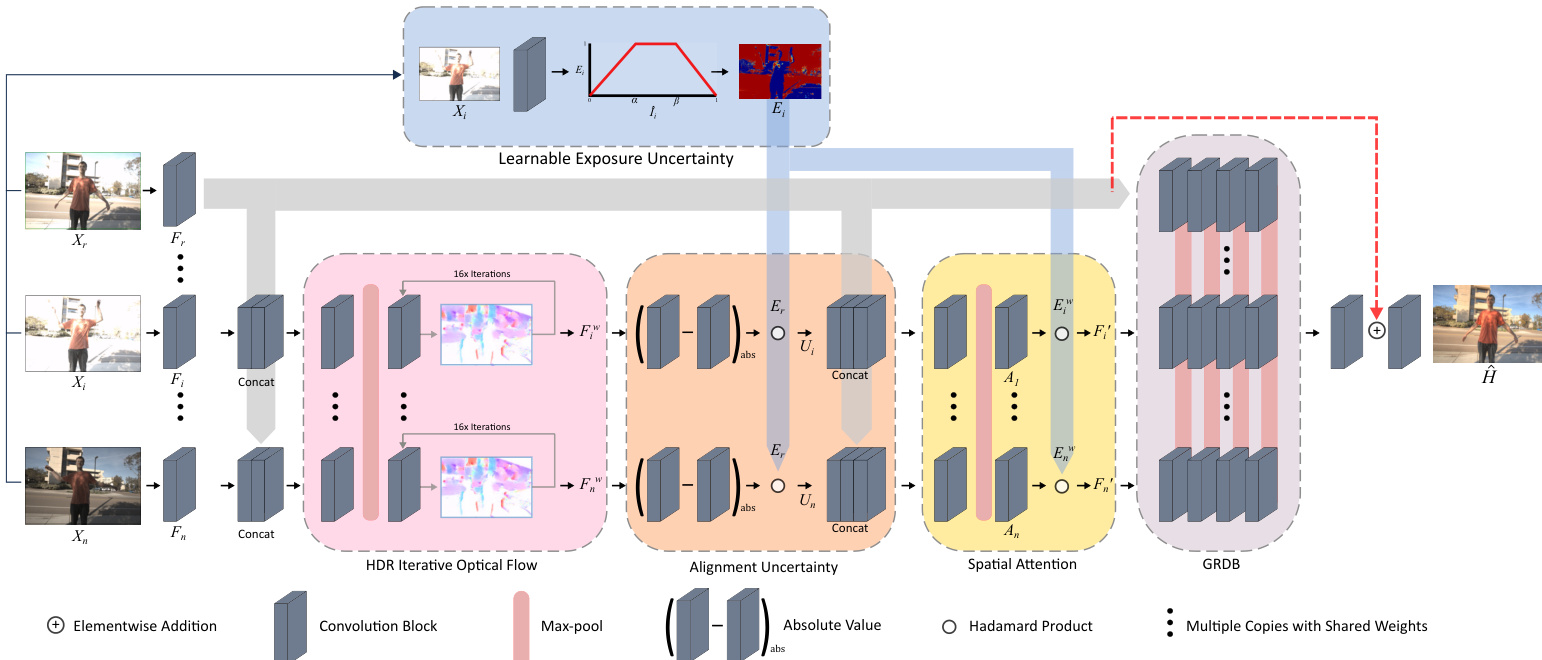
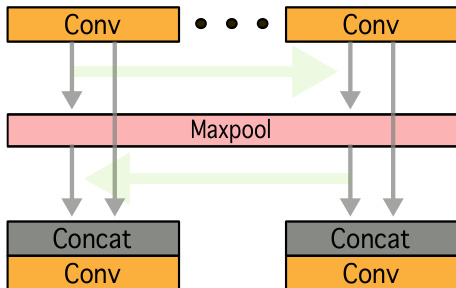
The framework begins by processing each input image independently through a set of identical, shared-weight streams. This allows the network to handle any number of input frames. To facilitate information sharing between these streams, a multi-stage fusion mechanism is employed. At various points in the network, features from each stream are combined using max-pooling operations. Specifically, the features Fik from stream i at layer k are used to compute a max-pooled feature Fimax=conv(⌈Fik,max(F1k,…,Fnk)⌉), where max(⋅) denotes a max-pooling operation and conv(⋅) is a convolutional layer. This process is repeated at multiple stages, and the final outputs of all streams are aggregated through a global max-pooling operation Fglobalmax=max(F1k,…,Fnk), which serves as the input to the merging network.
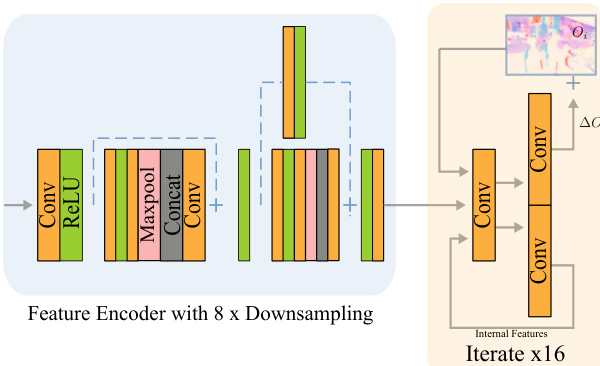
The first major component is the HDR-specific iterative optical flow network, which aligns all non-reference frames to the reference frame Ir. This network, inspired by RAFT but designed for efficiency, uses max-pooling in its feature encoder to share information across all n input frames, enabling it to predict more accurate flows even when individual frames contain large missing regions due to overexposure. The feature encoder downsamples the input features by 8x before the recurrent convolutions iteratively refine the estimated optical flow field Oi. The inputs to the flow network are the features Fi from image Xi, the features Fr from the reference image, and the exposure uncertainty map Ei. The optical flow field Oi is then used to warp the features Fi into Fiw. The network is trained in a fully self-supervised manner using a photometric loss between the reference features Fr and the warped features Fiw, weighted by the exposure mask Er to ensure supervision only occurs in well-exposed regions.
Following alignment, the network models alignment uncertainty. An uncertainty map Ui is computed as the absolute difference between the warped features Fiw and the reference features Fr, multiplied by the exposure mask Er to focus on reliable regions: Ui=abs(Fiw−Fr)∘Er. This map quantifies misalignment. The exposure uncertainty is represented by the warped exposure mask Eiw, which is derived from the predicted exposure map Ei of the input image. The attention network takes as input the warped features Fiw, the reference features Fr, the alignment uncertainty Ui, and the warped exposure mask Eiw. It predicts a 64-channel attention map Ai that regulates the contribution of each frame, with the network using max-pooling to share information between streams during this process.
The final stage is the merging network, which combines the regulated features into a single HDR image. This network is based on a Grouped Residual Dense Block (GRDB) architecture, consisting of three Residual Dense Blocks (RDBs). To enable multi-stage fusion, a max-pooling operation is added after each RDB, following the same formulation as the fusion mechanism described earlier. This allows for progressive merging of features from different streams, preventing information loss that might occur in a single concatenation step. The outputs of the GRDB are then processed through a global residual connection and refinement convolutions to produce the final linear HDR prediction H^.
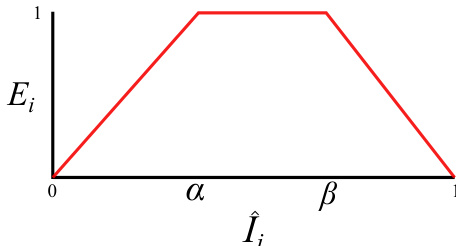
The model explicitly models exposure uncertainty to address unreliable pixel values. For each input image Ii, the network predicts an exposure confidence map Ei using a piecewise linear function of the image's mean pixel value I^i. As shown in the figure, this function has a plateau between α and β where confidence is high, and it linearly decreases to zero as I^i approaches 0 or 1, corresponding to underexposed and overexposed regions. This exposure map is used to suppress the contribution of unreliable pixels in both the attention and merging stages.
The network is trained end-to-end using a composite loss function. This includes a tone-mapped L1 loss Ltm, a perceptual loss Lvgg based on VGG features, and a photometric loss Lphot for the optical flow network. The total loss is Ltot=Ltm+Lphot+10−3Lvgg. The tonemapped image is obtained from the linear HDR image using the μ-law, with μ=5000.
Experiment
The evaluation setup utilizes dynamic HDR datasets and standard fidelity metrics alongside extensive visual assessments to validate the proposed architecture. Ablation studies confirm that the multi-stage fusion mechanism, efficient flow network, and learnable uncertainty modeling each significantly reduce ghosting artifacts and enhance detail preservation. Performance benchmarks demonstrate consistent superiority over existing state-of-the-art methods across diverse lighting and motion conditions, while flexibility tests verify the model's ability to process arbitrary input frame counts and reference choices without retraining. Overall, the approach delivers robust, high-quality HDR reconstructions with efficient runtime, though it remains limited in hallucinating missing details within severely overexposed or underexposed regions.
The authors conduct an ablation study to evaluate the contributions of different components in their HDR fusion model. Results show that each added component, particularly the multi-stage fusion mechanism and exposure uncertainty modeling, leads to consistent improvements in reconstruction quality across multiple metrics. The final model with all components achieves the best performance, demonstrating the effectiveness of the proposed architecture. The multi-stage fusion mechanism improves reconstruction quality compared to baseline concatenation. The flow network and exposure uncertainty modeling contribute significantly to performance gains. The complete model with all components achieves the highest performance across metrics.

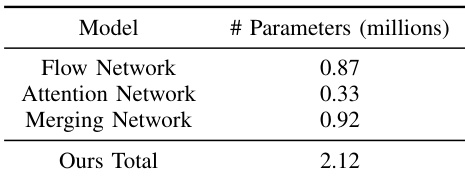
The authors provide a breakdown of their model's parameters by component, showing the flow network, attention network, and merging network contribute 0.87 million, 0.33 million, and 0.92 million parameters respectively, totaling 2.12 million parameters. This indicates the model's architecture is composed of distinct sub-networks with the merging network being the largest component. The model's total parameter count is 2.12 million, with the merging network being the largest single component. The flow network contributes 0.87 million parameters, making it the second-largest component in the model. The attention network is the smallest component, contributing 0.33 million parameters to the total model size.
The authors conduct a comprehensive evaluation of their method against state-of-the-art HDR estimation techniques, demonstrating superior performance across multiple datasets and metrics. They perform ablation studies to validate the contributions of their fusion mechanism, motion alignment, and exposure uncertainty modeling, showing consistent improvements over baseline configurations. The method achieves the best results on both the Kalantari and Chen datasets, outperforming competitors on all seven evaluation metrics and showing strong generalization to out-of-domain data. The proposed method outperforms all competing methods on every metric across both the Kalantari and Chen datasets, showing consistent superiority. Ablation studies confirm that the multi-stage fusion mechanism, motion alignment network, and learnable exposure uncertainty each contribute significantly to the overall performance. The model demonstrates strong generalization and flexibility, achieving high-quality results on out-of-domain data and handling varying numbers of input frames without retraining.
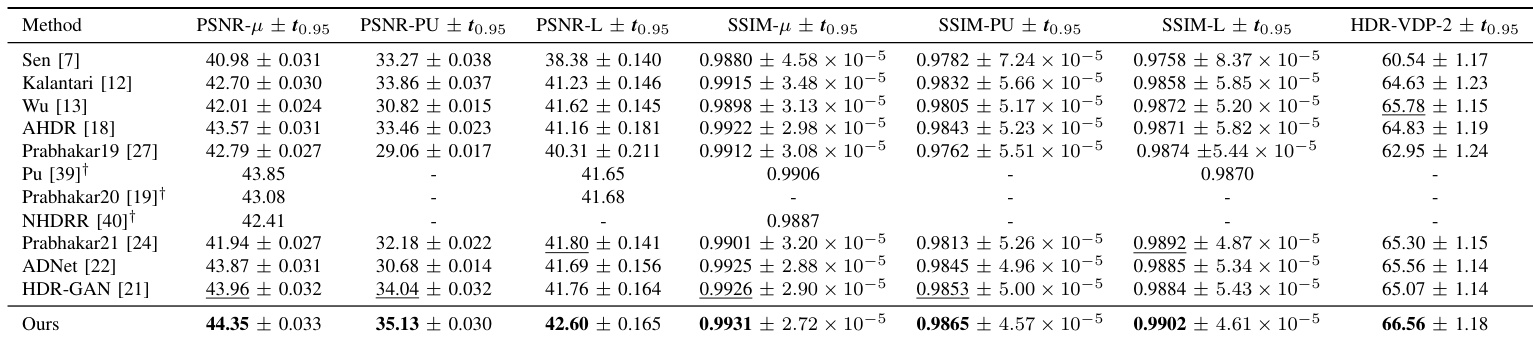
The authors conduct a quantitative evaluation of their proposed method against state-of-the-art approaches on two datasets, demonstrating superior performance across multiple metrics. The results show consistent improvements over existing methods, particularly in handling dynamic scenes and reducing artifacts. The model also exhibits flexibility in accepting varying numbers of input frames and different input configurations without retraining. The proposed method outperforms all compared methods on every metric across both datasets, showing consistent improvements. The model achieves significant gains in quantitative metrics, particularly in PSNR and SSIM, and demonstrates superior performance on HDR-VDP-2. The method is flexible, handling different numbers of input frames and configurations without retraining, and shows strong generalization to out-of-domain data.

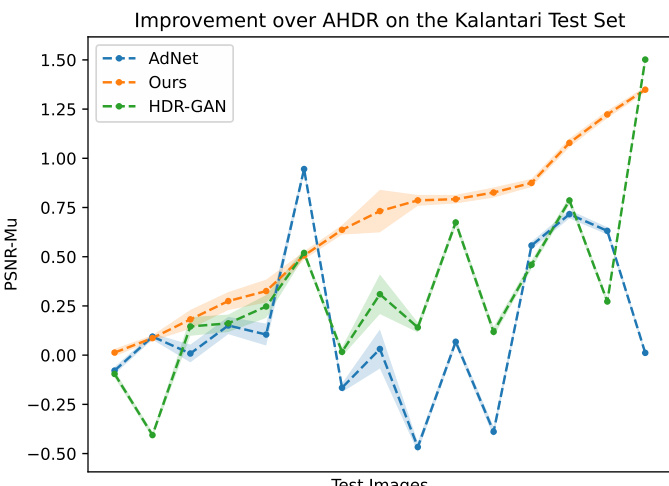
The authors compare their method against state-of-the-art approaches on the Kalantari test set, showing consistent improvements across individual test images. The results indicate that their method outperforms existing techniques on most images, with a significant and stable improvement over the AHDR baseline. The performance of other methods varies more widely, with some showing large improvements and others showing declines relative to the baseline. The proposed method consistently outperforms other approaches on the Kalantari test set, achieving improvements on every test image compared to the AHDR baseline. The improvement over the AHDR baseline is stable and significant, with the proposed method maintaining a clear lead across the majority of test images. Other methods show more variability in performance, with some achieving higher gains on certain images but failing to maintain consistent improvement across the entire test set.
The authors evaluate their HDR fusion architecture through comprehensive benchmarks against state-of-the-art methods on standard datasets, alongside ablation studies that validate the individual contributions of each network component. These experiments confirm that the multi-stage fusion mechanism, motion alignment module, and exposure uncertainty modeling collectively drive substantial improvements in reconstruction quality. The complete framework consistently outperforms existing techniques across diverse scenarios while demonstrating strong out-of-domain generalization and the flexibility to handle varying input configurations without retraining.