Command Palette
Search for a command to run...
An Open Natural Language Processing (NLP) Framework for EHR-based Clinical Research: A Case Demonstration Using the National COVID Cohort Collaborative (N3C)
An Open Natural Language Processing (NLP) Framework for EHR-based Clinical Research: A Case Demonstration Using the National COVID Cohort Collaborative (N3C)
Natural Language Processing with NLTK
Abstract
Despite recent methodology advancements in clinical natural language processing (NLP), adoption of clinical NLP models within the clinical and translational research community remains hindered by issues with ETL process heterogeneity and human factor variations. In this study, we proposed an open NLP development framework with the aim of addressing these issues. The viability of such a platform was evaluated on a COVID-19 use case through sites participating in the National COVID Cohort Collaborative (N3C). As part of our assessment of the impact of single vs. multi-site NLP algorithm development, we evaluated the performance of both an NLP ruleset developed solely using a single site's clinical narratives as well as one further refined using a synthetic derived dataset sourced from three sites (Mayo, UKen, and UMN). The single-site ruleset resulted in performances of 0.876, 0.706, and 0.694 in F-scores for Mayo, Minnesota, and Kentucky test datasets, respectively, while the multi-site NLP ruleset improved performances to 0.884, 0.769 and 0.806. The results of our use case test run inform us of the importance of a multi-site federated development, evaluation, and implementation framework.
One-sentence Summary
Addressing ETL heterogeneity and human factor variations in clinical NLP, the authors present an open development framework evaluated on a National COVID Cohort Collaborative (N3C) COVID-19 use case, where a multi-site NLP ruleset refined with synthetic data from three institutions outperformed a single-site ruleset across Mayo, Minnesota, and Kentucky test sets, achieving F-scores of 0.884, 0.769, and 0.806 compared to 0.876, 0.706, and 0.694, respectively.
Key Contributions
- The study introduces an open NLP development framework that utilizes a clinical common data model to standardize data interfacing and mitigate extraction, transformation, and loading heterogeneity across disparate electronic health record systems.
- The platform incorporates a transparent multi-site workflow and a crowdsourcing interface to coordinate corpus annotation and fuse site-specific knowledge, directly addressing human factor variations in gold standard development.
- A National COVID Cohort Collaborative use case demonstrates that a multi-site federated NLP ruleset outperforms a single-site baseline, improving F-scores from 0.876, 0.706, and 0.694 to 0.884, 0.769, and 0.806 across Mayo, Minnesota, and Kentucky test datasets.
Dataset
- The authors utilize a deidentified synthetic clinical corpus sourced from the National COVID Cohort Collaborative (N3C), structured within the OMOP Common Data Model to support clinical natural language processing workflows.
- The dataset is organized into distinct concept subsets focusing on dyspnea, nasal obstruction, loss of appetite, elevated prothrombin time, and lymphopenia. Each category pairs clinical terminology with curated synonym lists and structured extraction rules.
- For model development, the authors apply the corpus to train and evaluate concept mention extraction pipelines. They process the data through a ruleset framework that integrates regular expressions, synonym matching, and contextual tagging to parse clinical text without relying on fixed training splits or mixture ratios.
- Annotation and metadata construction follow a publicly documented guideline that standardizes labeling objectives. The authors enhance extraction accuracy by embedding semantic modifiers into the rulesets, explicitly tagging negation, uncertainty, and pre-modifiers to capture clinical context accurately across the synthetic records.
Method
The proposed framework is structured into three primary layers: the ingestion layer, the processing layer, and the persistence layer, designed to support scalable and interoperable natural language processing for clinical text. The overall architecture is illustrated in the framework diagram, which shows the flow of data from clinical sources through de-identification, processing, and storage.
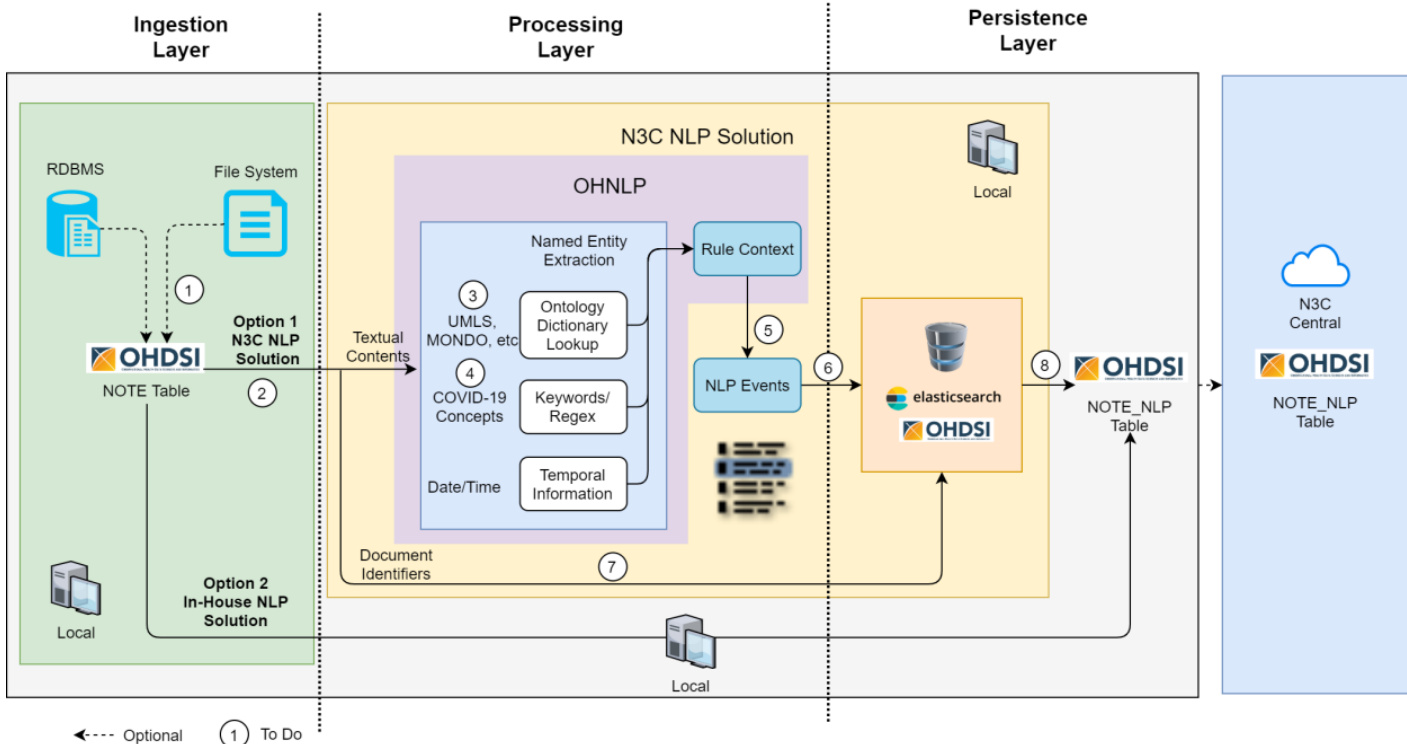
The ingestion layer is responsible for acquiring clinical text from diverse sources, including relational database management systems (RDBMS) and file systems. This layer supports multiple data input options, with the default being the OHDSI/OMOP Common Data Model (CDM) NOTE table as a standardized input format. The ingestion process is modular, allowing for configuration changes to accommodate various data sources such as Elasticsearch, Google Cloud Storage, Amazon S3, or plain text files, ensuring flexibility across different institutional infrastructures.
The processing layer functions as the core NLP engine, where textual content undergoes a series of transformations to extract clinically relevant information. This layer leverages a symbolic approach based on heuristic rules and contextual analysis, enabling transparent and interpretable outcomes. Key components include named entity recognition, ontology dictionary lookup using UMLS and MONDO, and the application of regular expressions for keyword and pattern detection. The framework supports the integration of various NLP engines, such as MedTagger, Apache cTAKES, and CLAMP, which can be selected or substituted via a standardized API. Contextual rules from the ConText algorithm are applied to modify extracted condition mentions, enriching them with temporal and clinical context. Extracted information is then structured into clinical events, which are further processed through a rule context module to incorporate domain-specific knowledge.
The persistence layer stores the resulting NLP artifacts in the OHDSI/OMOP CDM NOTE_NLP table, ensuring standardized output that can be easily integrated with downstream applications. The framework supports both local and centralized storage options, with the ability to upload processed data to a central repository like N3C Central. This layer also facilitates the use of Elasticsearch for indexing and querying the extracted NLP events, enhancing accessibility and performance. The entire pipeline is designed to be extensible, with the ability to customize rule sets and dictionaries through a web-based interface, allowing domain experts to iteratively refine and test their NLP algorithms in real time.
Experiment
There are 313 clinical notes from Mayo Clinic, 20 notes from UKen and 36 notes from UMN. Annotators were first trained using Mayo notes to gain better understanding of the annotation guidelines. Inter-annotator agreement (IAA) was calculated after annotation and corresponding discrepancies were resolved by discussions between the two annotators to generate a final gold standard dataset.
NLP algorithm development and evaluation. Using the annotated corpus, the paper developed both a single-site and multi-site NLP algorithm using a regular expression-based matching method, which has been widely adopted for information extraction in clinical settings. Specifically, for the Mayo data, the paper randomly chose 101 notes out of the 313 annotated notes as development set, 105 notes as validation set, and the remaining 107 notes were used as the testing set. For the UKen data, 10 notes were used for training and 10 for testing. For the UMN data, 18 was used for training and 18 for testing. Single-site algorithm was developed using the development set and validation set from Mayo, tested on the Mayo testing set and all data from UKen and UMN. Multi-site algorithm was generated through further refinement of the single-site algorithm using training sets from UKen and UMN and then tested on testing sets from all sites.
the paper evaluated the performance of single-site and multi-site algorithms using precision, recall, and F1-score for the annotated concept mentions, without and with certainty. A span can be represented from the start position to the end position of the concept mention. Certainty is an attribute of the concept mention including positive, negated, hypothetical and possible. For the mention-level evaluation without certainty, when there are overlaps between the gold standard mention span and the NLP detected mention span while the concept type (i.e., the specific sign/symptom such as fever, cough) is the same, it is considered a true positive (TP). If a concept mention exists in the
gold standard annotation but not detected by the NLP algorithm, or spans overlap but the concept type is not matched, it is considered as a false negative (FN). If a concept mention is detected by the algorithm but does not exist in the gold standard annotation, the concept is considered as a false positive (FP). For the mention-level span and certainty evaluation, certainty match needs to be considered when calculating TP, FN and FP. The precision, recall and F1-score are then calculated as follows. the paper further manually analyzed errors from multi-site algorithm mention-level evaluation without certainty.
P r e c i s i o n =TP+FNTP Recall=TP+FNTP F1=Precision+Recall2⋅Precision⋅Recall- Figures
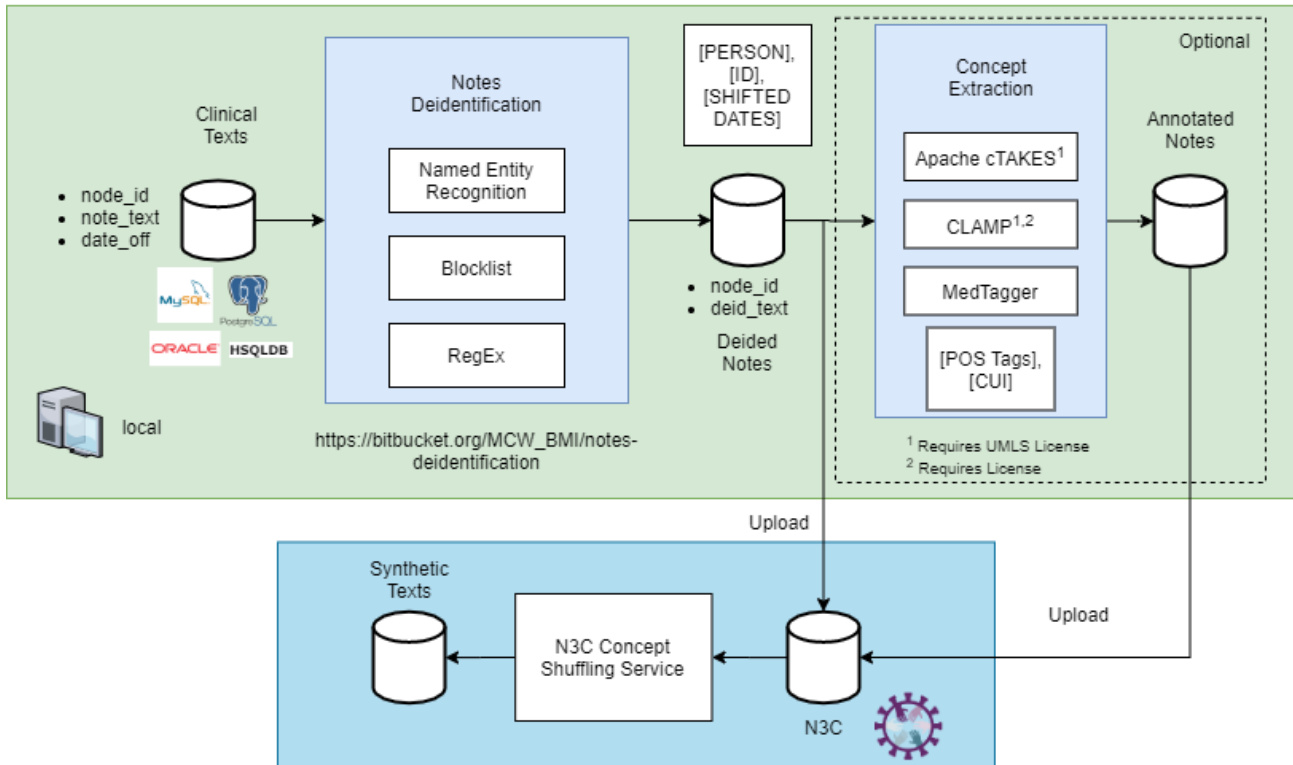
the figure. N3C deidentification and synthetic text generation workflow
the figure. Screenshots of the Web GUI
- Tables
the table. Annotation corpora statistics. (Mayo: Mayo Clinic, UKen: University of Kentucky, UMN: University of Minnesota)
the table. Performance of the single-site NLP algorithm (Mayo: Mayo Clinic, UKen: University of Kentucky, UMN: University of Minnesota)
the table. Performance of the multi-site NLP algorithm (Mayo: Mayo Clinic, UKentucky: University of Kentucky, UMN: University of Minnesota)

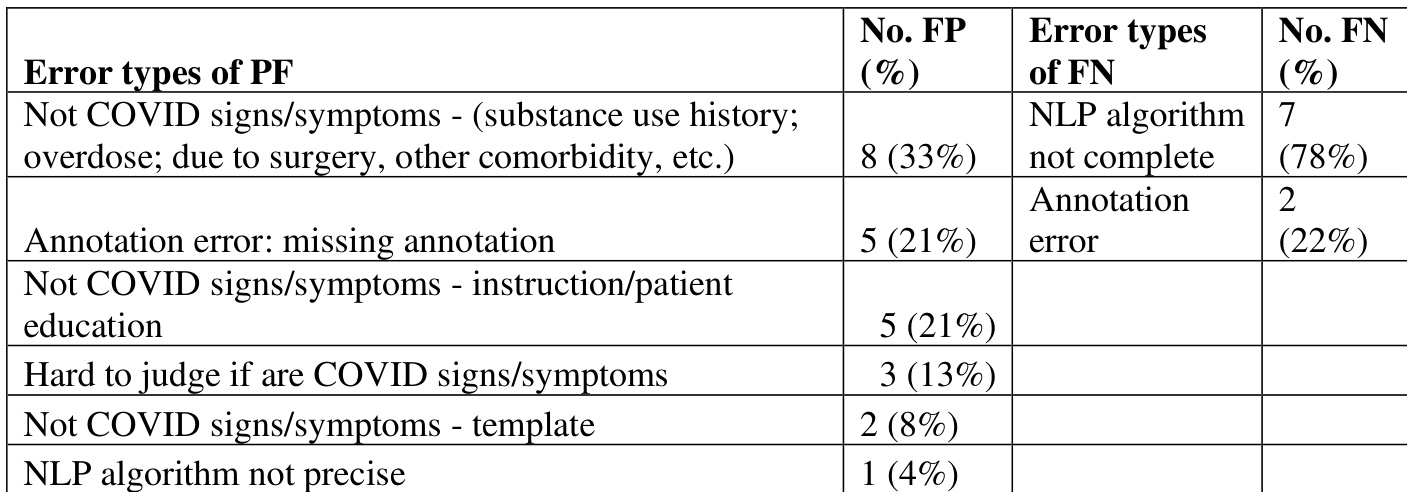
the table. Error analysis of the multi-site algorithm mention-level evaluation without certainty for Mayo site
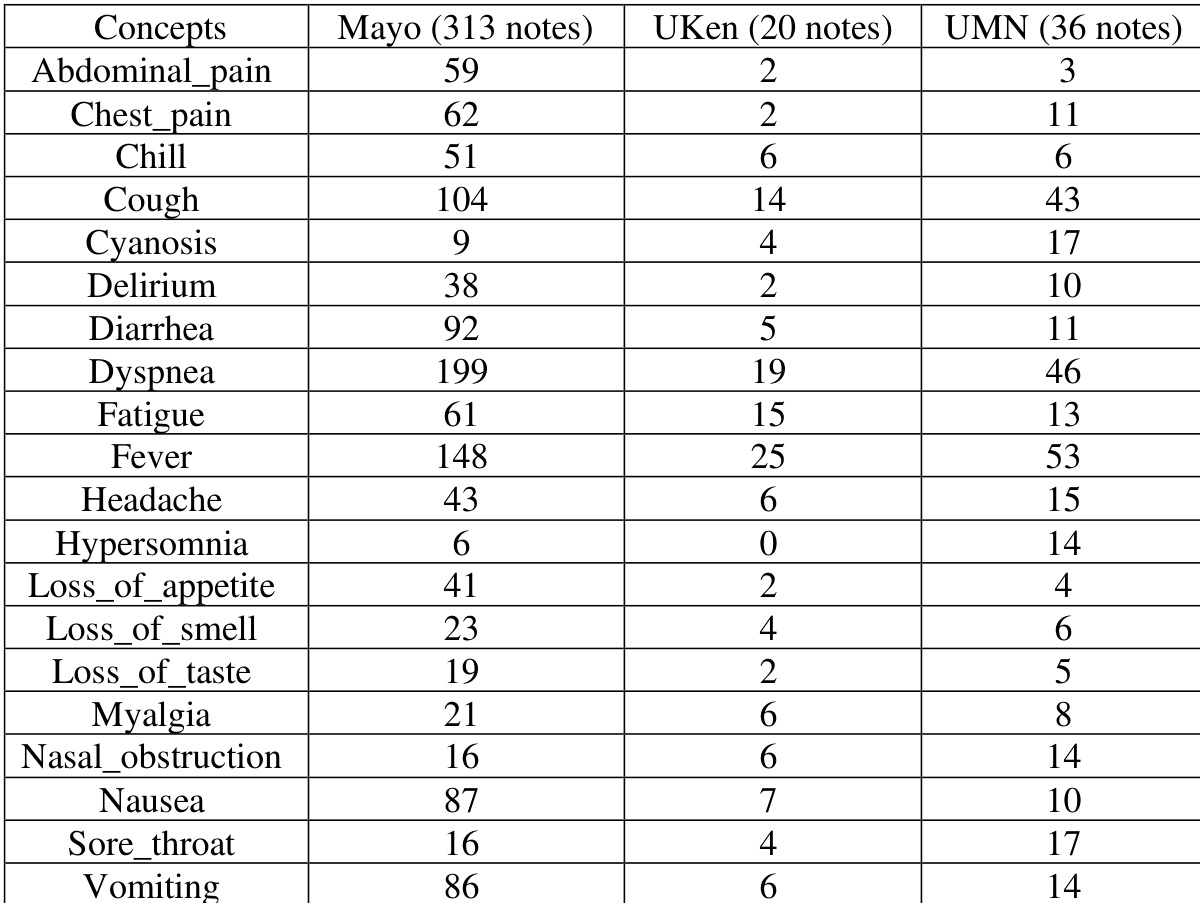
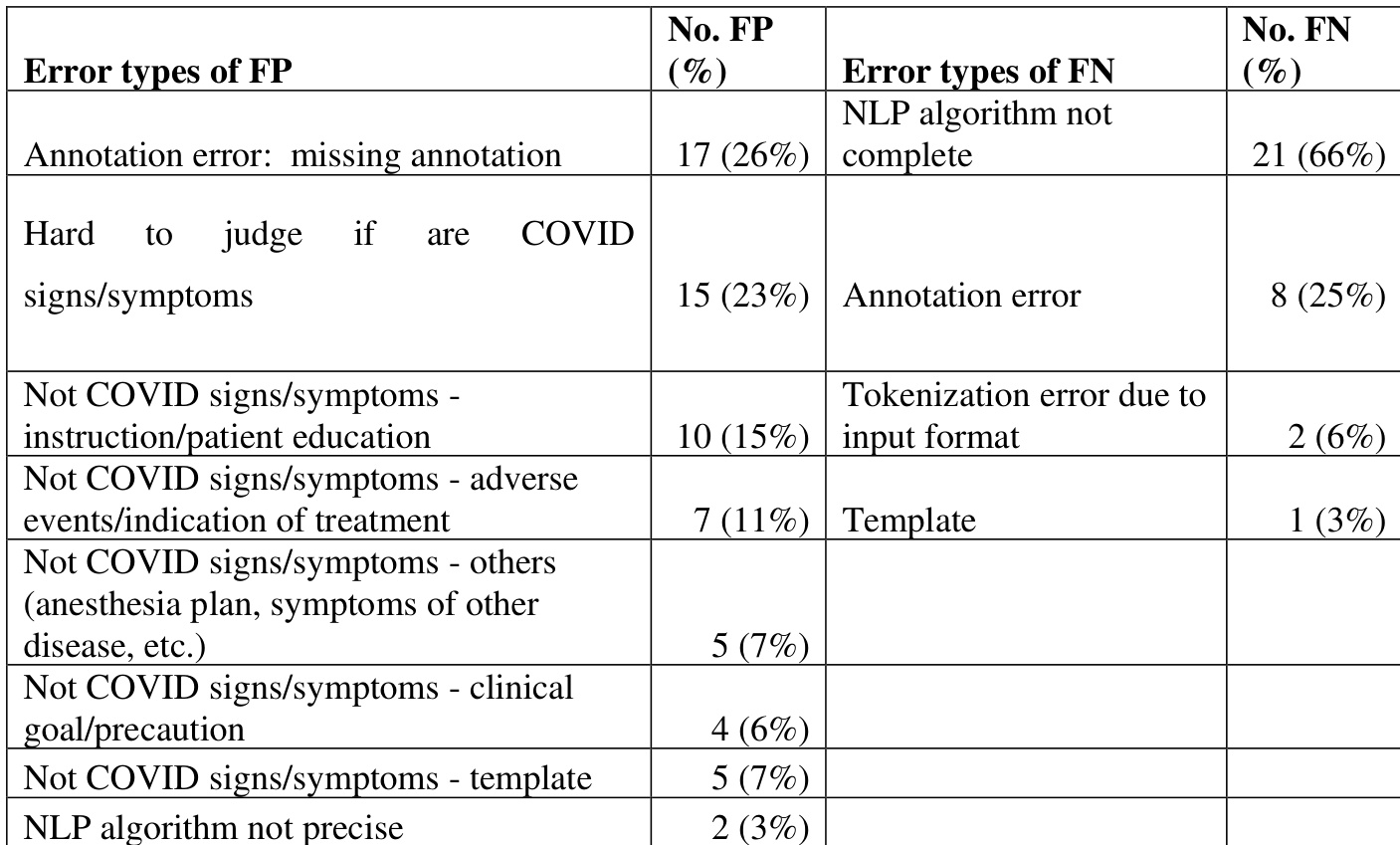
the table. Error analysis of the multi-site algorithm mention-level evaluation without certainty for UMN
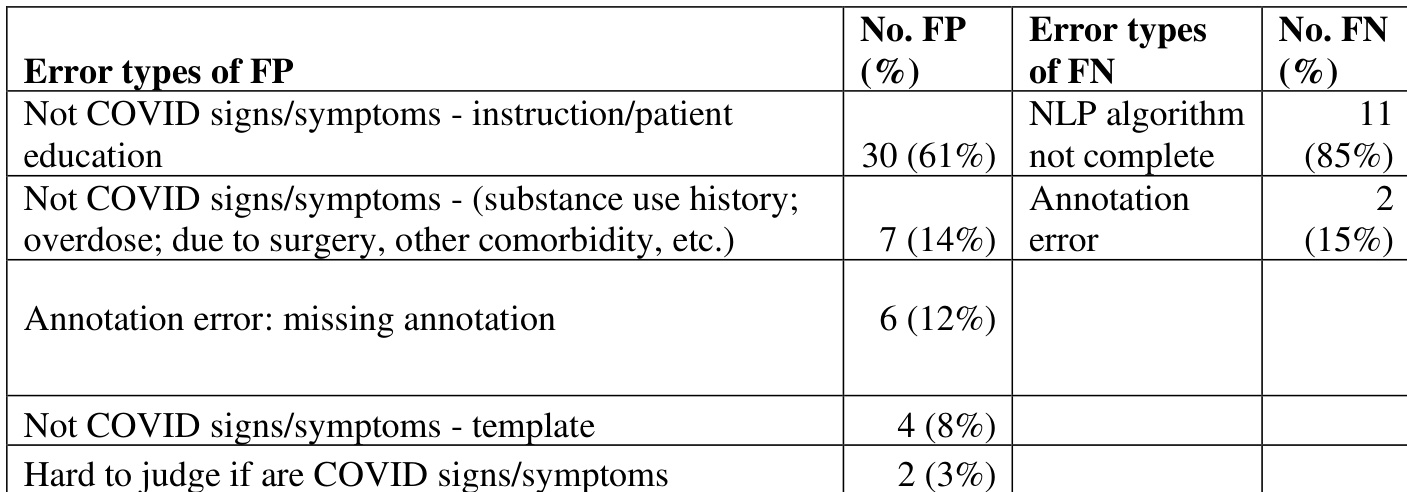
the table. Error analysis of the multi-site algorithm mention-level evaluation without certainty for UKen

The authors evaluate the performance of a single-site and multi-site NLP algorithm for extracting COVID-19 signs and symptoms from clinical notes across three institutions. Results show that the multi-site algorithm achieves higher performance compared to the single-site algorithm, with consistent trends across the datasets. The performance of both algorithms degrades when applied to sites other than the primary training site. The multi-site NLP algorithm shows improved performance over the single-site algorithm across all tested datasets. Performance degrades from the primary training site to the other sites for both algorithms. The multi-site algorithm achieves higher recall but lower precision compared to the single-site algorithm in the Span evaluation.

The authors conducted an error analysis of the multi-site NLP algorithm's performance, focusing on false positives and false negatives. The analysis reveals that the majority of false positives stem from non-COVID-related mentions such as substance use history and patient education, while false negatives are primarily due to incomplete NLP algorithms and annotation errors. False positives are mainly caused by non-COVID-related mentions such as substance use history and patient education. False negatives are primarily due to incomplete NLP algorithms and annotation errors. The error analysis indicates that a significant portion of false positives and false negatives are related to contextual misinterpretation and system limitations.
The authors conduct an error analysis of a multi-site NLP algorithm for extracting COVID-19 signs and symptoms, focusing on false positives and false negatives. The analysis reveals that the majority of false positives stem from annotation errors and non-COVID-related content, while false negatives are primarily due to incomplete annotation and tokenization issues. False positives are mainly caused by annotation errors and non-COVID-related content such as patient education and treatment instructions. False negatives are predominantly due to incomplete annotation and tokenization errors caused by the de-identification process. The error analysis highlights that both annotation and algorithmic limitations contribute significantly to performance gaps in the NLP system.
The authors evaluate the performance of a single-site and a multi-site NLP algorithm for extracting COVID-19 signs and symptoms from clinical notes across three institutions. Results show that the multi-site algorithm achieves higher performance than the single-site algorithm, with consistent improvements in F1-scores across all sites, although performance varies between sites and is generally higher on the Mayo dataset. The multi-site NLP algorithm outperforms the single-site algorithm across all evaluation metrics and sites. Performance degrades from the Mayo site to the other two sites for both NLP algorithms. The multi-site algorithm shows improved F1-scores compared to the single-site algorithm, particularly on the UMN and UKen datasets.
The authors conducted a study to evaluate the performance of NLP algorithms for extracting COVID-19 signs and symptoms from clinical notes across multiple sites. Results show that a multi-site NLP algorithm improved performance compared to a single-site algorithm, with higher F-scores across all sites, although performance decreased from the Mayo site to the other sites. The annotation data revealed significant differences in the frequency of symptom mentions across institutions, with Mayo showing higher counts for most symptoms. The multi-site NLP algorithm demonstrated better performance than the single-site algorithm across all sites. Performance of the NLP algorithms degraded from the Mayo site to the other sites, indicating site-specific variability. The annotation data revealed substantial differences in symptom prevalence across institutions, with Mayo showing higher counts for most symptoms.
The authors evaluated single-site and multi-site natural language processing algorithms for extracting COVID-19 clinical signs and symptoms across three institutions, with comparative trials validating cross-site generalization and subsequent error analysis identifying failure modes. The experiments consistently demonstrate that the multi-site approach outperforms the single-site baseline, although both models exhibit performance degradation when applied to non-training sites. Error analysis reveals that misclassifications primarily arise from contextual misinterpretations, non-COVID-related clinical documentation, and annotation inconsistencies rather than inherent algorithmic flaws. These findings underscore the value of multi-institutional training data while highlighting how documentation variability and annotation quality significantly influence system reliability.