Command Palette
Search for a command to run...
r-GAT: Relational Graph Attention Network for Multi-Relational Graphs
r-GAT: Relational Graph Attention Network for Multi-Relational Graphs
Meiqi Chen Yuan Zhang Xiaoyu Kou Yuntao Li Yan Zhang
Graph Attention Networks (GAT)
Abstract
Graph Attention Network (GAT) focuses on modelling simple undirected and single relational graph data only. This limits its ability to deal with more general and complex multi-relational graphs that contain entities with directed links of different labels (e.g., knowledge graphs). Therefore, directly applying GAT on multi-relational graphs leads to sub-optimal solutions. To tackle this issue, we propose r-GAT, a relational graph attention network to learn multi-channel entity representations. Specifically, each channel corresponds to a latent semantic aspect of an entity. This enables us to aggregate neighborhood information for the current aspect using relation features. We further propose a query-aware attention mechanism for subsequent tasks to select useful aspects. Extensive experiments on link prediction and entity classification tasks show that our r-GAT can model multi-relational graphs effectively. Also, we show the interpretability of our approach by case study.
One-sentence Summary
The authors propose r-GAT, a relational graph attention network that extends standard GAT to multi-relational graphs by learning multi-channel entity representations, where each channel captures a distinct latent semantic aspect, and by employing relation-specific neighborhood aggregation alongside a query-aware attention mechanism to select useful aspects for link prediction and entity classification tasks.
Key Contributions
- The paper introduces r-GAT, a relational graph attention network that learns multi-channel entity representations by mapping each channel to a latent semantic aspect and aggregating neighborhood information through relation features.
- The architecture incorporates a query-aware attention mechanism to select relevant semantic aspects for downstream tasks, and it prevents over-parameterization by avoiding dedicated parameters for specific relation types.
- Extensive experiments on link prediction and entity classification tasks demonstrate the effectiveness and parameter efficiency of r-GAT relative to existing GNN-based approaches, with case studies confirming the interpretability of the attention weights.
Introduction
Graph attention networks have demonstrated strong performance in processing graph-structured data for applications like knowledge graph completion and text classification. However, most existing models are designed for single-relation graphs and struggle with multi-relational graphs where edges carry distinct semantic meanings. Standard attention mechanisms ignore relation-specific features, forcing the network to learn static, generic representations that cannot disentangle different semantic aspects or adapt to specific downstream queries. Prior multi-relational approaches often suffer from over-parameterization as relation types increase, or they fail to dynamically adjust neighbor importance based on relation context. To overcome these limitations, the authors propose r-GAT, a relational graph attention network that projects entities and relations into independent semantic channels. By integrating relation features directly into the attention mechanism, the model dynamically weights neighbors according to their semantic context and disentangles entity representations into distinct components. The authors further enhance this framework with a query-aware attention mechanism that selectively activates relevant semantic aspects for downstream tasks, delivering improved performance, parameter efficiency, and model interpretability.
Dataset
- Dataset Composition and Sources: The authors evaluate their r-GAT model using two categories of multi-relational graph datasets sourced from Freebase and WordNet.
- Subset Details:
- FB15k-237: A filtered knowledge graph subset derived from Freebase. Reverse relations are removed to eliminate trivial prediction shortcuts and increase task difficulty.
- WN18RR: A curated subset of WordNet. It applies strict filtering to prevent test leakage caused by simply inverting training triplets.
- AIFB, MUTAG, and BGS: Three standard datasets reserved exclusively for the entity classification task. Full statistics and metadata are documented in the paper's reference tables and appendix.
- Data Usage and Processing: The datasets are not combined into a single mixture. The authors apply them as independent benchmark splits to evaluate two distinct tasks: link prediction using FB15k-237 and WN18RR, and entity classification using AIFB, MUTAG, and BGS. Standard preprocessing aligns each subset with established multi-relational graph evaluation protocols.
- Additional Processing Notes: The primary processing step involves relation filtering to remove reverse links and prevent data leakage. No cropping strategies are employed, and the graphs are maintained in their original structural format after cleaning.
Method
The authors propose r-GAT, a relational graph attention network designed to model multi-relational graphs by learning disentangled entity representations across multiple semantic aspects. The framework operates by decomposing entity and relation features into K independent channels, where each channel captures a distinct latent semantic aspect of an entity. This decomposition enables the model to perform relation-aware neighborhood aggregation, allowing the contribution of neighboring entities to be weighted according to both the entity features and the relation features connecting them.
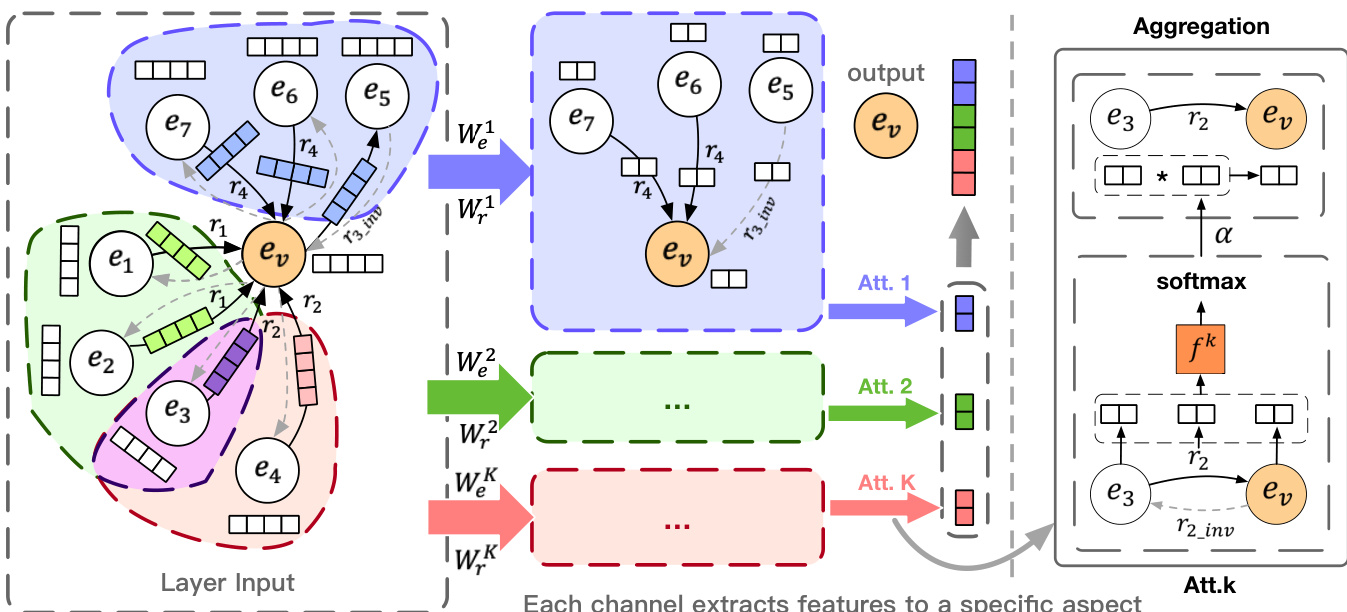
As shown in the figure below, the architecture processes entity and relation features through a series of K parallel channels. Each channel applies a learnable projection matrix to transform the input entity and relation features into a shared subspace. For an edge (v,i,u), the projected entity features evk=Wekev and relation features rik=Wrkri are used to compute an attention score that measures the relevance of neighbor u to entity v under the k-th semantic aspect. The attention mechanism is defined as attviuk=fk[evk∣∣rik∣∣euk], where fk is a feedforward network. The attention scores are normalized using a softmax function over all neighbors and relations connected to v, resulting in αviuk, which quantifies the importance of neighbor u for the k-th aspect of v.
The aggregated representation for entity v in the k-th channel is then computed as evk(l)=σ1(∑u∈Nv∑i∈Rv,uαviuk[euk∗rik]), where the multiplication ∗ combines the neighbor's entity features with the relation features. The final disentangled entity representation ev(l) is obtained by concatenating the outputs from all K channels, resulting in a feature vector of dimension De(l). This process is repeated across multiple layers to capture higher-order neighborhood information.
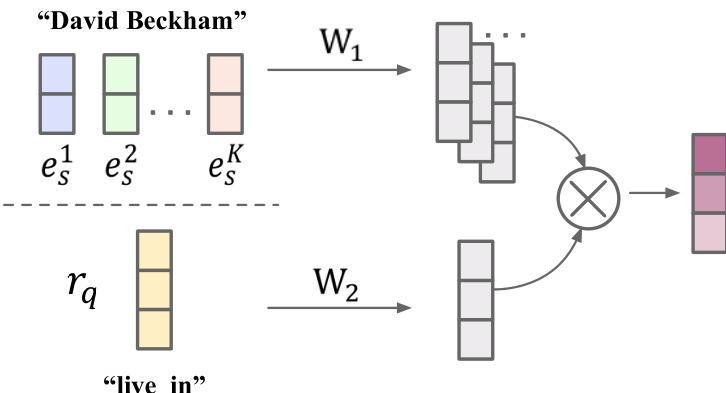
For downstream tasks, the model incorporates a query-aware attention mechanism to adapt the disentangled representations to specific query relations. Given a query relation q and a subject entity s, the importance of each semantic aspect k of s to q is computed as βsqk=softmaxk(Dq(W1esk)T(W2rq)). This attention weight is used to produce a query-aware entity embedding Q(es,rq), which combines the relevant aspects of s with the query relation. This mechanism enables the model to focus on semantically relevant features when performing tasks such as link prediction, mitigating the query-ignorant problem inherent in traditional GNN-based approaches.
Experiment
The evaluation utilizes standard link prediction and entity classification protocols across multiple benchmark datasets, comparing the proposed method against a comprehensive set of graph neural network and knowledge graph embedding baselines. Overall results demonstrate that the model effectively disentangles entity features into multiple semantic channels, enabling it to capture complex relational contexts and outperform existing approaches. Ablation studies further validate that both the query-aware attention mechanism and the multi-channel architecture are essential for dynamic, query-specific reasoning, as single-channel variants degrade to generic embeddings. Finally, case studies highlight the model's interpretability by revealing how distinct relations dynamically prioritize semantically relevant entity facts through specialized channels, aligning with human commonsense expectations.
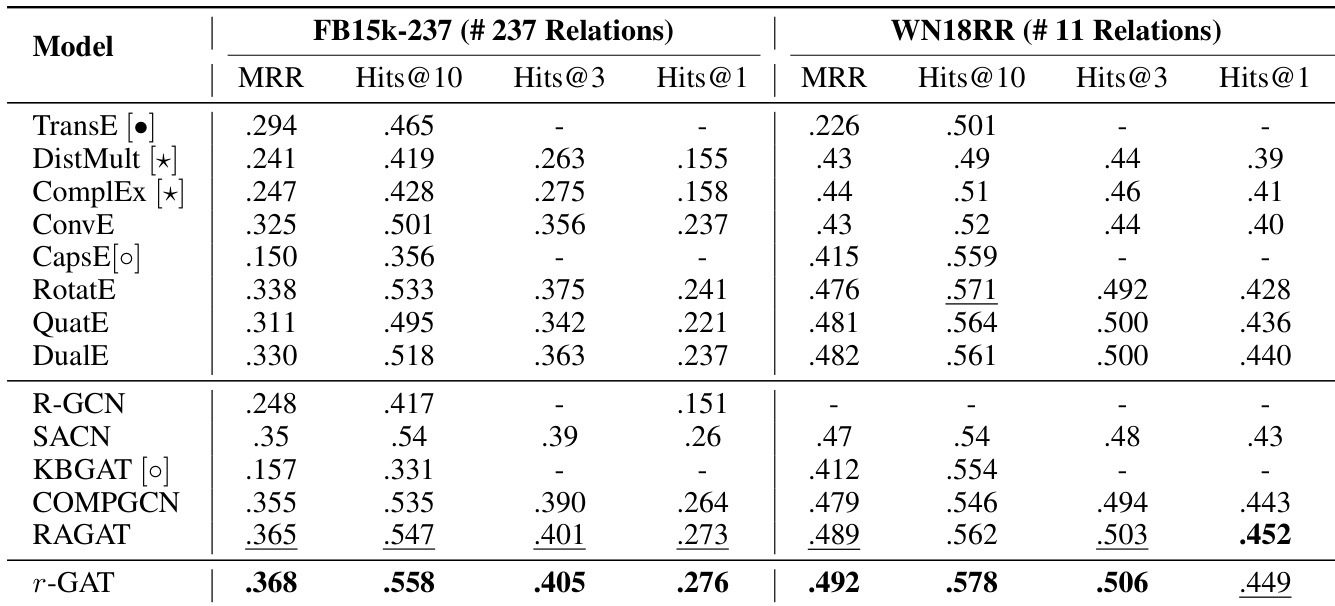
The authors present a comparison of their r-GAT model against various state-of-the-art approaches on link prediction tasks across two datasets, FB15k-237 and WN18RR. Results show that r-GAT achieves competitive performance on both datasets, with notable improvements on FB15k-237, indicating its effectiveness in handling complex relational contexts. The model outperforms other GNN-based and KGE methods, particularly in terms of Hits@10 and MRR, suggesting that the disentangled feature representation and query-aware attention mechanism contribute to better performance. r-GAT achieves the best performance on FB15k-237 across multiple metrics, demonstrating its effectiveness in handling complex relational data. r-GAT outperforms strong baselines on both datasets, with significant improvements on Hits@10 and MRR, highlighting the benefits of disentangled feature learning. The model's performance is particularly strong on FB15k-237, which has a richer relational structure, suggesting its ability to capture intricate context information.
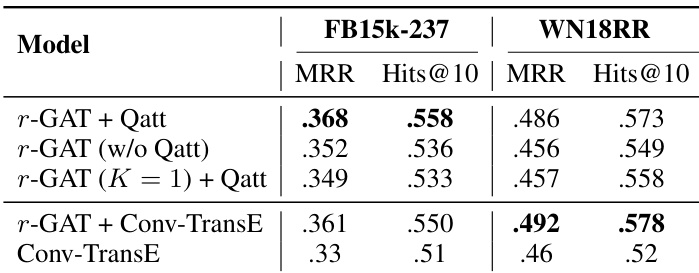
The authors evaluate their proposed r-GAT model on link prediction tasks, comparing it against various baselines and ablation variants. Results show that the full model with query-aware attention achieves the best performance, while removing this component or using a single channel significantly degrades results. The model also outperforms Conv-TransE when combined with it, particularly on challenging cases involving high-degree entities. The full r-GAT model with query-aware attention achieves the best performance on both datasets compared to its ablated versions. Removing the query-aware attention mechanism leads to a notable drop in performance, highlighting its importance. Combining r-GAT with Conv-TransE improves results over Conv-TransE alone, especially for high-degree entities.
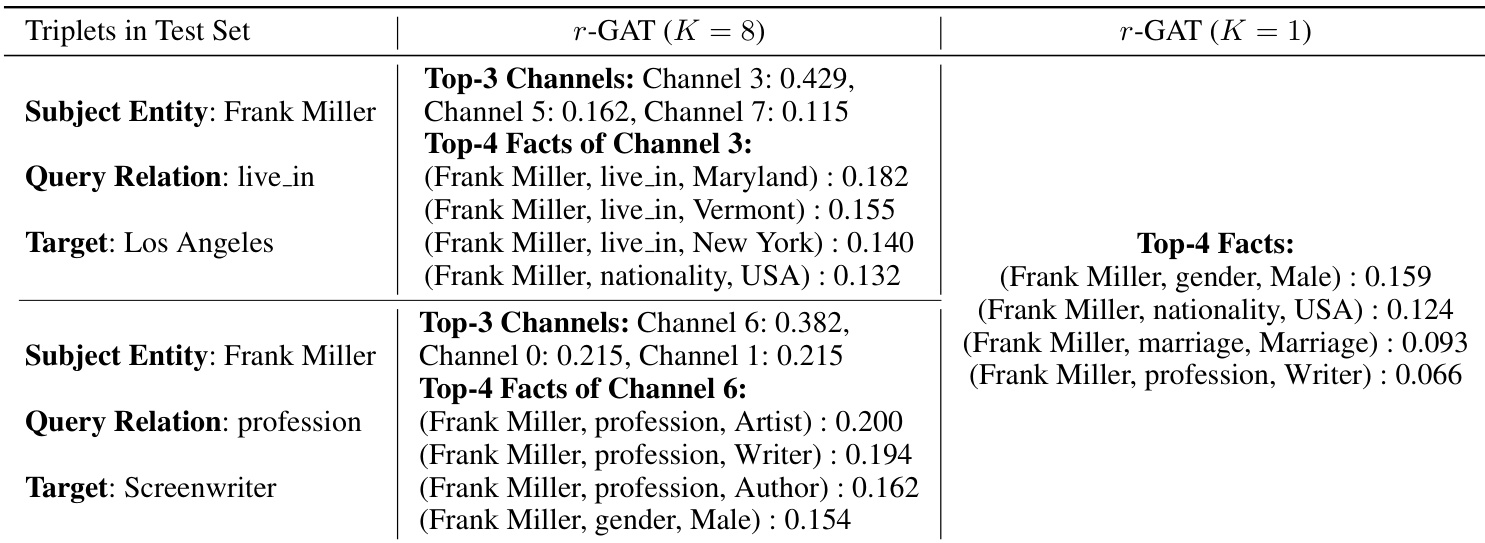
The authors present a case study demonstrating the interpretability of their r-GAT model through link prediction examples. The the the table shows that different query relations lead to distinct attention patterns across multiple disentangled channels, highlighting the model's ability to adapt its focus to relevant facts based on the query. In contrast, a single-channel version of the model produces static and less discriminative attention, failing to capture query-specific relevance. Different query relations activate distinct sets of disentangled channels, enabling the model to focus on semantically relevant facts. The model's attention mechanism allows dynamic weighting of known facts based on the query relation, enhancing interpretability. A single-channel variant lacks query-awareness and produces uniform attention, reducing its ability to distinguish relevant information.
The authors conduct experiments on link prediction and entity classification tasks using multiple datasets, comparing their proposed r-GAT model against various GNN-based and KGE baselines. Results show that r-GAT achieves state-of-the-art performance on FB15k-237 and outperforms all previous approaches on entity classification across all datasets, demonstrating the effectiveness of disentangled entity features and query-aware attention. r-GAT achieves state-of-the-art results on FB15k-237 and competitive results on WN18RR for link prediction. r-GAT outperforms all baseline methods on entity classification across all datasets. Ablation studies confirm the importance of query-aware attention and multi-channel disentanglement for performance improvement.

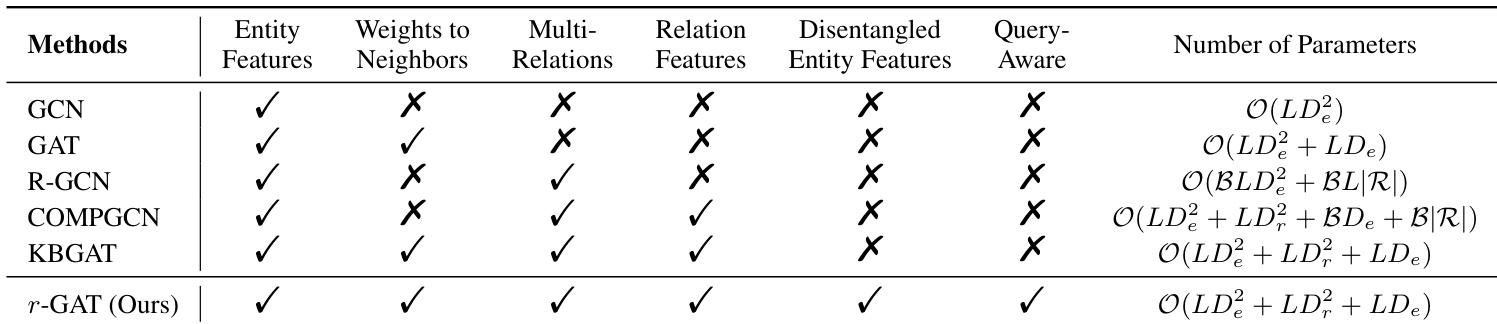
The authors compare their proposed r-GAT model with several baseline methods, highlighting that r-GAT incorporates multiple features including entity features, weights to neighbors, multi-relations, disentangled entity features, and query-aware mechanisms. The the the table shows that r-GAT is the only method among the listed approaches that utilizes all these components, which contributes to its superior performance in both link prediction and entity classification tasks. r-GAT is the only method that uses all the features listed in the the the table, including disentangled entity features and query-aware mechanisms. The inclusion of query-aware mechanisms in r-GAT allows it to adapt to different query relations by focusing on relevant disentangled channels. r-GAT outperforms all baseline models on both link prediction and entity classification tasks, demonstrating the effectiveness of its comprehensive feature integration.
The r-GAT model was evaluated on link prediction and entity classification tasks across the FB15k-237 and WN18RR datasets, benchmarked against multiple graph neural network and knowledge graph embedding baselines. Comparative experiments demonstrate its superior predictive accuracy on complex relational data, while ablation studies confirm that removing query-aware attention or multi-channel disentanglement significantly degrades performance. Interpretability case analyses further validate that the architecture dynamically routes attention to query-specific facts, contrasting sharply with the static behavior of single-channel alternatives. Collectively, these findings establish that integrating disentangled features with adaptive attention mechanisms substantially enhances both model effectiveness and interpretability.