Command Palette
Search for a command to run...
PyTorch Basics — Training Faster R-CNN
Abstract
One-sentence Summary
Pkwrap is a PyTorch package that integrates Kaldi’s LF-MMI training framework by exposing its cost function as an autograd operation, enabling flexible acoustic model architecture design while preserving Kaldi’s parallel training capabilities and decoding with Kaldi-created graphs.
Key Contributions
- The paper introduces pkwrap, a simple wrapper that integrates Kaldi's LF-MMI training framework into PyTorch for acoustic model development.
- The framework exposes the LF-MMI cost function as an autograd function, enabling researchers to design custom model architectures while maintaining Kaldi's optimization objectives.
- Additional Kaldi functionalities are ported to PyTorch, including parallel training routines for environments without multiple GPUs and decoding support for graphs generated in Kaldi.
Introduction
The authors address the growing need for streamlined, reproducible workflows in speaker recognition systems that rely on TDNN and TDNN-F architectures. Prior approaches often suffer from fragmented tooling, hard-coded recipe components, and excessive boilerplate that complicates model training and experimental iteration. To overcome these bottlenecks, the authors introduce a modular software package that standardizes core functionalities like feature extraction and data management while providing extensible Trainer classes for simplified training loops. Their development roadmap also prioritizes automated context generation and integrated LDA and PLDA backends, ultimately lowering the barrier to entry for robust speaker recognition research and deployment.
Dataset

- Composition and Sources: The authors utilize four speech datasets for acoustic model development: MiniLibriSpeech, Switchboard, BABEL, and LibriSpeech (100h).
- Subset Details: MiniLibriSpeech and Switchboard function as monolingual corpora, while BABEL provides a multilingual setup. The LibriSpeech subset is explicitly limited to 100 hours of audio.
- Training Usage and Processing: MiniLibriSpeech, Switchboard, and BABEL rely on forced alignments to guide training, whereas the 100h LibriSpeech setup employs a flat start approach that requires no prior alignments. The authors structure these recipes to validate the PyTorch LF MMI framework against an equivalent Kaldi baseline with identical hyperparameters.
- Additional Processing Notes: The provided experimental setup does not detail specific audio cropping strategies or custom metadata construction beyond the alignment dependencies noted above.
Method
The authors leverage a modular framework designed to integrate Kaldi’s lattice-free maximum mutual information (LF-MMI) training capabilities into PyTorch, enabling users to train acoustic models with the flexibility of modern deep learning tooling. The core of this integration is a Python package named pkwrap, which acts as a lightweight wrapper around Kaldi’s C++ library, exposing key functionalities through PyTorch-compatible interfaces. The framework is structured into two main components: a C++ backend that handles low-level operations such as matrix conversions between Kaldi and PyTorch, and a Python interface that users interact with directly. This separation allows for efficient data handling while maintaining ease of use.
At the heart of the training process is the LF-MMI cost function, which is exposed as a custom autograd function using PyTorch’s torch.autograd.Function interface. This is implemented through the KaldiChainObjfFunction class, enabling seamless gradient computation within PyTorch’s computational graph. The function accepts parameters such as the weight on the cross-entropy term via an options class that mirrors Kaldi’s ChainTrainingOptions, allowing users to configure training behavior without modifying the underlying C++ code. The computation of the cost is performed by Kaldi itself, with minimal data transfer overhead, as only memory pointers are passed between the two systems.
The training framework supports two primary methods for LF-MMI training: one that uses alignments from a pre-trained model (e.g., HMM/GMM) and another that performs flat-start training using a full-biphone tree. Both are supported through the package’s recipes, which include scripts for training and decoding. The recipes currently rely on Kaldi for generating training examples and sequences, though these steps are encapsulated through subprocess calls. The user can access the resulting files, typically stored in the egs/ directory, for further analysis or use.
For model architecture, the framework includes implementations of Time-Delay Neural Networks (TDNN) and Factorized TDNN as standard torch.nn.Module classes. Context information for TDNN models must be specified manually, reflecting the current design’s emphasis on flexibility and control. The training process employs an exponential learning rate decay schedule, consistent with Kaldi’s standard practices.
To address distributed training limitations in PyTorch, especially in environments without multi-GPU setups, the framework supports Natural Gradient Stochastic Gradient Descent (NG-SGD) by exposing Kaldi’s natural gradient computations. This is achieved through a custom PyTorch function that performs a linear transformation during the forward pass and invokes Kaldi’s natural gradient logic during the backward pass. The implementation mirrors Kaldi’s use of NaturalGradientAffineTransform and NGState, ensuring compatibility with existing training workflows. [[IMG:]]
Experiment
The evaluation compares the PyTorch-based Pkwrap framework against the traditional Kaldi toolkit across standard English, multilingual, and flat-start speech recognition tasks to validate framework interoperability and training compatibility. These experiments assess how alternative optimization algorithms and architectural configurations perform under diverse acoustic conditions and language modeling setups. Qualitatively, Pkwrap consistently matches or surpasses established Kaldi baselines across all datasets, demonstrating reliable convergence and competitive recognition accuracy despite differing initialization and training strategies. Overall, the results confirm that Pkwrap provides a robust, PyTorch-native alternative for modern speech recognition pipelines without sacrificing performance.
The authors compare the performance of Kaldi and Pkwrap frameworks on speech recognition tasks using Word Error Rate as the metric. Results show that Pkwrap achieves lower WER than Kaldi across multiple datasets, indicating competitive or superior performance in certain configurations. Pkwrap achieves lower Word Error Rate than Kaldi on the Minilibrispeech dataset. Pkwrap outperforms Kaldi in Word Error Rate on the Switchboard task, particularly on the SWBD and CH subsets. Pkwrap demonstrates improved performance compared to Kaldi on multilingual BABEL datasets and the Librispeech 100-hour subset.

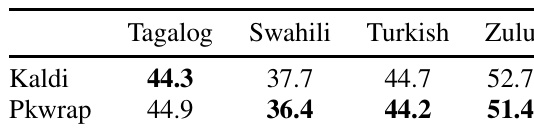
The authors compare the performance of Kaldi and Pkwrap frameworks on multilingual speech recognition tasks using the BABEL dataset. Results show that Pkwrap achieves lower word error rates than Kaldi across all four target languages, indicating better performance in the multilingual modeling setup. Pkwrap outperforms Kaldi in word error rate across all four BABEL target languages. Pkwrap achieves lower word error rates compared to Kaldi on Tagalog, Swahili, Turkish, and Zulu. The results demonstrate consistent performance improvements of Pkwrap over Kaldi in multilingual speech recognition tasks.
The authors compare the performance of Kaldi and Pkwrap frameworks on speech recognition tasks using TDNN models across different datasets. Results show that Pkwrap achieves lower word error rates than Kaldi on the Switchboard and Callhome subsets, with improvements observed under both 3-gram and 4-gram language models, particularly when i-vectors and LDA are not used. Pkwrap outperforms Kaldi on both SWBD and CH subsets of the Switchboard dataset with lower word error rates. The performance gap between Pkwrap and Kaldi is more pronounced under 4-gram language models compared to 3-gram models. Pkwrap achieves competitive results on Switchboard even without using i-vectors or LDA preprocessing, unlike the Kaldi baseline.

The authors compare the performance of Kaldi and Pkwrap frameworks on the Librispeech dataset using TDNN models. Results show that Pkwrap achieves lower word error rates than Kaldi across all evaluated subsets, indicating better performance in the flat-start modeling setup. Pkwrap outperforms Kaldi on all evaluated subsets of the Librispeech dataset. Pkwrap achieves lower word error rates compared to Kaldi on both dev-clean and test-clean subsets. Pkwrap shows consistent improvement over Kaldi on dev-other and test-other subsets.

The authors present a comparison of acoustic model performance between Kaldi and Pkwrap frameworks across multiple datasets, including Minilibrispeech, Switchboard, and BABEL. The results indicate that Pkwrap achieves competitive or improved performance relative to Kaldi in several settings, particularly in multilingual and flat-start modeling scenarios. Pkwrap demonstrates competitive performance with Kaldi in multilingual speech recognition on the BABEL dataset. Pkwrap achieves relative improvements in word error rates compared to Kaldi on the Switchboard evaluation sets. The framework shows effectiveness in flat-start training on the Librispeech 100-hour subset, using different optimization strategies and model architectures.
The evaluation setup compares the Pkwrap framework against the Kaldi baseline across multiple speech recognition tasks, including monolingual, multilingual, and flat-start modeling scenarios. These experiments validate the framework's performance across diverse datasets like Librispeech, Switchboard, and BABEL while testing various TDNN configurations, language model orders, and preprocessing pipelines. Qualitatively, Pkwrap consistently achieves superior recognition accuracy regardless of the specific dataset or architectural setup, with notable advantages in multilingual environments and reduced preprocessing workflows. Overall, the findings confirm that Pkwrap serves as a robust and highly competitive alternative to traditional speech recognition baselines.