Command Palette
Search for a command to run...
Test-time adaptable neural networks for robust medical image segmentation
Test-time adaptable neural networks for robust medical image segmentation
Neerav Karani Ertunc Erdil Krishna Chaitanya Ender Konukoglu
GLIGEN (Language-to-Image Generation Network)
Abstract
Convolutional Neural Networks (CNNs) work very well for supervised learning problems when the training dataset is representative of the variations expected to be encountered at test time. In medical image segmentation, this premise is violated when there is a mismatch between training and test images in terms of their acquisition details, such as the scanner model or the protocol. Remarkable performance degradation of CNNs in this scenario is well documented in the literature. To address this problem, we design the segmentation CNN as a concatenation of two sub-networks: a relatively shallow image normalization CNN, followed by a deep CNN that segments the normalized image. We train both these sub-networks using a training dataset, consisting of annotated images from a particular scanner and protocol setting. Now, at test time, we adapt the image normalization sub-network for each test image, guided by an implicit prior on the predicted segmentation labels. We employ an independently trained denoising autoencoder (DAE) in order to model such an implicit prior on plausible anatomical segmentation labels. We validate the proposed idea on multi-center Magnetic Resonance imaging datasets of three anatomies: brain, heart and prostate. The proposed test-time adaptation consistently provides performance improvement, demonstrating the promise and generality of the approach.
One-sentence Summary
The authors propose a test-time adaptable neural network that sequences a shallow image normalization CNN followed by a deep segmentation CNN, dynamically adapting the former at inference using a denoising autoencoder to model anatomical priors, thereby consistently improving multi-center MRI segmentation accuracy across the brain, heart, and prostate under scanner and protocol mismatches.
Key Contributions
- A two-stage segmentation architecture decouples a shallow image normalization network from a deep segmentation network to address performance degradation under scanner and protocol mismatches.
- The normalization sub-network is adapted at test time for each individual image using an implicit anatomical prior modeled by an independently trained denoising autoencoder.
- Experiments on multi-center magnetic resonance imaging datasets for the brain, heart, and prostate demonstrate that the proposed test-time adaptation strategy consistently yields performance improvements.
Introduction
Convolutional neural networks for medical image segmentation frequently degrade when applied to data acquired with unseen scanners or protocols. Prior research has tackled this domain generalization challenge by extracting domain invariant features, applying data augmentation, enforcing shape constraints, or relying on probabilistic generative models. These methods, however, generally require multiple source domains during training and cannot adjust to novel data distributions at inference time. The authors leverage test-time adaptation to dynamically fine-tune a pre-trained segmentation network for each individual scan. This strategy eliminates the need to capture all possible acquisition variations upfront, delivering robust cross-domain performance while remaining fully compatible with existing domain-invariant training pipelines.
Dataset
- Dataset composition and sources
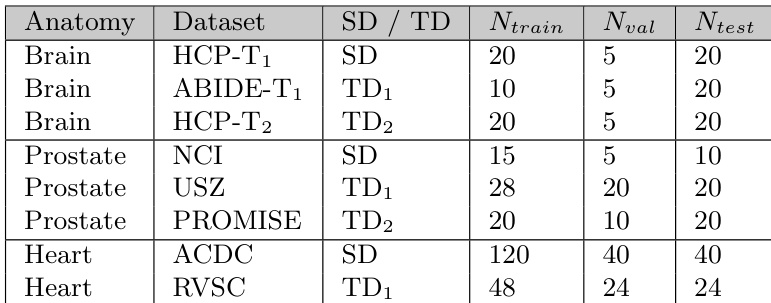
- The authors evaluate their method across three anatomical regions using multiple public and private MRI datasets.
- Brain MRI: Sourced from the Human Connectome Project (HCP) and Autism Brain Imaging Data Exchange (ABIDE).
- Prostate MRI: Sourced from the National Cancer Institute (NCI) dataset, PROMISE12, and a private collection from the University Hospital of Zurich (USZ).
- Cardiac MRI: Sourced from the Automated Cardiac Diagnosis Challenge (ACDC) and the Right Ventricle Segmentation Challenge (RVSC).
- Key details for each subset
- The authors designate one dataset per anatomy as the source domain (SD) for training and the remaining datasets as target domains (TDs) for testing.
- Brain: HCP-T1w serves as the SD, while ABIDE-Caltech-T1w and HCP-T2w act as TDs. The authors generate pseudo ground truth for all 15 cortical and subcortical labels using FreeSurfer due to the absence of manual annotations.
- Prostate: NCI is the SD, with PROMISE12 and USZ as TDs. The SD and USZ provide annotations for the central gland and peripheral zone, while PROMISE12 only labels the whole gland. The authors evaluate predictions for both the whole gland and its sub-regions.
- Cardiac: ACDC is the SD and RVSC is the TD. Since only the right ventricle endocardium is annotated in both, the authors evaluate domain generalization solely on this structure and treat all other predictions as background.
- Exact training, validation, and test split counts are documented in the paper's Table 1.
- How the paper uses the data
- The authors train the segmentation network exclusively on the SD without mixing datasets, then test it on the TDs to measure domain generalization.
- They train a 2D segmentation CNN for inference and a 3D denoising autoencoder (DAE) for domain adaptation, selecting the best DAE model based on denoising performance over a corrupted validation subset of the SD.
- For brain domain shifts involving protocol changes, they employ an atlas-based initialization strategy using averaged one-hot labels from the SD to guide early optimization.
- Cropping strategy, metadata construction, and processing details
- The authors remove bias fields with the N4 algorithm and apply per-image intensity normalization using the 1st and 99th percentiles, clipping values to a 0 to 1 range.
- Brain images undergo skull stripping to zero out non-brain voxels.
- All images are rescaled to fixed in-plane pixel dimensions (0.7 mm² for brain, 0.625 mm² for prostate, and 1.33 mm² for cardiac) and cropped or zero-padded to a uniform 256x256 resolution for the 2D network.
- For the 3D DAE, the authors rescale voxel dimensions to 2.8x0.7x0.7 mm³ (brain), 2.5x0.625x0.625 mm³ (prostate), and 5.0x1.33x1.33 mm³ (cardiac), then pad or crop to fixed volumes of 64x256x256 or 32x256x256.
- Predictions are rescaled back to the original spatial resolution before evaluation to prevent bias.
- Training augmentation includes random translation, rotation, scaling, and elastic deformations, with cardiac data additionally receiving 90-degree rotations and axis flips. Intensity augmentations include gamma correction, brightness shifts, and additive Gaussian noise.
- The DAE is trained with geometric augmentations on labels and uses a patch-based corruption process capped at 200 copied patches of maximum size 20.
Method
The proposed method designs a segmentation CNN as a concatenation of two sub-networks: a shallow image normalization module, Nϕ, followed by a deep segmentation network, Sθ. This framework, referred to as segCNN, models the transformation from the input image space to the space of segmentations as Z=Sθ(Nϕ(X)). The overall architecture is trained on a source domain (SD) dataset, DSD, to estimate the optimal parameters {θ∗,ϕ∗} by minimizing a supervised loss function, as defined in Equation 1. The training process involves a standard supervised learning objective, where the network's predictions are compared against ground truth labels.
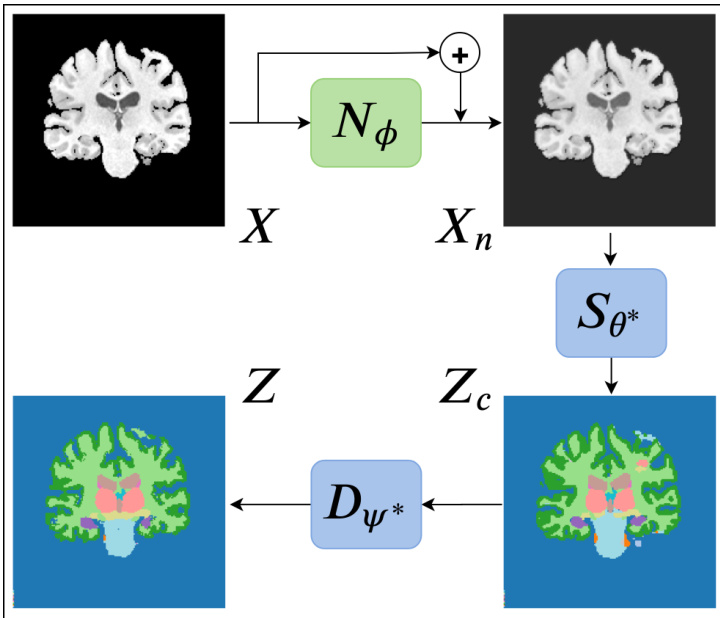
Refer to the framework diagram for a visual representation of the method. The diagram illustrates the workflow: an input image X is first processed by the adaptable normalization module Nϕ to produce a normalized image Xn. This normalized image is then fed into the fixed deep segmentation network Sθ∗ to generate a predicted segmentation Zc. This predicted segmentation is subsequently passed through a denoising autoencoder (DAE), Dψ∗, which acts as a prior to assess the plausibility of the prediction. The DAE outputs a denoised, more plausible segmentation Z. The parameters of the normalization module Nϕ are adapted for each test image by minimizing the dissimilarity between the predicted segmentation Zc and its denoised version Z.
The key design choice is to adapt only the parameters of the image normalization module, Nϕ, while keeping the deep segmentation network, Sθ, fixed at its pre-trained values. This is based on the assumption that domain shifts, such as changes in scanner or protocol, primarily affect low-level image statistics and contrast, which can be corrected by a relatively shallow normalization network. The normalization module Nϕ is modeled as a residual CNN with a small number of layers and kernels, ensuring it can only perform intensity transformations without altering the underlying anatomical structure. This design allows the method to leverage the full capacity of the pre-trained segmentation network while enabling per-image adaptation.
To drive this adaptation without label information, the method employs a pre-trained denoising autoencoder (DAE), Dψ∗, as an implicit prior on plausible anatomical segmentations. The DAE is trained on the source domain dataset to map corrupted segmentations to clean ones. During test-time adaptation, the segmentation predicted by the segCNN is treated as a "noisy" input to the DAE. The parameters of the normalization module Nϕ are updated iteratively to minimize the loss between the predicted segmentation and the DAE's output, effectively pulling the prediction towards a more plausible anatomical configuration. This process is formalized in Equation 2, where the adaptation seeks to minimize the dissimilarity between the DAE input and output.
For cases involving large domain shifts, such as differences in imaging modality or protocol, the method incorporates an atlas-based initialization. A threshold-based switching mechanism is used to decide between using the DAE output or an affinely registered atlas as the target for adaptation. This ensures the adaptation starts from a reasonable point and then leverages the more flexible DAE for fine-tuning. The method is also designed to be compatible with 2D segmentation networks by processing 3D images in slices and integrating the 3D DAE's output to guide the adaptation process.
Experiment
The evaluation assesses segmentation accuracy across multiple anatomies and domain shifts by comparing predicted outputs against ground truth references. Experiments validate the proposed test-time adaptation framework against standard baselines, established domain generalization techniques, and unsupervised domain adaptation methods, while ablation studies verify the necessity of freezing core network parameters and restricting optimization to normalization layers. Qualitative analysis confirms that this constrained adaptation effectively bridges the cross-domain performance gap without requiring target labels or extensive computational resources. Ultimately, the approach proves more robust than iterative denoising post-processing and highly competitive with label-dependent adaptation strategies, demonstrating that consistent normalization adjustments provide a reliable, label-free pathway for domain-shifted medical imaging.
The authors conduct experiments to evaluate domain generalization methods for medical image segmentation across different anatomies and datasets. They compare various approaches, including baseline models, data augmentation, post-processing with denoising autoencoders, and test-time adaptation, focusing on how well models generalize to unseen domains without labeled target data. The proposed test-time adaptation method achieves performance comparable to unsupervised domain adaptation methods without requiring labeled source domain data. Data augmentation significantly improves generalization, but post-processing with denoising autoencoders shows mixed results depending on the anatomical domain. Test-time adaptation outperforms simple post-processing with multiple passes through the denoising autoencoder, particularly for complex anatomical structures.
The authors evaluate a test-time adaptation method for medical image segmentation across different anatomies, comparing it against various domain generalization and unsupervised domain adaptation approaches. Results show that the proposed method achieves competitive performance with existing methods, particularly in scenarios where labeled source domain data is not available, and demonstrates effective convergence during adaptation. The proposed test-time adaptation method achieves competitive results with unsupervised domain adaptation methods, especially for scanner change-related domain shifts. The method outperforms baseline approaches and shows consistent convergence across different anatomies and test domains. Test-time adaptation provides better performance than post-processing with denoising autoencoders, particularly for complex anatomies like the brain.

The authors evaluate various domain generalization methods for medical image segmentation across different anatomies, comparing their proposed test-time adaptation approach with baseline, benchmark, and state-of-the-art methods. Results show that the proposed method achieves competitive performance, particularly in scenarios where domain shifts are significant, and demonstrates the importance of constrained adaptation and DAE integration. The analysis highlights the effectiveness of test-time adaptation in improving segmentation accuracy without requiring labeled target domain data. The proposed test-time adaptation method achieves competitive results compared to state-of-the-art domain generalization and unsupervised domain adaptation methods, especially for large domain shifts. Constrained adaptation of only the input normalization module improves segmentation accuracy and stability, as opposed to adapting all parameters or using post-processing alone. The method performs well across different anatomies and domain shifts, with improvements observed in both Dice score and Hausdorff distance metrics compared to baseline and related approaches.
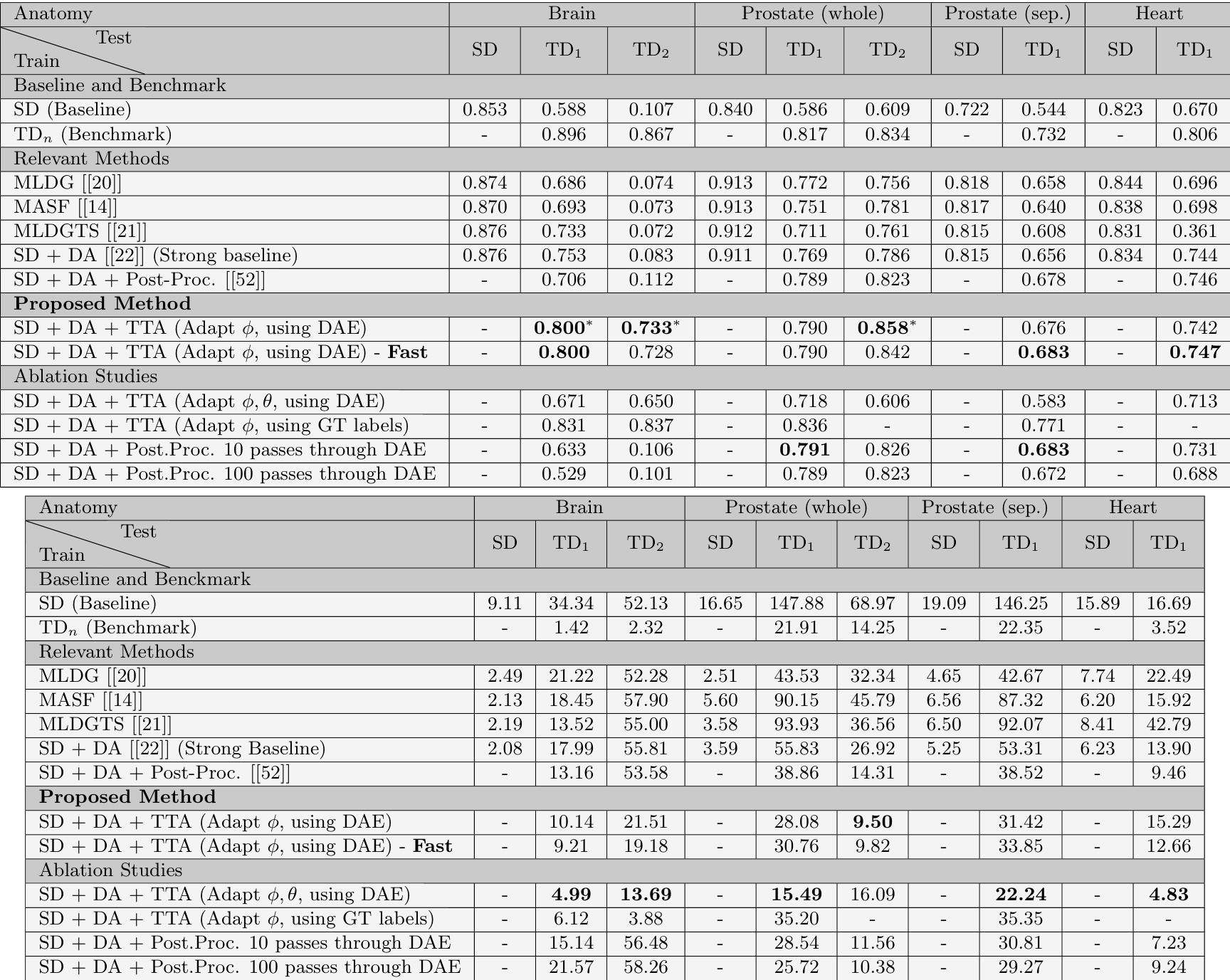
The experiments compare baseline models, data augmentation, post-processing techniques, and the proposed test-time adaptation strategy to validate their effectiveness in generalizing to unseen medical image domains without labeled data. While data augmentation consistently enhances cross-domain performance, post-processing with denoising autoencoders yields inconsistent results depending on the anatomical structure. The proposed test-time adaptation method demonstrates strong qualitative advantages by matching the performance of unsupervised domain adaptation approaches without requiring labeled source data, while consistently outperforming baseline models and simple post-processing techniques. Additionally, restricting adaptation to input normalization modules rather than updating all network parameters significantly enhances segmentation stability and reliable convergence across diverse domain shifts.