Command Palette
Search for a command to run...
Exemplar Normalization for Learning Deep Representation
Exemplar Normalization for Learning Deep Representation
Ruimao Zhang Zhanglin Peng Lingyun Wu Zhen Li Ping Luo
Layer Normalization
Abstract
Normalization techniques are important in different advanced neural networks and different tasks. This work investigates a novel dynamic learning-to-normalize (L2N) problem by proposing Exemplar Normalization (EN), which is able to learn different normalization methods for different convolutional layers and image samples of a deep network. EN significantly improves flexibility of the recently proposed switchable normalization (SN), which solves a static L2N problem by linearly combining several normalizers in each normalization layer (the combination is the same for all samples). Instead of directly employing a multi-layer perceptron (MLP) to learn data-dependant parameters as conditional batch normalization (cBN) did, the internal architecture of EN is carefully designed to stabilize its optimization, leading to many appealing benefits. (1) EN enables different convolutional layers, image samples, categories, benchmarks, and tasks to use different normalization methods, shedding light on analyzing them in a holistic view. (2) EN is effective for various network architectures and tasks. (3) It could replace any normalization layers in a deep network and still produce stable model training. Extensive experiments demonstrate the effectiveness of EN in wide spectrum of tasks including image recognition, noisy label learning, and semantic segmentation.
One-sentence Summary
The authors propose Exemplar Normalization (EN), a dynamic learning-to-normalize method that learns layer- and sample-specific normalization parameters through a carefully designed internal architecture that avoids the instability of MLP-based or static linear combinations, thereby stabilizing optimization and improving performance across image recognition, noisy label learning, and semantic segmentation.
Key Contributions
- This work introduces Exemplar Normalization (EN), a dynamic learning-to-normalize framework that adaptively assigns distinct normalization methods to individual image samples and convolutional layers. By replacing standard multi-layer perceptron parameter learning with a carefully structured internal architecture, EN stabilizes optimization while enabling sample- and layer-specific normalization during both training and inference.
- The proposed method establishes a flexible analytical framework for inspecting how different normalizers function across network depths and correlate with distinct input samples. This capability enables different convolutional layers, image samples, categories, benchmarks, and tasks to utilize distinct normalization methods, facilitating holistic analysis of their relationships.
- Extensive experiments demonstrate that EN serves as a plug-and-play module capable of replacing existing normalization layers across diverse architectures without compromising training stability. Evaluations on ImageNet, WebVision, ADE20K, and Cityscapes show consistent performance gains, with EN delivering up to 300% greater improvement than switchable normalization when integrated into standard ResNet50 models.
Introduction
Normalization techniques are fundamental for stabilizing training and maximizing the performance of convolutional neural networks across computer vision applications. While recent hybrid methods attempt to combine multiple normalizers, they typically rely on a static learning strategy that applies identical normalization ratios to every image, which limits instance-level adaptability and often results in suboptimal accuracy. To overcome this bottleneck, the authors leverage Exemplar Normalization (EN) to introduce a dynamic learning-to-normalize framework that automatically selects the most appropriate normalizer for each individual sample and network layer. By carefully designing a lightweight internal architecture, EN avoids the overfitting pitfalls of earlier conditional approaches while serving as a plug-and-play module that consistently boosts performance across diverse benchmarks and reveals how different image categories process visual information.
Method
The authors propose Exemplar Normalization (EN), a dynamic learning-to-normalize framework that enables data-dependent normalization by learning distinct normalization strategies for individual samples within each convolutional layer. EN extends the capabilities of Switchable Normalization (SN) by introducing sample-specific importance ratios, allowing each image in a mini-batch to adaptively combine multiple normalization methods. The core architecture of EN is structured around a two-branch process: one branch estimates statistics for various normalization methods, while the other computes sample-specific importance ratios to combine these normalized feature maps.
The framework begins with input feature maps X∈RN×C×H×W, where N, C, H, and W represent the batch size, number of channels, and spatial dimensions, respectively. The first stage involves estimating the mean μk and standard deviation δk for each of the K normalization methods (e.g., Batch Normalization, Instance Normalization, Layer Normalization) across the mini-batch. These statistics, collectively denoted as Ω={(μk,δk)}k=1K, are then used to pre-normalize the input. Specifically, the input X is downsampled via average pooling to produce a N×C feature matrix x. Each Ωk is applied to x, resulting in a N×K×C tensor x^, which is subsequently processed through a 1-D convolutional layer to reduce its channel dimension from C to C/r, where r is a reduction rate. This step is implemented using group convolution to maintain a parameter count independent of r, producing an intermediate representation z.
The key innovation in EN lies in the computation of sample-specific importance ratios λnk. The process proceeds in three steps. First, the z tensor is used to compute pairwise correlations between the different normalizers for each sample. For the n-th sample, the matrix zn∈RK×C is multiplied by its transpose znT to form a K×K correlation matrix vn=znznT. This matrix captures the interdependencies between the normalization methods for a given sample, providing a higher-order feature representation that enhances the model's ability to reason about the optimal combination. The correlation matrix vn is then flattened into a vector and fed into a two-layer fully-connected (FC) network. The first FC layer increases the dimensionality to πK (with π=50 in practice), followed by a tanh activation function, and the second FC layer reduces the dimension back to K. The resulting vector λn∈RK×1 represents the importance ratios for the n-th sample. A softmax function is applied to ensure the ratios sum to one, ∑kλnk=1, and the final normalized output is computed as a linear combination of the pre-normalized feature maps, incorporating learnable scale γk and shift βk parameters for each normalization method.
This architecture ensures stability during optimization by avoiding the direct combination of mean and variance statistics, which can introduce bias, and by using a structured, data-driven approach to compute the importance ratios. The design of the ratio calculation module is lightweight, with the additional parameters primarily residing in the convolutional and fully-connected layers, resulting in a marginal increase in computational cost compared to SN.
Experiment
The proposed EN normalization method is evaluated across diverse visual recognition tasks, including large-scale and noisy image classification, fine-grained classification, and semantic segmentation, to validate its accuracy, robustness, and cross-domain generalization. Across all benchmarks, EN consistently outperforms existing normalization and attention-based techniques while maintaining competitive computational costs. Ablation studies and dynamic ratio analysis further reveal that the method’s adaptive weighting mechanism automatically learns instance- and layer-specific normalization preferences that evolve during training, which directly drives its superior performance. Ultimately, EN proves to be a highly effective and versatile normalization strategy that reliably enhances model accuracy across varied vision tasks.
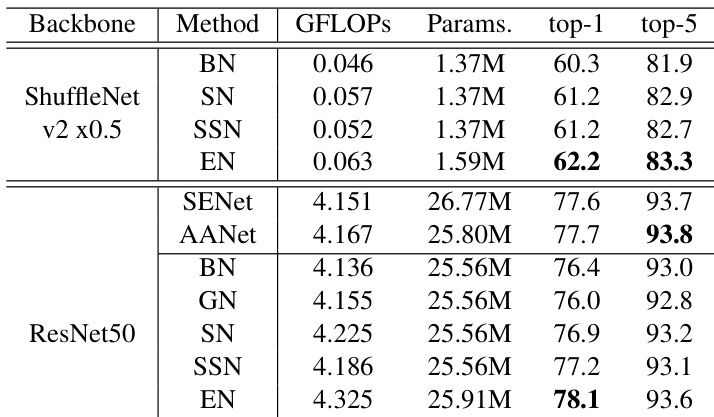
The authors evaluate the proposed EN method on ImageNet using different backbone networks, comparing its performance against various normalization techniques. Results show that EN achieves higher classification accuracy than its counterparts while maintaining competitive computational costs. The method demonstrates consistent improvements across different network architectures and tasks. EN achieves higher top-1 and top-5 accuracy compared to other normalization methods on ImageNet with both ShuffleNet v2 and ResNet50 backbones. EN outperforms SN and other methods in classification accuracy with only a small increase in computational cost. EN shows consistent performance improvements across different backbone networks and tasks, including image classification and semantic segmentation.
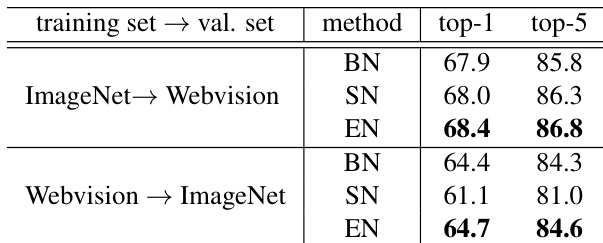
The authors conduct cross-dataset experiments to evaluate the transferability of normalization methods between ImageNet and Webvision datasets. Results show that the proposed EN method consistently outperforms its counterparts in both directions of cross-dataset testing, demonstrating its robustness and generalization capability. The performance improvement of EN is notable in top-1 and top-5 accuracy across different training and validation set combinations. EN achieves higher accuracy than SN and BN in cross-dataset tests between ImageNet and Webvision. EN maintains superior performance when transferring models from ImageNet to Webvision and vice versa. The results demonstrate EN's strong generalization ability across different datasets with the same categories.
{"summary": "The authors evaluate the performance of EN across various datasets and tasks, including image classification, noisy classification, and semantic segmentation. Results show that EN consistently outperforms SN and other normalization methods in terms of accuracy while maintaining competitive computational costs. The effectiveness of EN is further validated through ablation studies, which demonstrate that its design choices contribute to improved performance.", "highlights": ["EN achieves higher accuracy than SN across multiple datasets and network architectures.", "The performance of EN improves with increasing values of the hyper-parameter π, though the model remains robust to changes in this parameter.", "EN demonstrates consistent gains in accuracy across different tasks, including classification and semantic segmentation, compared to existing normalization methods."]

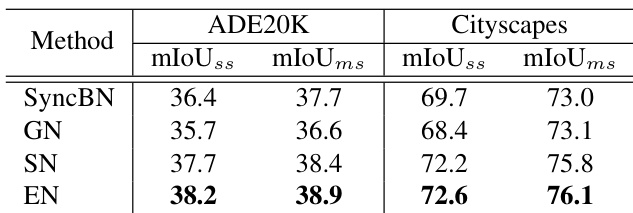
The authors evaluate the performance of EN on semantic segmentation tasks using ADE20K and Cityscapes datasets, comparing it with SyncBN, GN, and SN. Results show that EN achieves higher mIoU scores than the other methods on both datasets under single-scale and multi-scale testing conditions. The performance improvement of EN is consistent with its classification results, demonstrating its generalization ability. EN outperforms SyncBN, GN, and SN on both ADE20K and Cityscapes datasets in semantic segmentation. EN achieves higher mIoU scores under both single-scale and multi-scale testing conditions. The performance improvement of EN is consistent with its results in image classification tasks.
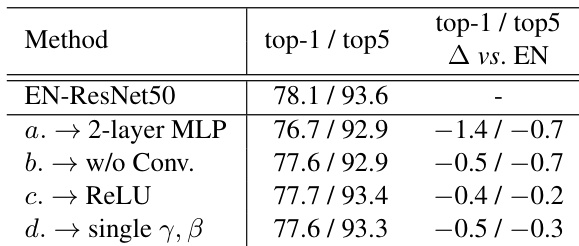
The authors conduct an ablation study to evaluate the impact of different components in the proposed EN layer on classification performance. Results show that removing the convolution operation or replacing the activation function affects performance, while using a single set of parameters for normalization leads to a slight drop. The current configuration of EN achieves the best results compared to all variants. Removing the convolution operation in the EN layer leads to a significant drop in performance. Replacing the Tanh activation with ReLU improves performance slightly. Using a single set of parameters for normalization results in a small decrease in accuracy compared to the full EN configuration.
The proposed EN normalization method is evaluated across image classification, cross-dataset transfer, and semantic segmentation tasks to assess its accuracy, computational efficiency, and generalization capabilities. Classification and cross-dataset experiments validate that EN consistently surpasses existing normalization techniques while maintaining competitive computational overhead, demonstrating robust performance across diverse architectures and data distributions. Additional ablation studies confirm the necessity of its specific architectural components, showing that the complete configuration optimally balances representational capacity and model stability. Collectively, these evaluations establish EN as a highly effective normalization strategy that reliably generalizes across various visual recognition benchmarks.