Command Palette
Search for a command to run...
A Morpho-Syntactically Informed LSTM-CRF Model for Named Entity Recognition
A Morpho-Syntactically Informed LSTM-CRF Model for Named Entity Recognition
Lilia Simeonova Kiril Simov Petya Osenova Preslav Nakov
Named Entity Recognition (NER) Prediction Using astroBERT
Abstract
We propose a morphologically informed model for named entity recognition, which is based on LSTM-CRF architecture and combines word embeddings, Bi-LSTM character embeddings, part-of-speech (POS) tags, and morphological information. While previous work has focused on learning from raw word input, using word and character embeddings only, we show that for morphologically rich languages, such as Bulgarian, access to POS information contributes more to the performance gains than the detailed morphological information. Thus, we show that named entity recognition needs only coarse-grained POS tags, but at the same time it can benefit from simultaneously using some POS information of different granularity. Our evaluation results over a standard dataset show sizeable improvements over the state-of-the-art for Bulgarian NER.
One-sentence Summary
The authors propose a morpho-syntactically informed LSTM-CRF model for named entity recognition that integrates word embeddings, character features, and multi-granularity part-of-speech tags, demonstrating that coarse-grained syntactic cues outperform detailed morphological features for morphologically rich languages and delivering state-of-the-art performance gains on Bulgarian NER benchmarks.
Key Contributions
- This work proposes a morphologically informed LSTM-CRF architecture for named entity recognition that integrates word embeddings, Bi-LSTM character embeddings, part-of-speech tags, and morphological features to address information gaps in complex word forms.
- Systematic analysis reveals that part-of-speech annotations provide greater performance gains than detailed morphological information, demonstrating that coarse-grained tags combined with varying granularity levels effectively enhance entity recognition.
- Evaluations on a standard Bulgarian dataset demonstrate sizeable improvements over existing state-of-the-art models, while the released datasets and source code enable direct comparison in future research.
Introduction
Named entity recognition serves as a critical preprocessing step for a wide range of natural language processing applications, including question answering, information extraction, and conversational AI. Despite decades of research, the task remains challenging due to the sheer volume of unstructured data and the linguistic complexity of proper names. Early systems relied on error-prone hand-crafted rules and statistical models, while recent deep learning approaches such as Bi-LSTM-CRF architectures have shown strong results for English. However, these modern models struggle with morphologically rich languages because standard word embeddings fail to capture the grammatical context required to parse numerous inflected word forms. The authors address this gap by leveraging part-of-speech tags and morphological annotations as direct inputs to an LSTM-CRF network. This morpho-syntactically informed design delivers substantial performance gains over existing baselines for Bulgarian NER and includes a full release of their dataset and code to standardize future evaluations.
Dataset
- Dataset Composition and Sources: The authors use a Bulgarian corpus sourced from the manually annotated BulTreeBank. It combines BIO-formatted named entity annotations with positional morphosyntactic tags.
- Subset Details: The data is split into three disjoint sets: training, development, and test. While exact token counts are not provided in the text, the authors note a significant class imbalance with a heavy concentration of Person entities. No explicit filtering rules are applied during preparation.
- Data Usage and Processing: The dataset trains a named entity recognition model. To prevent overfitting caused by the skewed class distribution, the authors implement early stopping. The workflow does not involve data mixture ratios or cropping strategies.
- Metadata and Annotation Processing: Named entities are encoded using nine BIO labels (B-PER, I-PER, B-ORG, I-ORG, B-LOC, I-LOC, B-MISC, I-MISC, O) derived from syntactic constituency boundaries. Each token inherits positional morphosyntactic tags from the BulTreeBank tagset, which capture parts of speech and grammatical features to help analyze how morphology influences NER performance.
Method
The authors leverage a modified Bi-LSTM-CRF architecture, building upon the foundational model introduced by Lample et al. (2016), to address named entity recognition in morphologically rich languages such as Bulgarian. The core framework processes each word in a sentence by first constructing a comprehensive input vector that integrates multiple sources of information. This input vector is formed by concatenating a word embedding, a character-level embedding, and a grammatical vector that encodes morphosyntactic features. The word embedding is derived from pre-trained FastText vectors, which capture semantic information and are effective at handling out-of-vocabulary words through character n-gram modeling. The character-level embedding is generated using a bidirectional LSTM over the characters of each word, capturing prefix and suffix information that is crucial for modeling morphological variations.
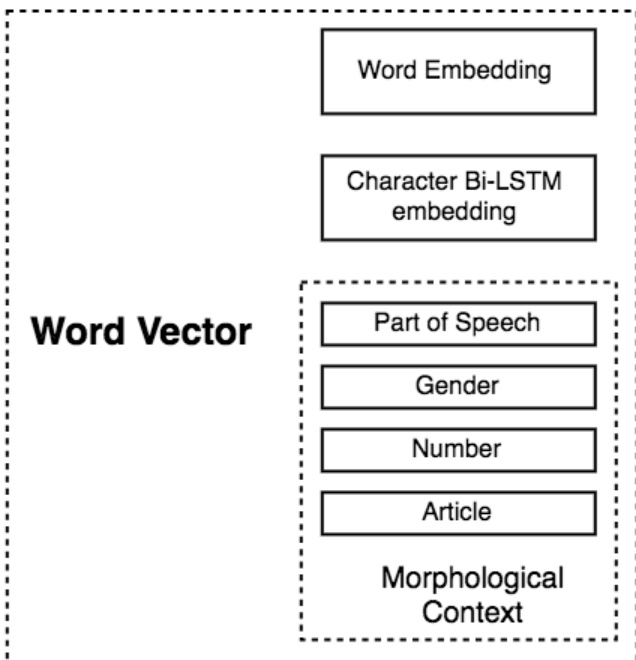
As shown in the figure below, the grammatical vector is composed of several components, including part-of-speech (POS) tags and morphological features such as gender, number, and definiteness, which are represented as one-hot vectors. The POS tag is used to classify words into categories such as noun, adjective, verb, and others, and is treated as a coarse-grained feature. The morphological features are specifically relevant for nouns, adjectives, pronouns, and hybrid tags, with gender having three values, number having four, and definiteness having four values, including specific forms for singular masculine nouns. These features are concatenated to form a comprehensive word vector that enriches the input representation.
The constructed word vectors are then fed into a bidirectional LSTM layer, which captures contextual information from both the left and right contexts of each word. The outputs of the forward and backward LSTMs are concatenated to form a contextualized word representation. This representation is passed through a fully connected layer to generate scores for each possible named entity tag. Finally, a CRF decoder is applied to determine the optimal sequence of tags, ensuring global consistency in the labeling. To mitigate overfitting, a dropout layer is applied to the word vectors during training, randomly excluding hidden units with a specified probability. This approach combines automatically learned features from word and character embeddings with hand-crafted grammatical features to enhance performance on morphologically complex languages.
Experiment
The study evaluates a Bi-LSTM-CRF architecture for Bulgarian part-of-speech tagging and named entity recognition, utilizing contextual embeddings and a linear-chain CRF decoder to validate the impact of augmented morphological and POS features. A subsequent error analysis experiment validates the model's performance on loanwords and foreign names, revealing that POS tags significantly improve parsing accuracy where the base network struggles with atypical linguistic structures. Although supplementary gazetteers and script detection features yielded minimal gains, the findings confirm that contextual tagging effectively mitigates entity ambiguities and demonstrates the model's robustness against complex lexical challenges in Bulgarian.
The authors present a series of experiments comparing different model configurations for Bulgarian POS tagging, with results showing that adding various features such as character-level information, POS tags, and morphological features progressively improves performance. The best model combines multiple feature types, achieving the highest F1 score. Adding character-level information to the model improves performance over using only word-level features. Incorporating POS tags and morphological features leads to further improvements in model performance. The best-performing model combines multiple feature types, resulting in the highest F1 score compared to other configurations.

The authors present a dataset split for a Bulgarian NER task, with training, development, and test sets detailed by sentence and token counts across entity types. The data distribution shows a significant imbalance, with the training set containing the majority of tokens and sentences, while the test set is smaller and more balanced across entity categories. The training set is substantially larger than the development and test sets in both sentences and tokens. The number of tokens varies significantly across entity types, with some types having many more tokens than others. The test set has a more balanced distribution of tokens across entity types compared to the training set.
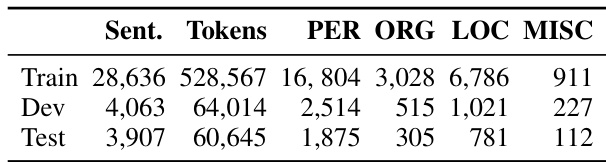
The authors evaluate their model's performance on named entity recognition tasks, presenting precision, recall, and F1 scores for different entity types. The results indicate strong performance for Location and Person entities, while the model struggles more with Organization and Miscellaneous categories, particularly in recall and F1 metrics. The model achieves high precision and recall for Location and Person entities. Performance is notably lower for Organization and Miscellaneous entities, especially in recall and F1 scores. The Overall metrics reflect a trade-off, with strong scores for some entities but significant weaknesses in others.
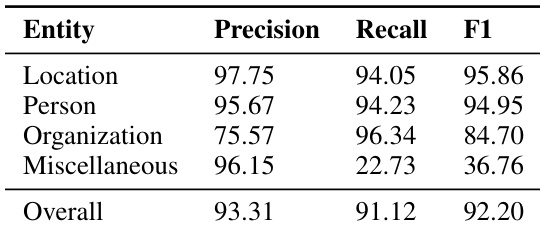
The authors present a confusion matrix from their best model's performance on the test dataset, showing the distribution of predicted tags versus true labels for named entity recognition. The results indicate significant misclassification between certain tags, particularly for B-PER and B-LOC, which are often confused with the O tag, and between B-LOC and B-ORG, suggesting challenges in distinguishing entities with overlapping names. The model frequently misclassifies B-PER and B-LOC tags as O, indicating difficulty with first names and location names. There is notable confusion between B-LOC and B-ORG tags, likely due to overlapping names of places and organizations. The O tag has high values on the diagonal, reflecting the model's strong performance on non-entity words.
The authors compare their model against a baseline model from prior work, showing improved performance. Results indicate that the proposed model achieves higher F1 scores compared to the previous state-of-the-art approach. The proposed model outperforms the baseline model in terms of F1 score. The improvement suggests that the authors' method provides better results than previous approaches. The model achieves higher performance on the evaluated task compared to the prior work.

The evaluation assesses Bulgarian part-of-speech tagging and named entity recognition through feature ablation studies, dataset distribution analysis, and comparative benchmarking against prior state-of-the-art methods. Experiments validate that progressively incorporating character-level details, syntactic tags, and morphological attributes substantially improves tagging accuracy, with the multi-feature configuration proving most effective. For named entity recognition, the model demonstrates robust handling of location and person entities while struggling with organization and miscellaneous categories, primarily due to overlapping naming conventions and frequent misclassification against non-entity labels. Overall, the proposed architecture consistently surpasses previous baselines, confirming that comprehensive feature integration and task-specific design yield superior linguistic parsing capabilities.