Command Palette
Search for a command to run...
How to Use DataFrames
Abstract
One-sentence Summary
The authors propose replacing classic event log structures with mainstream columnar dataframes to enhance process mining scalability, detailing the necessary algorithmic adaptations and computational complexity analyses required to efficiently process real-life event data on mainstream workstations.
Key Contributions
- The paper introduces a formal abstraction and implementation of dataframe structures to replace traditional in-memory event log representations, enabling direct ingestion from columnar storage formats such as Apache Parquet and Apache ORC to overcome scalability bottlenecks on standard workstations.
- Adapted process mining algorithms for filtering and Directly-Follows Graph computation are presented alongside formal complexity estimations that demonstrate how the dataframe architecture optimizes memory access and accelerates log exploration.
- Empirical evaluations on real-life and simulated event logs demonstrate that the proposed dataframe-based approach processes large-scale data with efficient execution times and reasonable memory occupation, validating its applicability to mainstream process mining workloads.
Introduction
Process mining enables organizations to extract actionable insights from event data generated by information systems, supporting critical analyses like bottleneck detection and process discovery. However, the exponential growth of event logs has exposed a major bottleneck in existing frameworks, which typically prioritize analytical accuracy over execution speed and memory efficiency, making large-scale analysis impractical on standard workstations. To address this, the authors leverage columnar storage formats and dataframe structures to replace traditional event log representations. They formalize a dataframe abstraction tailored for process mining, adapt core algorithms to this new structure, and demonstrate through complexity analysis and empirical testing that this approach dramatically improves computational performance and memory management without sacrificing analytical capability.
Dataset

-
Dataset Composition and Sources: The dataset consists of event logs formatted according to the IEEE XES standard. These logs serve as the foundational input for process mining and are sourced from widely adopted frameworks and commercial tools including ProM6, PM4Py, Disco, ProcessGold, Celonis, and QPR.
-
Subset Details and Structure: Rather than fixed training partitions, the data is organized around two processing configurations based on analytical requirements. Partial loading extracts only the case identifier and activity name, which is sufficient for most discovery and conformance algorithms. Complete loading retains every available attribute to support detailed log exploration and behavioral filtering. The dataset inherently contains partial attributes, meaning not every event carries values for all registered fields.
-
Data Usage and Processing: The authors treat these logs as the starting point for formal process mining analysis. They define a classical event log structure that maps case identifiers to event sets, events to activities, and events to partial attribute functions. This structured data is then transformed into a Directly Follows Graph, where nodes represent activities and weighted edges capture the frequency of direct activity succession. The workflow also references integration with big data architectures like Apache Hadoop and Spark to handle large scale event collections.
-
Additional Processing Strategies: The pipeline emphasizes selective attribute loading to optimize memory usage and computation. After constructing the graph, the authors convert the Directly Follows Graph into a Petri net to enable advanced conformance checking. The data handling approach also supports relational database implementations and distributed MapReduce architectures, ensuring the pipeline remains scalable across diverse process mining workloads.
Method
The authors leverage a dataframe-based approach to enhance the scalability of process mining operations, building upon columnar storage formats such as Apache Parquet and Apache ORC. This framework is designed to efficiently handle large-scale event logs by exploiting the advantages of columnar storage and the structured operations available in dataframe implementations. The core of the methodology lies in the abstraction and implementation of a dataframe structure, which allows for optimized data access and manipulation compared to traditional row-based or XES-based event log representations.
The dataframe model is formally defined as a tuple D=(I,N,T,V,χival,χtype), where I represents a set of event indices, N is the set of attribute names, T is the set of attribute types, and V is the set of possible values. The function χival maps each event index and attribute name to a corresponding value, while χtype assigns a type to each attribute. A critical assumption is the presence of case and activity attributes, ensuring that each event is uniquely identifiable and contains a defined activity. This abstraction enables a flexible and efficient representation of event logs that supports a wide range of process mining operations.

Refer to the framework diagram for an illustration of the dataframe structure, where columns correspond to attribute names and rows represent events. The dataframe abstraction is implemented as a simple data structure: a Map<String, ArrayList<Object>>, where each key is an attribute name and the associated value is a list of attribute values for all events. This structure allows for efficient retrieval of all values for a given attribute in O(1) time, enabling faster operations compared to traditional event log representations that rely on hash maps for attribute access. Conversion from an event log L=(CI,E,A,case_ev,act,attr,≤) to a dataframe D involves mapping the event sequence to indices and populating the dataframe with attribute values, with missing values represented as ϵ. The conversion assumes a total order on events, ensuring a consistent mapping between event positions and dataframe indices.
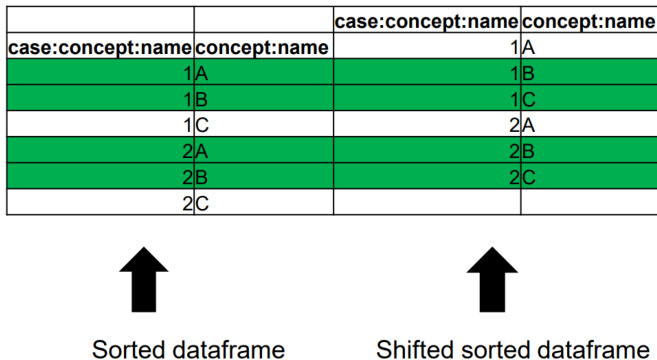
To support process mining tasks, the authors define a suite of transformation functions that operate on dataframes. These include projection, grouping, shift, concatenation, sorting, and string merging. The projection function filters events based on attribute values and a selective function f, while the grouping function partitions the dataframe by a specified attribute, creating disjoint subsets. The shift function aligns events by decrementing their indices, which is essential for computing directly-follows relationships. Concatenation allows merging two dataframes with distinct attribute sets, ensuring attribute name uniqueness through a delimiter. Sorting reorders events based on a specified attribute, and string merging combines two attributes into a new one using a delimiter. These functions enable the construction of complex workflows on top of dataframes, facilitating operations such as filtering and directly-follows graph computation.
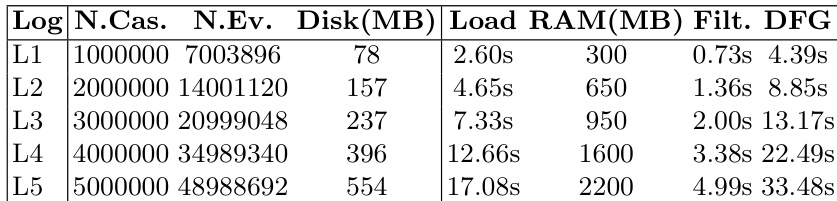
The complexity of operations on dataframes is analyzed in comparison to classical event log implementations. Filtering, a common operation in process mining, has a worst-case complexity of O(N) for dataframes, where N is the number of events, due to constant-time access to attribute values. In contrast, classical event logs exhibit higher complexity in the worst case due to hash map access. The calculation of the directly-follows graph (DFG) on dataframes can be performed using two methods: map-reduce and shifting and counting. The map-reduce approach maintains O(N) average complexity, while the shifting and counting method involves sorting the dataframe by case identifier, which incurs O(NlogN) complexity, followed by linear operations. The worst-case complexity for both methods remains O(N2), arising from collisions in the edge count map. The authors demonstrate that dataframes, when combined with columnar storage, offer significant advantages in handling large-scale event logs, particularly through efficient attribute access and optimized operations.
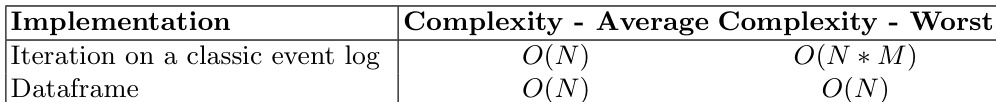
Experiment
The evaluation assesses the performance of Pandas dataframes utilizing Parquet columnar storage for process mining tasks using the PM4Py library across both real-world and synthetic event logs. These experiments validate the system's computational efficiency by measuring loading times, memory consumption, and processing speeds for data filtering and dependency graph generation. The qualitative results indicate that columnar dataframe implementations effectively handle large-scale logs containing millions of events, demonstrating strong suitability for modern process mining workflows. Ultimately, the findings confirm that columnar formats provide significant advantages in managing contemporary event data while maintaining robust performance on standard hardware.
The authors assess the performance of dataframe implementations using columnar storage formats on real-life and synthetic event logs. Results show that dataframes can efficiently handle large-scale event logs, with benefits in disk size, loading time, memory usage, and processing speed for common operations. Dataframes efficiently handle real-life event logs up to 2.5 million events with benefits in disk size and memory usage. Columnar storage formats improve loading speed and reduce memory requirements for large event logs. Operations such as filtering and DFG calculation are faster when using dataframes with columnar formats.

The authors assess the performance of dataframe implementations using columnar storage formats on real-life event logs, focusing on disk size, loading time, memory usage, filtering efficiency, and DFG calculation time. Results show that dataframes can effectively manage large-scale event logs, with significant improvements in storage and computational efficiency when using columnar formats and selective attribute loading. The experiments demonstrate consistent performance gains across different log types and sizes, highlighting the benefits of columnar storage for process mining tasks. Dataframes using columnar storage reduce disk size and memory usage compared to traditional formats. Loading and filtering times are significantly faster when only relevant attributes are loaded. DFG calculation times remain manageable even with large event logs, indicating efficient processing.

The authors assess the performance of dataframe implementations using columnar storage formats on real-life event logs, comparing storage size, loading time, memory usage, filtering speed, and DFG calculation time. Results show that columnar formats significantly reduce storage size and improve loading efficiency, particularly when only relevant attributes are loaded, demonstrating the effectiveness of dataframes for handling large-scale event logs. Columnar storage formats reduce storage size and loading time compared to traditional formats. Loading only specific attributes improves efficiency and reduces memory usage. Dataframes can efficiently handle large event logs with millions of events and cases.

{"summary": "The authors assess the performance of dataframe implementations using columnar storage formats on real-life event logs, focusing on metrics such as disk size, loading time, memory usage, filtering efficiency, and DFG calculation time. Results show that dataframes can effectively handle large-scale logs with varying numbers of events, cases, and attributes, demonstrating scalability and efficiency in process mining applications.", "highlights": ["Dataframes efficiently handle real-life event logs with varying numbers of events, cases, and attributes.", "Loading times and memory usage vary significantly across different logs, with some requiring substantially more resources than others.", "The approach demonstrates scalability, as dataframes manage logs with millions of events and complex structures effectively."]
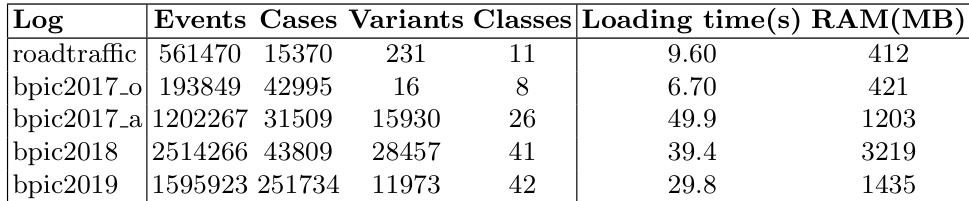
The authors assess the performance of dataframe implementations using columnar storage formats on real-life and synthetic event logs, focusing on computational complexity and resource usage. Results show that dataframes can efficiently handle large-scale event logs, with varying performance depending on the specific operation and data structure. Dataframe operations exhibit different complexity patterns compared to classic event log processing, with some operations showing improved performance when data is pre-sorted by case ID. The complexity of dataframe operations is influenced by the nature of the task, with filtering and shifting operations demonstrating lower complexity than full iteration. The assessment indicates that dataframes can effectively manage large event logs, with performance depending on the specific computational task and data organization.
The evaluation assesses dataframe implementations utilizing columnar storage formats across real-life and synthetic event logs to validate their scalability and computational efficiency for process mining workflows. These experiments examine the performance of essential operations, including data loading, filtering, and dependency graph calculations, under varying data volumes and structural configurations. Qualitative results indicate that columnar storage substantially enhances storage compactness and accelerates query execution, particularly when leveraging selective attribute loading. Overall, the findings demonstrate that dataframes provide a highly scalable and efficient framework for managing large-scale event logs, with performance optimally aligned to specific data organization strategies.