Command Palette
Search for a command to run...
Data Encoding for Byzantine-Resilient Distributed Optimization
Data Encoding for Byzantine-Resilient Distributed Optimization
Deepesh Data Linqi Song Suhas Diggavi
Titanic Data Science Solution
Abstract
We study distributed optimization in the presence of Byzantine adversaries, where both data and computation are distributed among m worker machines, t of which may be corrupt. The compromised nodes may collaboratively and arbitrarily deviate from their pre-specified programs, and a designated (master) node iteratively computes the model/parameter vector for generalized linear models. In this work, we primarily focus on two iterative algorithms: Proximal Gradient Descent (PGD) and Coordinate Descent (CD). Gradient descent (GD) is a special case of these algorithms. PGD is typically used in the data-parallel setting, where data is partitioned across different samples, whereas, CD is used in the model-parallelism setting, where data is partitioned across the parameter space. At the core of our solutions to both these algorithms is a method for Byzantine-resilient matrix-vector (MV) multiplication; and for that, we propose a method based on data encoding and error correction over real numbers to combat adversarial attacks. We can tolerate up to t≤⌊2m−1⌋ corrupt worker nodes, which is information-theoretically optimal. We give deterministic guarantees, and our method does not assume any probability distribution on the data. We develop a sparse encoding scheme which enables computationally efficient data encoding and decoding.
One-sentence Summary
The authors propose a Byzantine-resilient distributed optimization framework for Proximal Gradient Descent and Coordinate Descent that employs data encoding and error correction over real numbers to enable Byzantine-resilient matrix-vector multiplication, achieving information-theoretically optimal tolerance for corrupt nodes with deterministic guarantees without assuming data distributions via a computationally efficient sparse encoding scheme.
Key Contributions
- The paper introduces a Byzantine-resilient matrix-vector multiplication method based on data encoding and error correction over real numbers. This approach tolerates up to half of the worker nodes being corrupt with information-theoretically optimal guarantees without assuming any probability distribution on the data.
- This work presents the first efficient solution for distributed Coordinate Descent under Byzantine attacks by utilizing a specific regular structure for the encoding matrix. The method enables partial coordinate updates in each iteration, distinguishing it from general-purpose codes used in gradient descent.
- A sparse encoding scheme is developed to enable computationally efficient data encoding and decoding while preserving the sparsity of the underlying matrix. This design ensures that Byzantine resiliency is achieved without compromising the computational efficiency typically gained from sparse matrix operations.
Introduction
Distributed learning frameworks often operate across partially trusted worker nodes that may act as Byzantine adversaries. Prior solutions typically rely on statistical assumptions about data or employ robust aggregation techniques that incur significant computational overhead and approximation errors. Most existing research also focuses on Gradient Descent, leaving the model-parallel Coordinate Descent algorithm largely unsecured against such attacks. The authors leverage a sparse data encoding scheme rooted in error correction over real numbers to achieve Byzantine-resilient matrix-vector multiplication. This approach offers deterministic guarantees without requiring probabilistic data assumptions while tolerating up to half of the worker nodes being corrupt. Notably, the team is the first to connect matrix-vector multiplication with Coordinate Descent to design an efficient, adversarial-secure optimization method.
Method
The authors propose Byzantine-resilient distributed optimization algorithms for Proximal Gradient Descent (PGD) and Coordinate Descent (CD) based on data encoding and real-error correction. The core methodology involves encoding the data matrix and parameter vectors to tolerate a constant fraction of malicious worker nodes without relying on statistical assumptions about the data or attack patterns.
For gradient computation in PGD, the process is structured as a two-round matrix-vector multiplication scheme. Refer to the framework diagram for the 2-round approach to the Byzantine-resilient distributed gradient descent.
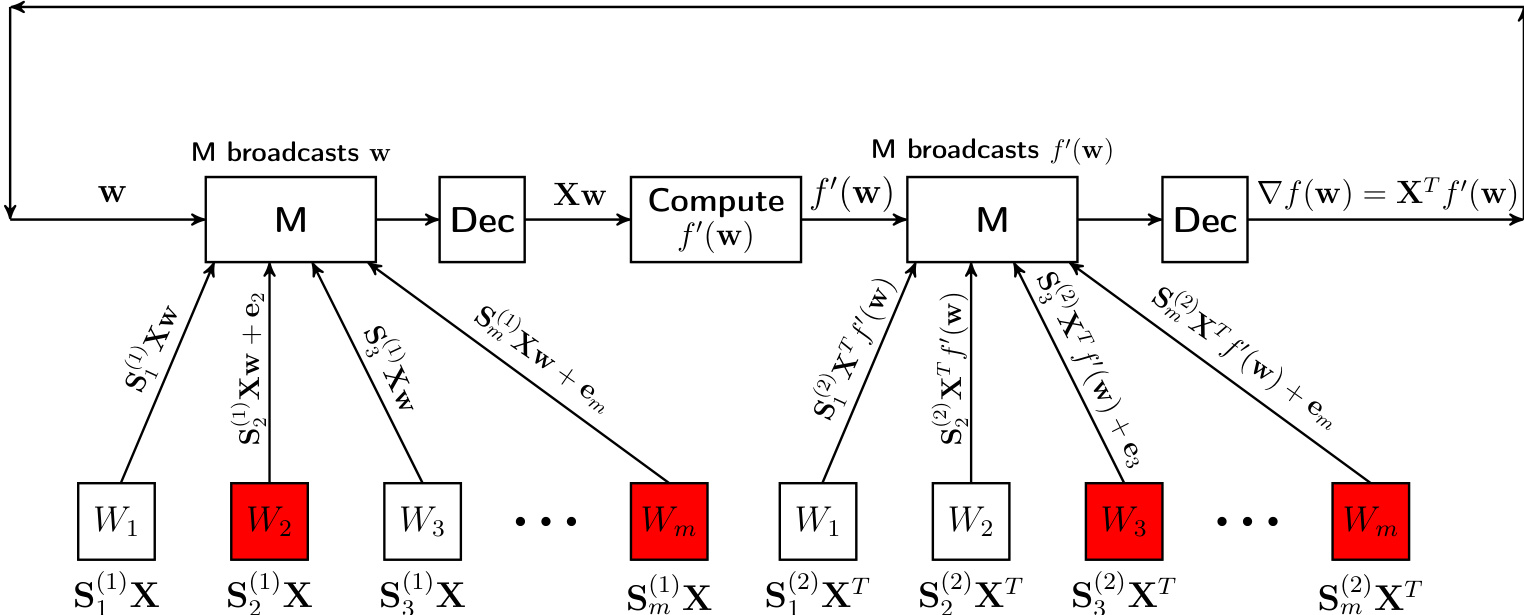 The gradient ∇f(w)=XTf′(w) is computed in two stages. In the first round, the master broadcasts the parameter vector w to the workers. Each worker i holds an encoded version of the data matrix, Si(1)X, and computes the product Si(1)Xw. The master collects these responses, applies an error-correction decoding procedure to recover the true vector Xw, and locally computes f′(w). In the second round, the master broadcasts f′(w). Workers use a second encoding matrix S(2) applied to XT to compute Si(2)XTf′(w). The master decodes these results to obtain the final gradient ∇f(w). The encoding matrices are designed to be sparse with a regular structure, which facilitates efficient decoding using sparse reconstruction techniques over real numbers.
The gradient ∇f(w)=XTf′(w) is computed in two stages. In the first round, the master broadcasts the parameter vector w to the workers. Each worker i holds an encoded version of the data matrix, Si(1)X, and computes the product Si(1)Xw. The master collects these responses, applies an error-correction decoding procedure to recover the true vector Xw, and locally computes f′(w). In the second round, the master broadcasts f′(w). Workers use a second encoding matrix S(2) applied to XT to compute Si(2)XTf′(w). The master decodes these results to obtain the final gradient ∇f(w). The encoding matrices are designed to be sparse with a regular structure, which facilitates efficient decoding using sparse reconstruction techniques over real numbers.
For Coordinate Descent, the approach is adapted to handle updates on subsets of coordinates while maintaining Byzantine resilience. As illustrated in the figure below, the method extends the encoding strategy to handle parameter updates on subsets of coordinates.
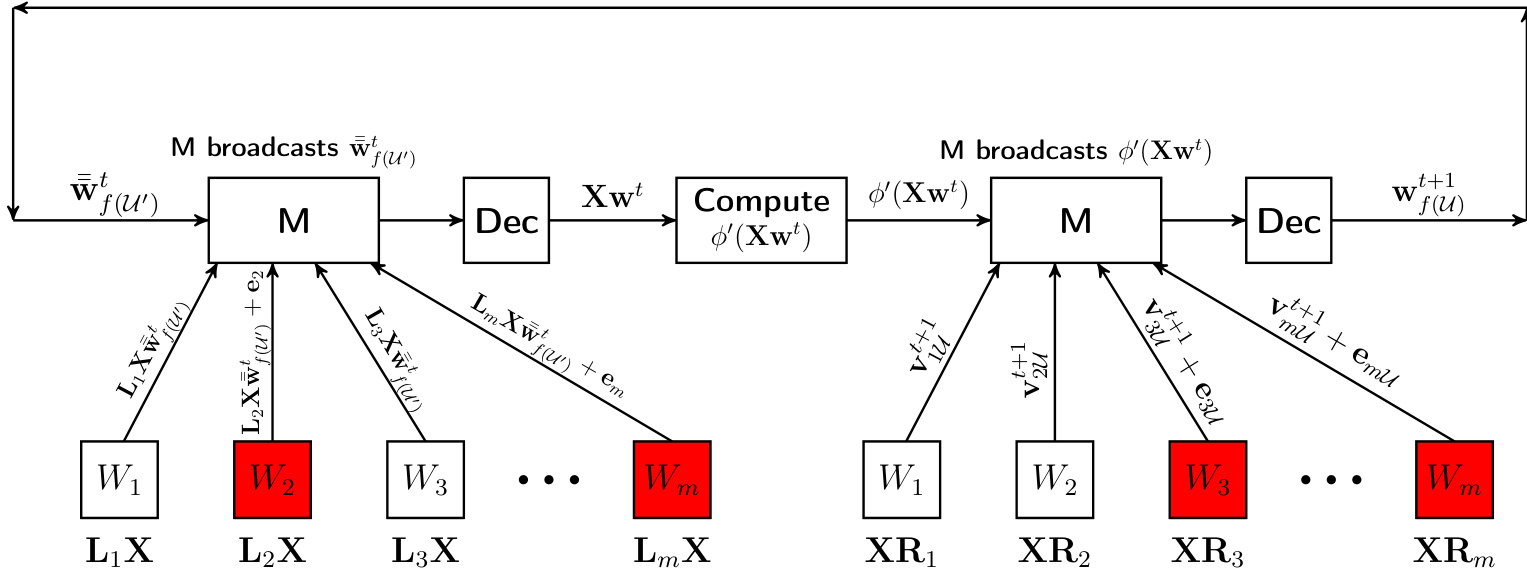 The authors enlarge the parameter space by encoding the original parameter vector w into a higher-dimensional vector v using an encoding matrix R, such that v=R+w. Workers store encoded data XRi and update specific coordinates of their local vi. To facilitate these updates, the master must compute Xw (or its updates) robustly. This is achieved using another encoding matrix L on the data matrix X. In each iteration, the master broadcasts the relevant updates to w, workers compute local matrix-vector products involving LiX, and the master decodes the results to update the global state. This design ensures that updating a small subset of coordinates in v corresponds to updating a specific subset of coordinates in w, allowing the algorithm to proceed correctly even if some workers provide erroneous updates.
The authors enlarge the parameter space by encoding the original parameter vector w into a higher-dimensional vector v using an encoding matrix R, such that v=R+w. Workers store encoded data XRi and update specific coordinates of their local vi. To facilitate these updates, the master must compute Xw (or its updates) robustly. This is achieved using another encoding matrix L on the data matrix X. In each iteration, the master broadcasts the relevant updates to w, workers compute local matrix-vector products involving LiX, and the master decodes the results to update the global state. This design ensures that updating a small subset of coordinates in v corresponds to updating a specific subset of coordinates in w, allowing the algorithm to proceed correctly even if some workers provide erroneous updates.
The decoding mechanism relies on an error locator matrix F, typically a Vandermonde matrix, to identify the set of corrupt workers. By constructing the encoding matrices such that their null space relates to F, the master can isolate the error support through random linear combinations of received vectors. Once the corrupt nodes are identified, their contributions are discarded, and the remaining honest responses are used to recover the exact matrix-vector products via least-squares or similar recovery methods. This allows the system to tolerate up to t<m/2 corrupt nodes with constant overhead in storage and computation compared to the non-resilient baseline.
Experiment
The evaluation compares the proposed coding scheme against DRACO and Lagrange coded computing to validate resource efficiency, followed by numerical experiments on distributed gradient descent and coordinate descent to test performance under Byzantine adversaries. Results indicate the proposed method achieves lower storage and computation redundancy at worker nodes than DRACO while offering superior communication efficiency compared to Lagrange coded computing. Numerical experiments further confirm the approach effectively handles corrupt workers with significant time savings for partial coordinate descent updates and negligible master node overhead.
The experiment evaluates the computational time for Coordinate Descent (CD) with varying fractions of updated coordinates and full Gradient Descent (GD) in the presence of Byzantine adversaries. Results demonstrate that updating fewer coordinates significantly reduces execution time for both worker and master nodes compared to full gradient updates. Additionally, the time required for both computation and decoding increases as the number of corrupt worker nodes rises. Partial coordinate updates (CD) consistently require less time than full gradient descent (GD) for both workers and the master node. Worker computation time for CD with a small fraction of coordinates is drastically lower than that for full GD. Increasing the number of corrupt workers leads to a steady increase in processing time across all algorithm configurations.
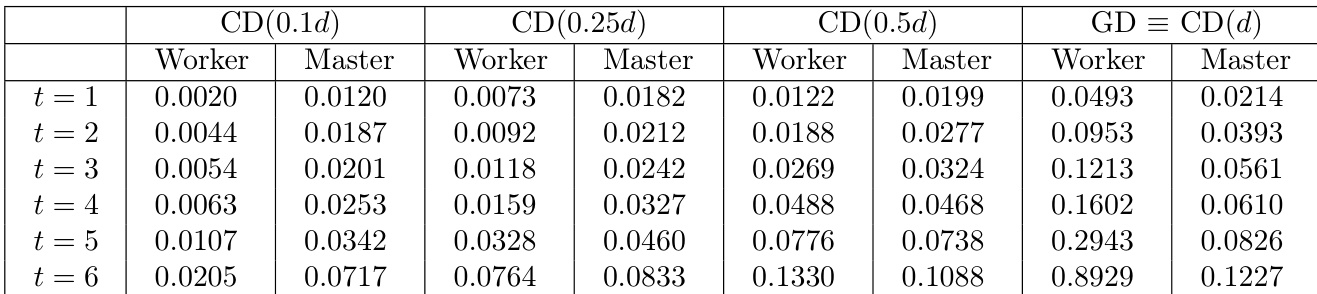
The experiment evaluates the computational time of Coordinate Descent with varying coordinate update fractions against full Gradient Descent in the presence of Byzantine adversaries. Findings show that partial coordinate updates consistently reduce execution time for both worker and master nodes compared to full gradient descent, especially when updating a small fraction of coordinates. Furthermore, processing times for computation and decoding increase steadily as the number of corrupt worker nodes rises across all configurations.