Command Palette
Search for a command to run...
Multi-Layer Perceptron
Abstract
One-sentence Summary
This paper proposes a quantum multilayer perceptron model that employs quantum state preparation for layer outputs and a quantum weight learning algorithm to achieve at least quadratic or exponential speedup over classical algorithms, thereby providing an efficient framework for quantum machine learning and inspiring a Hebbian-based exponential learning method for Hopfield networks.
Key Contributions
- A quantum multilayer perceptron model encodes input and weight vectors as quantum states via qubit amplitudes, requiring only O(logn) qubits while supporting arbitrary real-valued signals.
- A parallel swap test technique integrates the nonlinear architecture of multilayer perceptrons into quantum circuits, enabling efficient implementations of online and batch weight learning algorithms.
- The framework achieves at least quadratic or exponential speedup over classical methods for network inference and parameter updates, and extends to provide exponential acceleration for Hebbian learning in Hopfield networks.
Introduction
Multilayer perceptrons serve as foundational feed-forward neural networks for critical applications like image recognition and machine translation, making their quantum adaptation a highly valuable frontier in quantum machine learning. However, integrating these nonlinear architectures with quantum computing has proven difficult because prior models either violate quantum unitarity during weight updates or require linear qubit scaling that restricts inputs to binary values. To overcome these bottlenecks, the authors leverage an amplitude encoding scheme that represents input and weight vectors as quantum states using only logarithmic qubit resources. They introduce a parallel swap test technique to efficiently compute dot products and apply nonlinear activations, enabling quantum implementations of both forward propagation and weight training algorithms. This framework delivers at least quadratic or exponential speedups over classical methods and extends naturally to accelerate Hebbian learning in Hopfield networks.
Dataset

- Dataset composition and sources: The authors construct a quantum dataset comprising input vectors, target outputs, and neural network weight parameters encoded as normalized quantum states. These states are generated algorithmically via unitary operators rather than drawn from external repositories.
- Key details for each subset: The data is organized in batches of size d, loaded into a uniform superposition state d1∑t=0d−1∣t⟩. Each state is prepared within O(Tin) time complexity. The framework does not apply traditional filtering or cropping rules, as the states are mathematically normalized and directly mapped to the model's input and parameter dimensions.
- Data usage in the model: The authors leverage these quantum states for batch training of output and hidden layer weights in a quantum multilayer perceptron. They utilize the parallel swap test to estimate inner products between input and weight states, enabling efficient gradient estimation and weight updates without classical data shuffling or fixed training splits.
- Processing and state management: The pipeline relies on parallel state preparation, controlled rotations, and quantum phase estimation to encode inner product values into ancilla registers. After computation, inverse operations are applied to uncompute intermediate states and restore clean registers. All processing is optimized to maintain quantum coherence and achieve estimation precision ϵ within O(Tin/ϵ) runtime.
Method
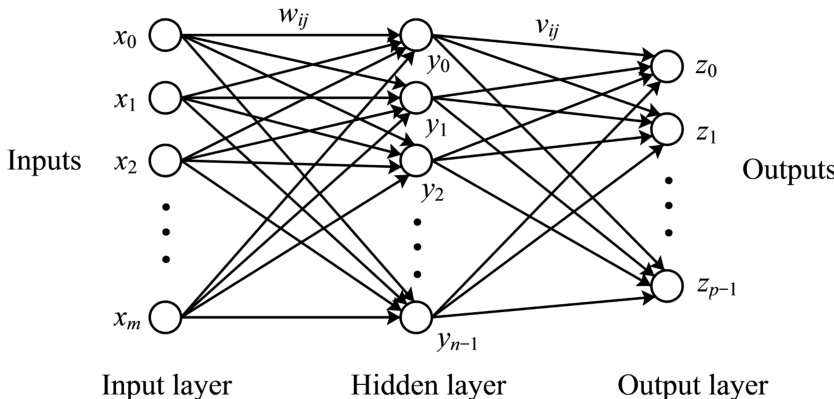
The quantum model for a multilayer perceptron is constructed by extending the principles of quantum state preparation and quantum parallelism to simulate the structure and learning dynamics of classical neural networks. The framework leverages quantum algorithms for efficient computation of inner products and nonlinear functions, enabling the simulation of both the forward pass and learning phase of a multilayer perceptron. The overall architecture consists of three primary components: quantum state preparation for input and weight vectors, quantum simulation of the network's forward propagation to compute outputs, and quantum implementation of the online learning algorithm to update weights.
The process begins with the preparation of quantum states representing the network's parameters and inputs. The input vector x and weight vectors wi are encoded into quantum states ∣x⟩ and ∣wi⟩ using efficient quantum algorithms. These algorithms, based on the linear combinations of unitaries (LCU) technique, allow for the preparation of a quantum state proportional to the given vector in time O(κ(x)logm), where κ(x) is the condition number of the vector. This step is fundamental to accessing the classical data in a quantum form.
The forward pass of the multilayer perceptron is simulated by computing the outputs of each layer. For the hidden layer, the authors employ a parallelized approach to generate the quantum state of the output vector y. This is achieved by first preparing a superposition over the hidden units and then applying a control operation to create a state that contains the normalized input vector ∣x⟩ and each weight vector ∣wi⟩ in parallel. A parallel swap test is then applied to compute the inner product x⋅wi for all i simultaneously. This inner product is used to compute the sigmoid function φ(x⋅wi), which is then encoded into a quantum state using a controlled rotation. The result is a quantum state proportional to the output vector y. This method achieves an exponential speedup over classical methods, with a complexity of O((logmn)/ϵ).
The output layer is simulated in a similar fashion. The quantum state of the hidden layer output ∣Y⟩ is used as input. The process involves preparing a superposition over the output units and applying a control operation to combine ∣Y⟩ with each output layer weight vector ∣vi⟩. A parallel swap test is used to compute the inner product y⋅vi, which is then used to compute the sigmoid function and encode the result into a quantum state. This yields the quantum state of the final output vector z, with a complexity of O((logmnp)n/ϵ2).
The learning algorithm is implemented as an online learning process, where the weights are updated based on a single training sample at each iteration. The update rule for the output layer weights vj involves a term proportional to (rjt−zjt)zjt(1−zjt)yt. This is simulated by preparing a quantum state that combines the current weight vector ∣ψjold⟩ with the quantum state of the hidden layer output ∣Yt⟩. A control operation is used to create a state that contains the updated weight vector vjnew in a superposition. A Hadamard transformation is applied to extract the new quantum state ∣vjnew⟩. This process avoids direct measurement, which would increase the complexity, and allows the algorithm to maintain a low computational cost. The complexity of this online learning algorithm is O(N3/2(logmn)n/ϵ2), which provides a quadratic speedup at n and an exponential speedup at m compared to the classical algorithm.