Command Palette
Search for a command to run...
Spatial Transformer Networks
Abstract
One-sentence Summary
ST-GAN is a generative adversarial network that employs Spatial Transformer Networks as generators to compute realistic geometric warp parameters for foreground-background compositing, and by optimizing transformations directly in parameter space through an iterative warping scheme and sequential training strategy, it outperforms naive single-generator baselines while enabling high-resolution applications such as indoor furniture visualization and accessory try-on.
Key Contributions
- This work introduces Spatial Transformer GANs (ST-GANs), a framework that integrates Spatial Transformer Networks with adversarial learning to compute realistic geometric corrections for foreground objects in image compositing. By operating in a low-dimensional warp parameter space, the architecture generates transformations that align inserted objects with background scenes.
- A sequential adversarial training strategy decomposes large spatial transformations into iterative warping steps to stabilize the generator-discriminator minimax game. This multi-stage approach improves the convergence and precision of geometric adjustments compared to naive single-generator training.
- The framework is evaluated on paired synthetic datasets for indoor furniture placement and unpaired real-world data for portrait accessory insertion. Large-scale user studies confirm improved visual realism, while transferable warp parameters enable effective application to high-resolution images.
Introduction
Generative adversarial networks have advanced realistic image synthesis, yet direct pixel-level generation remains constrained by high-dimensional data spaces and finite network capacity. These models frequently struggle with geometric discrepancies, making them unreliable for practical applications like image compositing where source objects must seamlessly blend into new environments. To overcome these limitations, the authors leverage Spatial Transformer Networks within a GAN framework to introduce ST-GANs, a novel architecture that generates realistic outputs by learning iterative geometric warps instead of direct pixel predictions. By employing a sequential adversarial training strategy, the model progressively corrects spatial transformations to align composite images with the natural image manifold, delivering substantially improved realism across both paired and unpaired compositing tasks.
Method
The authors propose a novel Generative Adversarial Network (GAN) architecture, termed Spatial Transformer GANs (ST-GANs), designed to address realistic geometric corrections for image compositing. The framework operates by learning to adjust the geometric parameters of a foreground object so that it appears natural when composited into a given background image. The core of the model leverages Spatial Transformer Networks (STNs) as its generator, enabling differentiable image warping conditioned on both foreground and background inputs. This allows the network to predict geometric corrections that account for the complex interactions between the object and its intended scene, including perspective, position, and orientation.
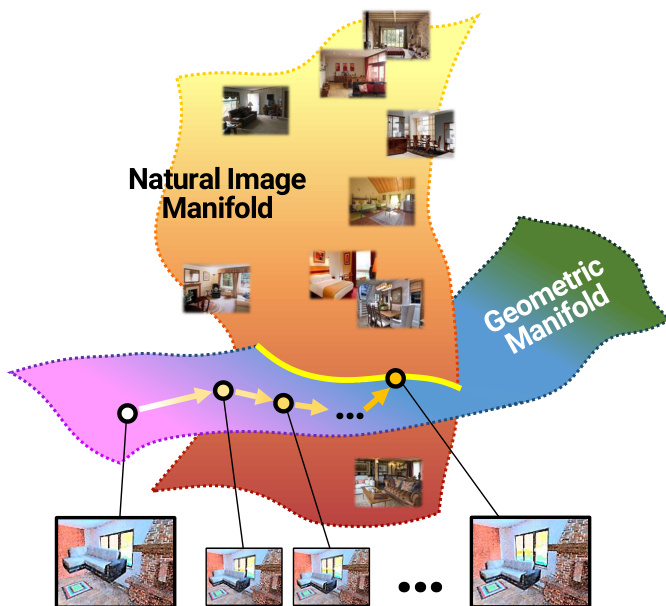
Refer to the framework diagram for an overview of the overall process. The composite image is formed by overlaying the foreground object, masked and warped according to a set of parameters p, onto the background image. The model's objective is to find a sequence of geometric warp updates that transforms the initial composite into one that lies within the natural image manifold. The geometric warp function is restricted to homography transformations, which are parameterized using the sl(3) Lie algebra. This parameterization enables the composition of warp parameters through simple addition, which is a key property for the iterative process.
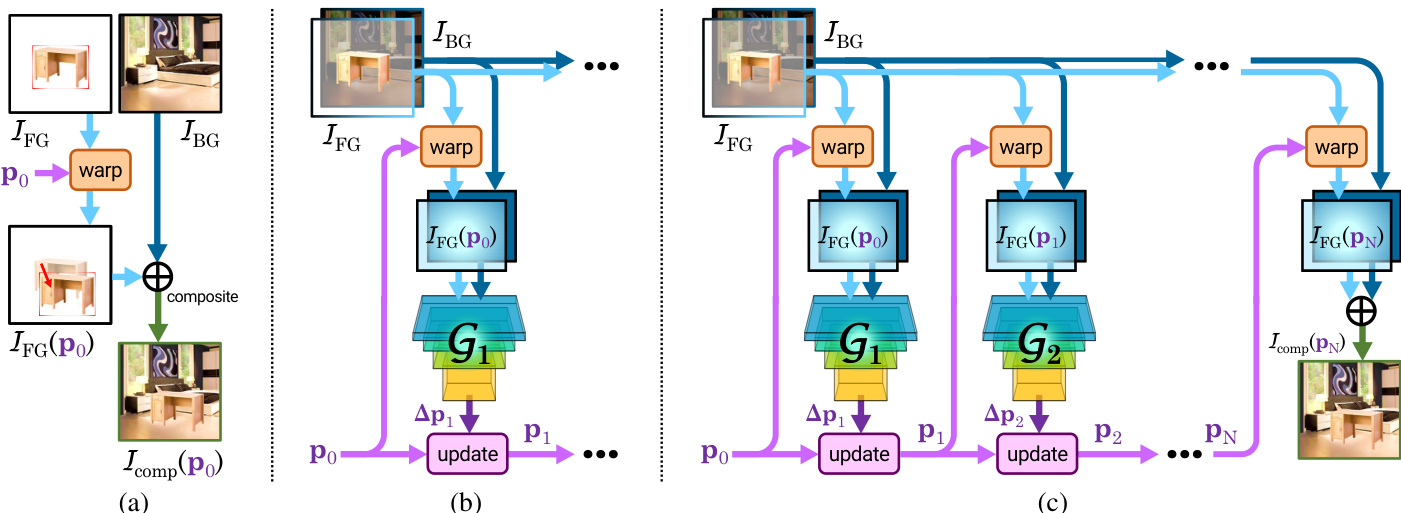
As shown in the figure below, the model employs an iterative approach to predict a series of incremental warp updates. At each iteration i, a geometric prediction network Gi takes the warped foreground image IFG(pi−1) and the background image IBG as inputs to predict a correction Δpi. The new warp state pi is then obtained by composing the previous state pi−1 with the update Δpi. This iterative refinement allows the model to learn complex geometric transformations by breaking them down into smaller, more manageable steps.
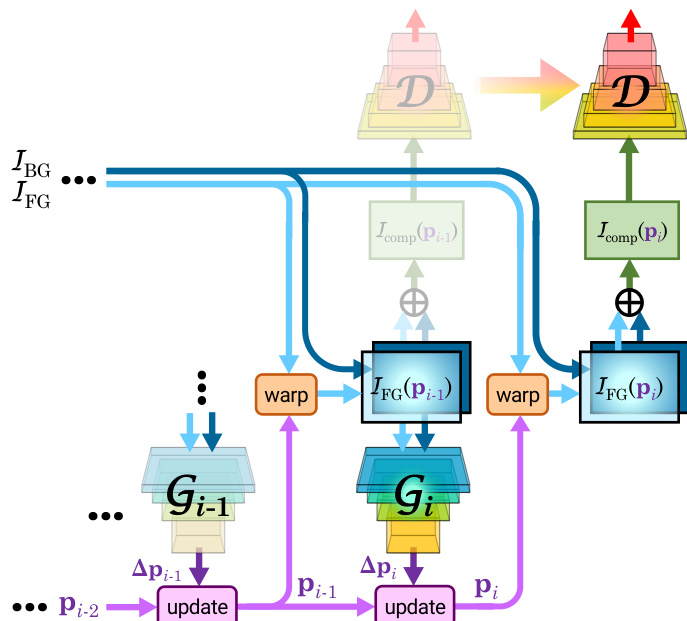
To train the network, the authors integrate the iterative STN into a GAN framework. The generator Gi produces a low-dimensional warp parameter update rather than a full image, while the discriminator D evaluates the realism of the resulting composite image. A key innovation is the sequential adversarial training strategy. The training begins with a single generator G1, and subsequent generators Gi are added one at a time. During the training of each new generator Gi, the weights of all previously trained generators are fixed. The same discriminator D is used across all stages, continuously learning to distinguish between real and fake composites. This approach ensures that each generator learns to produce a meaningful correction, building upon the work of the previous stages, which leads to faster and more robust training.
The adversarial objective is based on the Wasserstein GAN (WGAN) formulation, which provides more stable training compared to traditional GANs. The loss function for the discriminator includes a gradient penalty term to enforce the 1-Lipschitz constraint. To prevent trivial solutions where the foreground object is simply removed, a penalty term on the magnitude of the warp update Δpi is introduced, constraining it to a trust region. During sequential training, the discriminator and the current generator Gi are updated alternately. After all generators are trained, the entire network is fine-tuned end-to-end to optimize the final composite image.
The generator Gi is implemented as a convolutional neural network with an architecture of C(32)-C(64)-C(128)-C(256)-C(512)-L(256)-L(8), where C(k) denotes a 2D convolutional layer with k filters and L(k) denotes a fully-connected layer with k output nodes. The input to Gi consists of the foreground and background images, resulting in a 7-channel input. The discriminator D uses a PatchGAN architecture, which classifies local image patches for realism. The model is trained on images resized to 120×160, but the learned warp parameters are transferable to full-resolution images at test time, enabling the application of the method to high-resolution compositing tasks.
Experiment
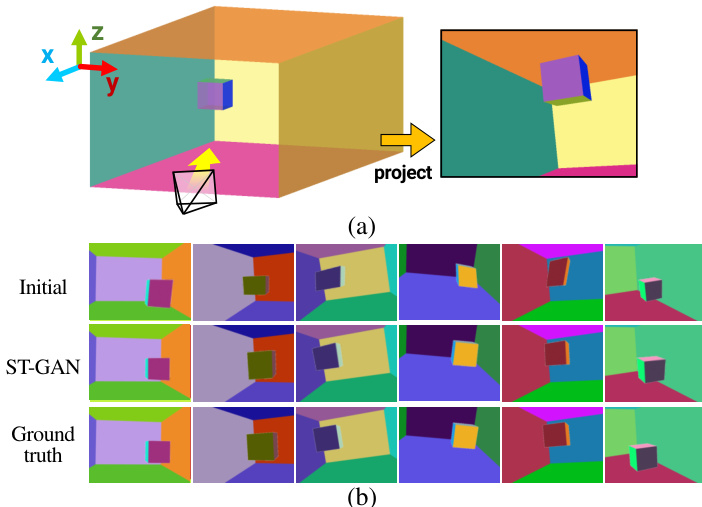
The first experiment evaluates the model by perturbing rendered 3D cubes with random homographies and training against their original ground truth, validating its capacity to correct geometric distortions while capturing a multi-modal distribution of realistic placements. The second experiment operates in an entirely unpaired setting using facial images and hand-crafted glasses, testing the system's ability to gradually warp composites into natural positions without relying on structural annotations. Qualitatively, the method successfully aligns foreground elements under moderate transformations but struggles with extreme out-of-plane rotations, ultimately demonstrating strong potential for image alignment tasks where acquiring paired data is highly challenging.
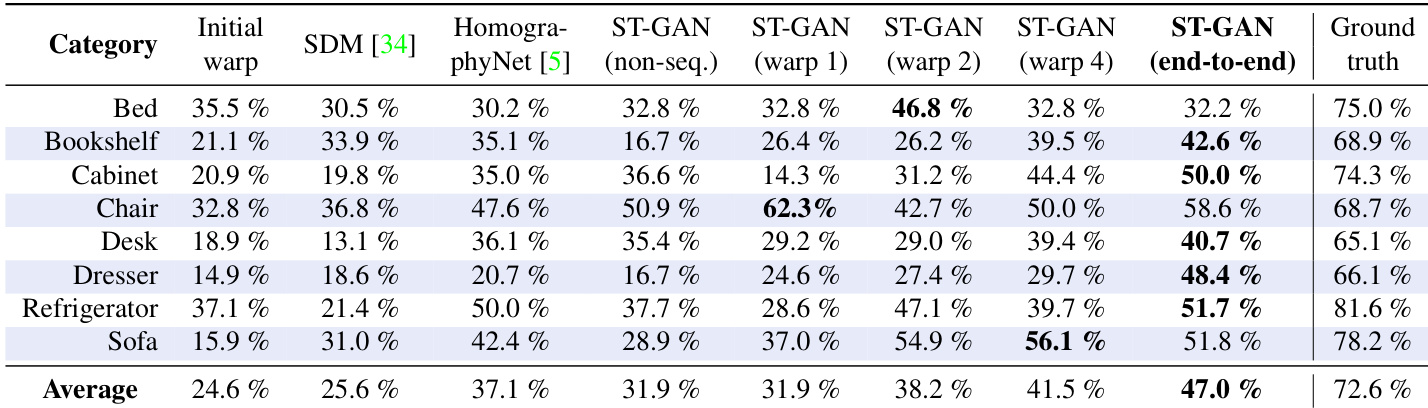
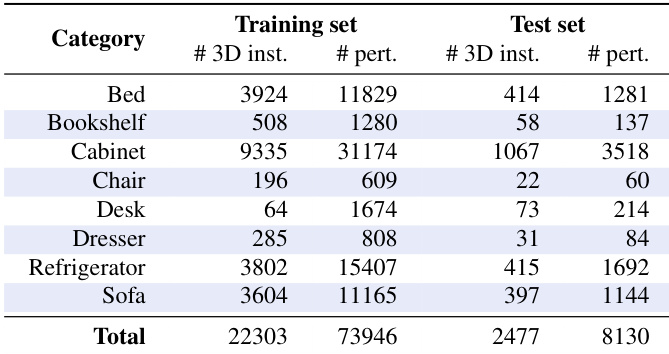
The authors evaluate ST-GAN across various furniture categories, comparing its performance against baseline methods and different variants of ST-GAN. Results show that ST-GAN consistently improves over initial warps and achieves higher realism, with the end-to-end version generally outperforming sequential warping approaches. The method demonstrates robustness across categories, though performance varies, with some objects showing more significant improvements than others. ST-GAN outperforms baseline methods and achieves higher realism compared to initial warps across all categories. The end-to-end ST-GAN variant generally performs better than sequential warping versions, particularly on certain objects like the chair and dresser. Performance varies by object, with some categories showing substantial improvement while others exhibit more modest gains.
The authors present an experiment involving the compositing of glasses on human faces in an unpaired setting, where no ground-truth paired data is available. The method uses a spatial transformer network to gradually warp the glasses into realistic positions on faces, demonstrating the ability to align objects without explicit structural information. Results show that the approach performs well for faces with limited out-of-plane rotation but struggles with more extreme rotations. The method learns to warp glasses onto faces without paired data or facial landmarks. The approach successfully aligns glasses in a gradual manner, improving realism over multiple steps. Performance degrades for faces with significant out-of-plane rotation.
The evaluation examines ST-GAN across furniture categorization and an unpaired face-glasses compositing task to assess its ability to generate realistic spatial transformations without paired data or explicit landmarks. Results demonstrate that the end-to-end variant consistently enhances realism over initial warps and generally surpasses sequential warping approaches, though performance gains vary by object complexity. In the facial compositing experiment, the model successfully learns to gradually align objects through iterative warping, yet exhibits noticeable sensitivity to extreme out-of-plane rotations. Overall, the findings highlight the method's robust capacity for unpaired spatial alignment while underscoring its limitations under severe geometric distortions.