Command Palette
Search for a command to run...
Image Captioning Using TensorFlow and Keras
Abstract
One-sentence Summary
The phrase-based hierarchical long short-term memory model, termed phi-LSTM, generates image captions by independently decoding variable-length noun phrases and abbreviated sentences before combining them during inference, yielding more novel and content-rich descriptions that achieve competitive performance on the Flickr8k, Flickr30k, and MS-COCO datasets.
Key Contributions
- This paper proposes a phrase-based hierarchical Long Short-Term Memory (phi-LSTM) model that generates image descriptions by explicitly modeling the temporal hierarchy of natural language.
- The architecture employs a two-level decoding process where a bottom phrase decoder extracts variable-length noun phrases and an upper abbreviated sentence decoder generates a condensed outline, which are combined during inference to form complete captions.
- Experimental evaluations on the Flickr8k, Flickr30k, and MS-COCO datasets demonstrate that the framework achieves competitive or superior performance compared to state-of-the-art methods while consistently producing more novel and semantically richer captions.
Introduction
Automatic image captioning bridges computer vision and natural language processing by generating descriptive text from visual data, a capability crucial for accessibility and intelligent content understanding. Traditional approaches typically rely on convolutional networks paired with sequential recurrent models that generate captions word by word. While effective for basic sequence modeling, these flat architectures fail to capture the inherent hierarchical structure of language, often resulting in rigid outputs that struggle with complex syntactic dependencies and novelty. To address this, the authors introduce a phrase-based hierarchical LSTM model that decodes captions from the phrase level up to the sentence level. The framework employs a lower decoder to generate variable-length noun phrases and an upper decoder to construct an abbreviated sentence from the final words of those phrases. By aligning the generative process with natural linguistic hierarchies, this architecture produces more structurally coherent and novel descriptions while maintaining competitive performance across standard benchmark datasets.
Method
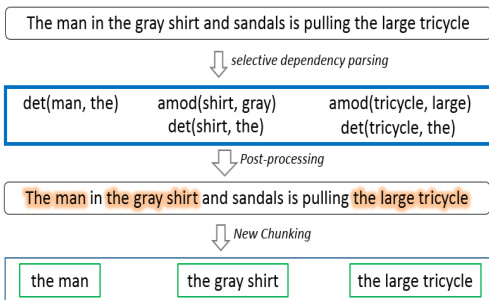
The proposed phi-LSTM model employs a hierarchical architecture to generate image captions by decomposing the task into two distinct stages: phrase-level decoding and sentence-level decoding. This framework, as illustrated in the figure below, operates in a bottom-up manner, first generating noun phrases (NPs) that represent entities within the image and subsequently constructing a complete sentence by integrating these phrases into an abbreviated sentence (AS) structure.
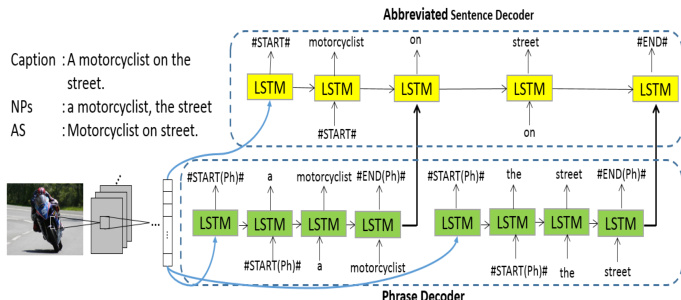
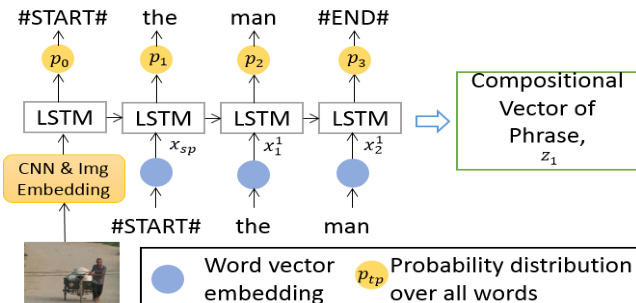
The model's core consists of two interconnected LSTM-based decoders. The first is the phrase decoder, which is responsible for generating individual NPs. Given an image I, a CNN pre-trained on ImageNet is used to extract a D-dimensional feature vector, which is then transformed into a K-dimensional image embedding using a trainable matrix Wip and bias bip. This embedded image feature, along with a start-word token xsp, serves as the initial context for the phrase decoder. The decoder processes the sequence of words within each NP step-by-step, using a word embedding matrix Wep to convert each ground truth word wtpi into a vector at each time step tp. The LSTM block at each step computes the hidden state htp based on the input xtpi, the previous hidden state htp−1, and the internal memory cell ctp. The output at each time step is a probability distribution ptp+1 over the vocabulary, representing the likelihood of the next word. The hidden state at the final time step of each NP is used as a compositional vector representation zi for that phrase.
The second component is the Abbreviated Sentence (AS) decoder. This decoder takes as input the complete caption, where each NP is treated as a single unit, and the remaining words are processed individually. The input at each time step ts is a combination of the embedded image feature, the start-word token xss, a word embedding Weswts for a word, or the compositional vector zi for a phrase. The AS decoder is designed to predict two outputs simultaneously: a binary indicator determining whether the next input is a phrase or a word (phrase indication), and a softmax distribution over the vocabulary for the next word in the AS sequence. The ground truth for the word prediction is the last word of the next phrase if the next input is a phrase, or the next word itself otherwise. This design allows the model to learn to control the flow between generating a word and substituting a phrase.
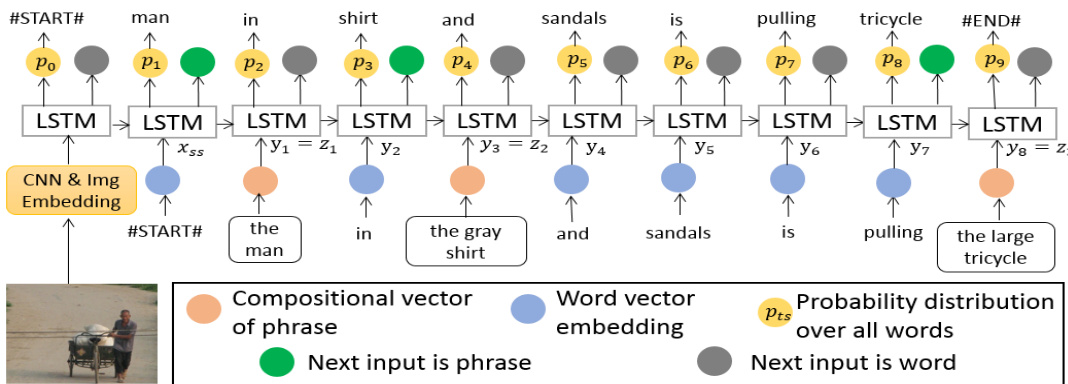
During training, the model is optimized to minimize a combined objective function. The primary component is the log-likelihood of the word predictions, which is computed as the negative average perplexity of the entire caption. This includes the perplexity of the word predictions from the phrase decoder and the AS decoder. A secondary component is the hinge loss for the phrase indication prediction, which classifies whether the next input should be a phrase or a word. The overall cost function is a weighted sum of these two components, averaged over all training samples and regularized with an L2 penalty on the model parameters.
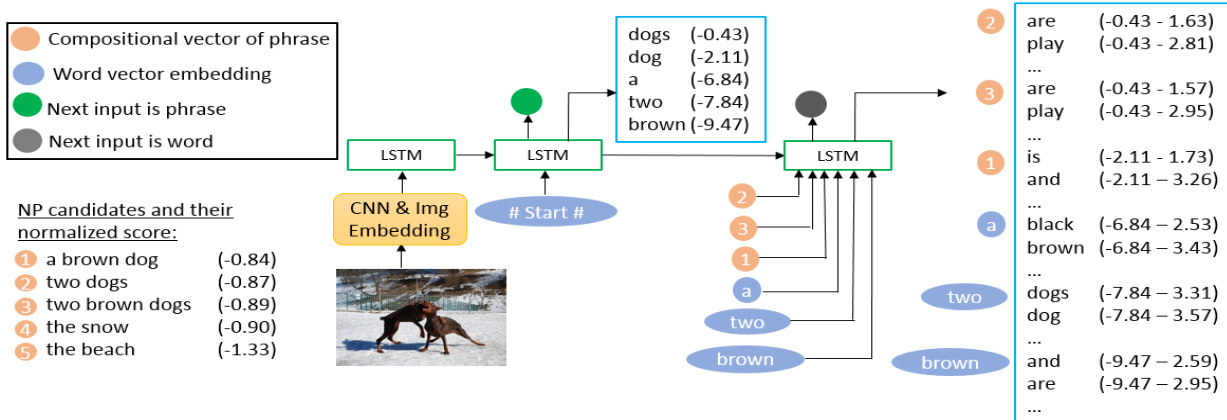
For image caption generation at inference time, the model uses a two-stage beam search process. First, the phrase decoder generates a list of candidate NPs for the given image. A beam search with beam size bp is used, and the score for each NP is computed as the sum of the log probabilities of its words, normalized by the length of the NP. A refinement step is applied to filter out low-quality candidates. Then, the AS decoder uses this list of NP candidates to generate complete captions. It performs a beam search with beam size bs, where at each step it predicts the next word or the next phrase. When a phrase is predicted, the model compares the predicted word to the list of generated NP candidates and selects the NP whose last word matches the prediction to be used as the next input. The final caption with the highest score, computed as the negative perplexity, is selected. This process ensures that the generated caption is composed of semantically meaningful phrases.
Experiment
Evaluated across three standard image captioning benchmarks, the study compares the proposed hierarchical phrase-based model against both a flat sequential baseline and various state-of-the-art architectures. Comparative experiments validate the model's competitive performance against attention-based and feature-augmented methods, while uniqueness assessments confirm that hierarchical decoding significantly enhances caption novelty and vocabulary diversity. Qualitative analysis further demonstrates that this structure improves the accurate inference of rare words and certain function words, though it remains limited in capturing complex object relations and precise counting due to the underlying CNN encoder. Ultimately, the findings establish that phrase-based hierarchical generation effectively balances descriptive precision and linguistic variety without requiring external attention mechanisms or supplementary visual inputs.
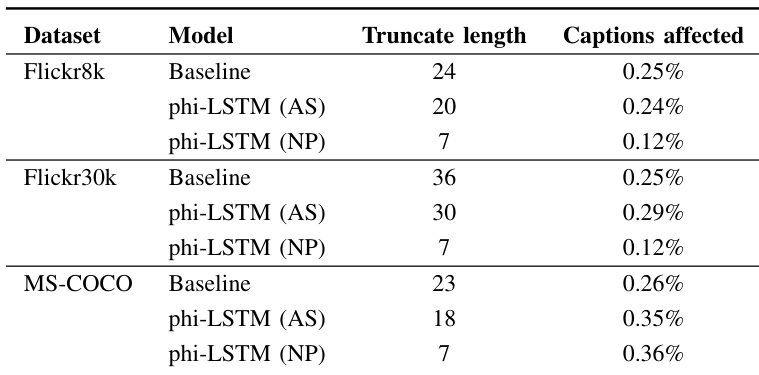
The the the table presents a comparison of caption truncation settings across different models and datasets, showing the impact of model type and truncation length on the percentage of captions affected. The phi-LSTM model with NP decoding consistently results in a lower percentage of affected captions compared to the baseline and phi-LSTM with AS decoding, particularly on the MS-COCO dataset. The phi-LSTM model with NP decoding reduces the percentage of affected captions compared to the baseline and AS decoding across all datasets. Truncation length varies significantly between models, with phi-LSTM (NP) having the shortest length and baseline models having the longest. The MS-COCO dataset shows higher percentages of affected captions for all models compared to Flickr8k and Flickr30k.
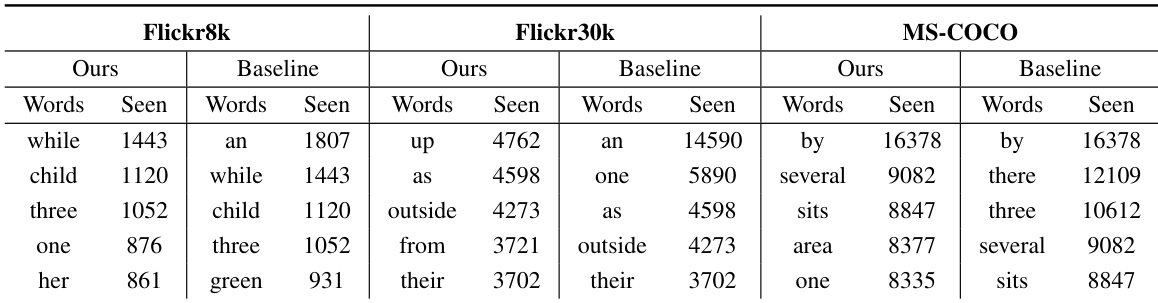
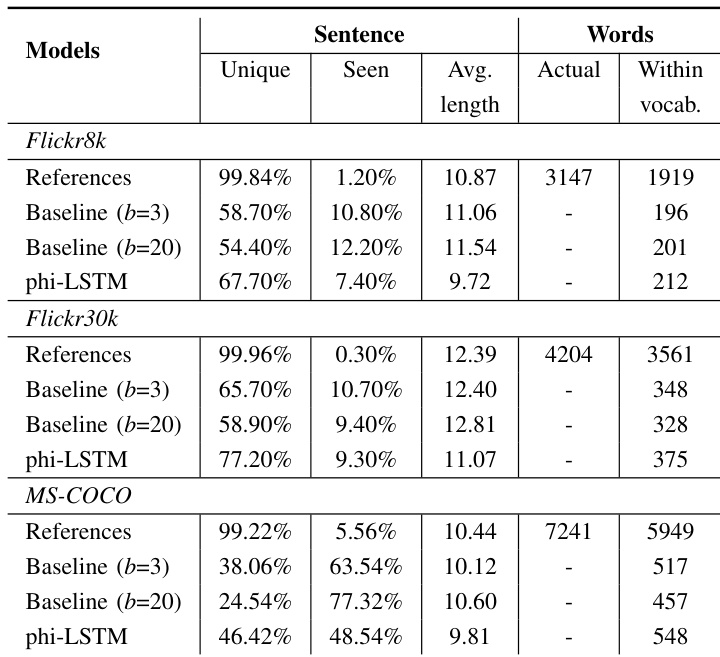
The authors compare their phrase-based model with a baseline sequential model across three datasets, focusing on the uniqueness and novelty of generated captions. Results show that their model generates more unique and novel captions while using fewer words, indicating improved diversity despite shorter outputs. The comparison highlights differences in word usage, with the proposed model better capturing less frequent words and generating captions that are less likely to be seen in the training data. The proposed model generates more unique and novel captions compared to the baseline across all datasets. The model produces shorter captions but still achieves higher diversity in word usage, especially for less frequent words. The baseline model tends to generate more common words that are frequently seen in the training data, while the proposed model avoids overused vocabulary.
The authors compare their phi-LSTM model with a baseline model using SPICE metrics to evaluate caption quality. Results show that the phi-LSTM model improves on object and attribute precision while achieving higher recall and better performance in size and color metrics. The baseline model performs better in relation and cardinality measures, but the phi-LSTM model shows significant gains in object and attribute-related aspects. The phi-LSTM model achieves higher object and attribute precision compared to the baseline. The phi-LSTM model outperforms the baseline in size and color metrics. The baseline model shows better performance in relation and cardinality measures.

The authors compare their phrase-based model with a baseline sequential model across three datasets, showing that their approach generates more unique and novel captions while improving precision in object and attribute descriptions. The results indicate that the hierarchical decoding process leads to better performance in terms of caption diversity and semantic accuracy, particularly for less frequent words. The model's design allows for consistent time-scale decoding of noun phrases, contributing to more precise and varied caption generation. The proposed model generates more unique and novel captions compared to the baseline across all datasets. The model improves precision in object and attribute descriptions, particularly for less frequent words. The hierarchical decoding process enables better performance in terms of caption diversity and semantic accuracy.
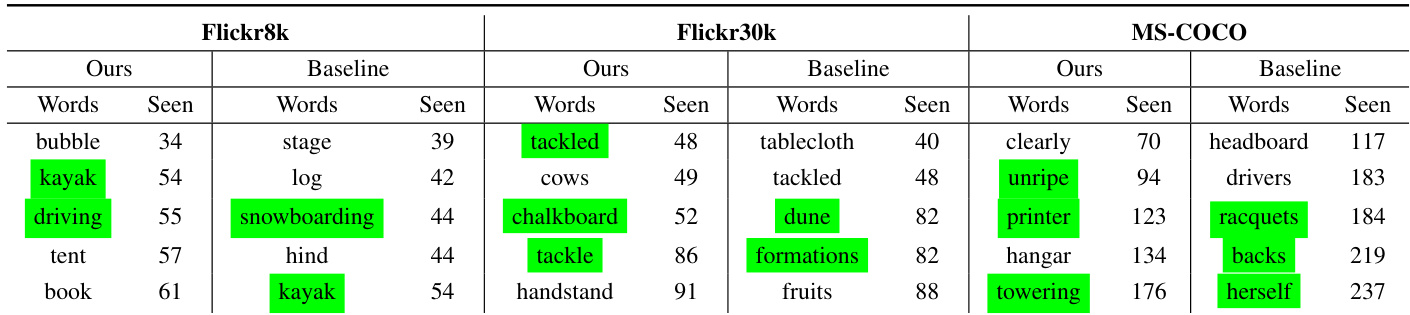
The authors compare their proposed phi-LSTM model with a baseline sequential model across three datasets, evaluating caption uniqueness, novelty, and word usage. Results show that the phi-LSTM model generates a higher percentage of unique and novel captions compared to the baseline, despite producing slightly shorter captions. The model also achieves a greater number of unique words within the vocabulary across all datasets, indicating improved lexical diversity. The phi-LSTM model generates a higher percentage of unique and novel captions compared to the baseline model. The phi-LSTM model produces a greater number of unique words within the vocabulary, indicating better lexical diversity. Despite generating shorter captions, the phi-LSTM model achieves higher uniqueness and novelty metrics across all datasets.
The experiments evaluate a proposed phi-LSTM and phrase-based model against a baseline sequential approach across multiple image captioning datasets to assess structural efficiency, lexical diversity, and semantic accuracy. By analyzing caption truncation and hierarchical decoding mechanisms, the study validates that the proposed architecture produces shorter outputs while significantly reducing generation inconsistencies. Qualitative assessments further demonstrate that the model consistently yields more unique and novel captions with enhanced accuracy in describing objects and attributes, effectively prioritizing less frequent vocabulary over common training data patterns. Ultimately, the results indicate that the hierarchical decoding strategy successfully balances concise output with richer lexical variety and more precise semantic descriptions.