Command Palette
Search for a command to run...
Accelerating Your RNN: Sequence Bucketing
Abstract
One-sentence Summary
The authors present an efficient LSTM training algorithm that accelerates variable-length sequence processing by combining optimal sequence-length-based batch bucketing with multi-GPU data parallelization, evaluating performance across wall clock time, number of epochs, and validation loss value for online handwriting recognition.
Key Contributions
- The paper introduces an efficient recurrent neural network training algorithm designed to accelerate mini-batch processing for datasets containing highly variable input sequence lengths.
- The method achieves this acceleration by implementing optimal batch bucketing based on sequence length and distributing computations across multiple graphical processing units.
- Experimental evaluations on an online handwriting recognition task using an LSTM network compare the proposed approach against a non-bucketed baseline in terms of wall clock time, number of epochs, and validation loss.
Introduction
Recurrent neural networks, including LSTMs and GRUs, excel at sequence modeling for applications like speech recognition and natural language processing, yet training them on large datasets remains computationally expensive. Prior acceleration strategies have explored adaptive learning rates, parallelization, and specialized architectures, but these methods often struggle with the inherent variability of real-world sequence data. Because mini-batch computational cost is dictated by the longest sequence in a group, researchers face a difficult trade-off between clustering sequences by length and maintaining the data shuffling required for stable convergence. To address this bottleneck, the authors introduce a sequence bucketing algorithm that efficiently organizes variable-length inputs, significantly accelerating mini-batch gradient descent without compromising training stability.
Dataset

- Dataset Composition and Sources: The authors use an online handwriting recognition dataset containing approximately 1 GB of raw binary samples in Afrikaans and English. Data collection was performed using Samsung Galaxy Note devices equipped with a stylus.
- Subset Details and Labeling: The validation set comprises 5% of randomly selected samples with varying sequence lengths. While the dataset provides textual reference labels for the expected output sequences, these labels are not explicitly aligned with the corresponding handwriting stroke sequences.
- Data Usage and Training Strategy: The authors train an LSTM model using the CTC loss function via Theano and Lasagne. They implement a length-based bucketing strategy that feeds shorter sequences first and gradually increases the bucket number at each epoch. The training process runs on a cluster of six NVIDIA Tesla K40m GPUs.
- Processing and Metadata: No explicit cropping or alignment preprocessing is applied to the raw stroke data. The unaligned textual labels are handled implicitly by the CTC mechanism, which learns the mapping between input strokes and output characters during optimization.
Method
The authors leverage a parallel training framework for recurrent neural networks (RNNs) that combines sequence bucketing with multi-GPU data parallelization to accelerate training, particularly in scenarios where input sequences exhibit significant length variation. The overall training workflow operates on a map-reduce paradigm across multiple GPU processes. As shown in the figure below, the process begins with computed features stored in a data store, which are then passed to a main CPU process responsible for shuffling and partitioning the data into equal portions for distribution across GPU processes. Each GPU process independently performs sequence bucketing on its assigned data subset to optimize mini-batch processing efficiency by clustering sequences according to their lengths. This step mitigates the inefficiency caused by padding shorter sequences to match the length of the longest sequence in a batch, thereby reducing computational overhead. The bucketing strategy is implemented using a dynamic programming algorithm that minimizes the total processing time by optimally grouping sequences into a predefined number of buckets. After training on individual mini-batches within each bucket, the GPU processes return their updated model parameters. These partial models are then aggregated in the main process through a reduction step to produce the final model. The framework is designed to scale across multiple GPUs, as illustrated in the diagram, where six NVIDIA Tesla K40m GPUs are employed for parallel training. 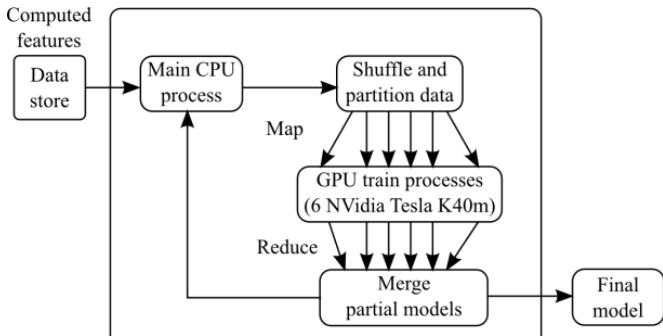
Experiment
The evaluation setup trains an LSTM model under varying sequence bucketing configurations and multi-GPU parallel architectures to validate their effects on computational efficiency and convergence behavior. Experimental results indicate that structured sequence bucketing significantly reduces epoch processing time and accelerates early-stage loss reduction, with a moderate bucket configuration delivering the optimal trade-off between training speed and validation performance. Additionally, distributing the workload across multiple GPUs consistently improves long-term validation accuracy compared to single-GPU execution. Overall, these findings confirm that integrating optimized sequence grouping with parallel hardware substantially streamlines the training workflow while enhancing model convergence.
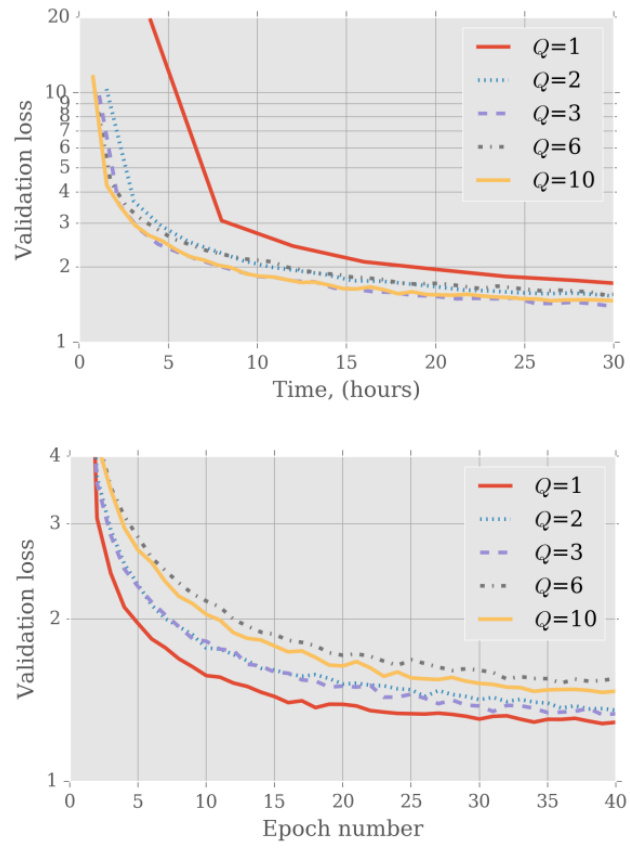
The authors investigate the impact of sequence bucketing on LSTM model training, analyzing validation loss over time and epochs for different bucket configurations. Results show that increasing the number of buckets improves training efficiency and convergence speed, with the best performance achieved at a specific bucket count. Validation loss decreases more rapidly with higher bucket counts, especially in the early training stages. Training speed improves as the number of buckets increases, with the fastest convergence observed for a specific configuration. The validation loss stabilizes faster with optimized bucketing compared to the baseline case.
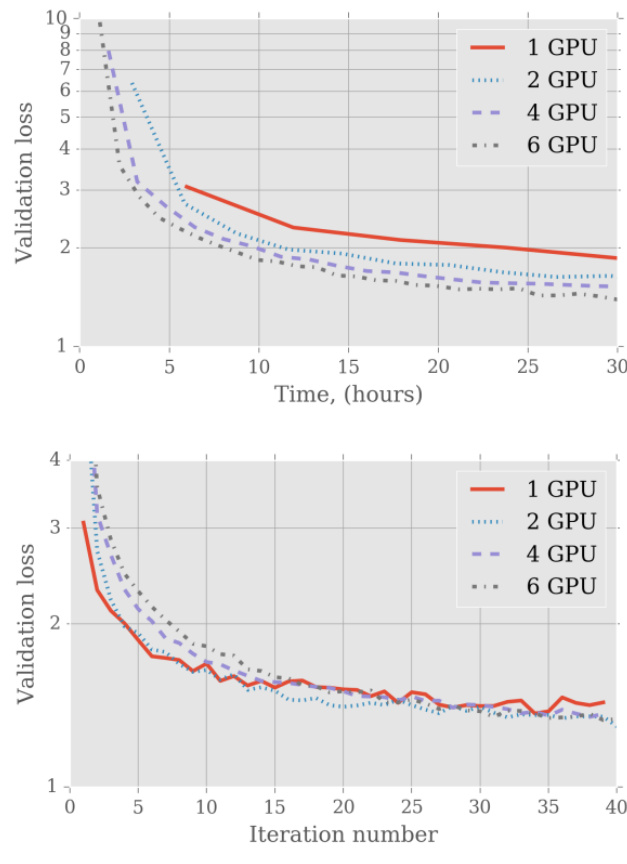
The authors investigate the impact of using multiple GPUs and sequence bucketing on the training of an LSTM model, focusing on validation loss and training speed. Results show that increasing the number of GPUs reduces the validation loss over time and accelerates convergence, with the best performance achieved using six GPUs. The validation loss decreases more rapidly with more GPUs, especially in the initial training phase. Using more GPUs leads to faster convergence of validation loss during training. The validation loss decreases more quickly with increasing GPU count, particularly in the early stages of training. Training with six GPUs achieves a lower validation loss compared to using one GPU after 30 hours of training.
The experiments evaluate LSTM training efficiency by systematically varying sequence bucket configurations and scaling across multiple GPUs to validate their respective impacts on convergence and loss reduction. Both approaches consistently accelerate model training and lower validation loss, with the most pronounced improvements occurring during the initial phases. Overall, the study demonstrates that strategically optimizing bucket counts and leveraging parallel hardware substantially enhance training stability and speed, achieving optimal performance at specific configuration thresholds.