Command Palette
Search for a command to run...
Divisive-Agglomerative Algorithm and Complexity of Automatic Classification Problems
Divisive-Agglomerative Algorithm and Complexity of Automatic Classification Problems
Alexander Rubchinsky
Complexity and Learning Curve Analysis for Classification
Abstract
An algorithm of solution of the Automatic Classification (AC for brevity) problem is set forth in the paper. In the AC problem, it is required to find one or several partitions, starting with the given pattern matrix or dissimilarity/similarity matrix. The three-level scheme of the algorithm is suggested. At the internal level, the frequency minimax dichotomy algorithm is described. At the intermediate level, this algorithm is repeatedly used at alternations of divisive and agglomerative stages, which causes the construction of a classifications family. At the external level, several runs of the algorithm of the intermediate level are completed; thereafter among all the constructed classifications families the set of all the different classifications is selected. The latest set is taken as a set of all the solutions of the given AC problem. In many cases, this set of solutions can be significantly contracted (sometimes to one classification). The ratio of cardinality of the set of solutions to cardinality of the set of all the classifications found at the external level is taken as a measure of complexity of the initial AC problem. For classifications of parliament members according to their vote results, the general notion of complexity is interpreted as consistence or rationality of this parliament policy.
One-sentence Summary
Alexander Rubchinsky presents a three-level divisive-agglomerative algorithm for automatic classification that repeatedly applies a frequency minimax dichotomy routine across alternating divisive and agglomerative stages to construct classification families, defines problem complexity as the ratio of distinct solution classifications to the total number of generated partitions, and applies this metric to evaluate parliamentary voting consistency and rationality.
Key Contributions
- A three-level algorithmic scheme is proposed for the Automatic Classification problem to systematically construct a family of partitions. The framework applies a frequency minimax dichotomy algorithm at the internal level, alternates divisive and agglomerative stages at the intermediate level, and selects unique classifications across multiple external runs.
- A formal complexity metric is defined as the ratio between the cardinality of the final unique solution set and the total number of classifications generated during the external search phase. This measure quantifies the inherent difficulty of the Automatic Classification problem based on the constructed solution family.
- The algorithm is applied to voting records from the second, third, and fourth RF Dumas to analyze legislative activity. The computed complexity index is interpreted as a measure of policy consistency and rationality within these parliamentary bodies.
Introduction
Automatic classification serves as a critical tool for organizing complex data, yet its real-world deployment is frequently complicated by unpredictable problem difficulty. Practitioners often encounter ambiguous solutions, non-unique groupings, and severe computational bottlenecks when scaling to high-dimensional datasets. Previous studies have largely ignored a unified framework for measuring classification complexity, instead focusing narrowly on the computational cost of isolated algorithms. To bridge this gap, the authors formalize a new notion of automatic classification complexity and develop a generalized algorithm that constructs a complete family of reasonable solutions rather than forcing a single output. This framework allows domain experts to systematically evaluate and select optimal groupings using additional contextual criteria, a capability the authors demonstrate through an analysis of voting behavior in the Russian State Duma.
Dataset
- Dataset composition and sources: The authors do not specify any dataset composition or external sources in the provided excerpt.
- Subset details: The text omits key details for each subset, including sizes, origins, and filtering rules.
- Data usage: The authors do not describe how they apply the data, such as training splits, mixture ratios, or evaluation protocols.
- Processing and metadata: No cropping strategies, metadata construction steps, or preprocessing pipelines are outlined.
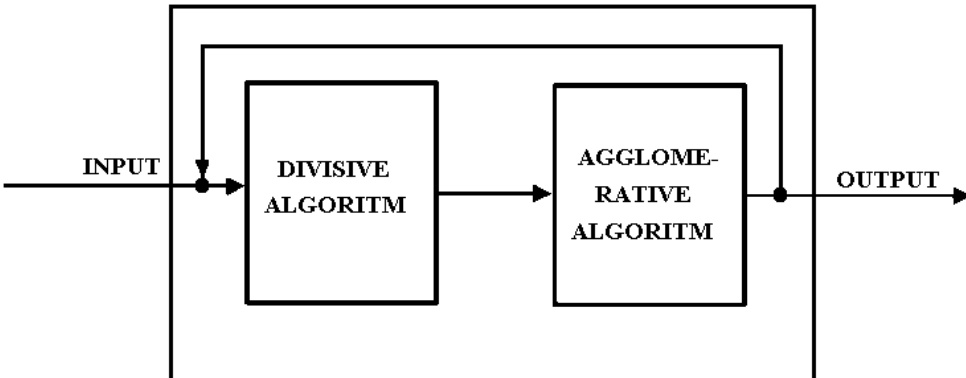
Method
The proposed method for solving the Automatic Classification (AC) problem operates through a three-level hierarchical framework, structured to progressively refine and validate classifications. At the core of this framework is a Divisive-Agglomerative Algorithm (DAA), which alternates between divisive and agglomerative stages to generate a family of classifications. The process begins with the construction of a neighborhood graph from the input dissimilarity matrix, where vertices represent objects and edges connect each object to its nearest neighbors based on proximity, forming a connected graph. This graph serves as the primary structure for subsequent operations.
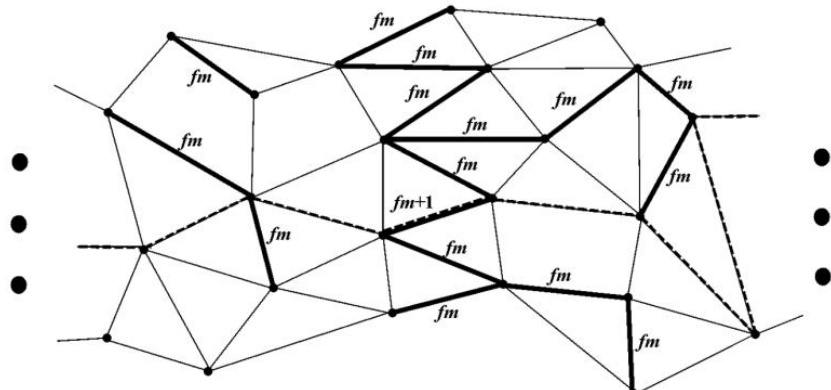
At the internal level, the algorithm employs a frequency minimax dichotomy method to recursively partition the graph. This method initializes edge frequencies to zero and iteratively selects random vertex pairs. For each pair, a minimal path is constructed using Dijkstra's algorithm, where edge length is defined by current frequency. The frequencies of all edges in the path are incremented by one. This accumulation process is repeated for a fixed number of iterations, T, to stabilize edge frequencies. After this stage, the maximum frequency fmax is recorded. The algorithm then executes one final path construction and checks if the new maximum frequency fmod remains unchanged. If so, the process repeats until fmod<fmax. At this point, all edges with frequency fmax are removed, and the resulting connectivity components define the dichotomy of the graph. The largest component is designated as the first part, while all others form the second part. This procedure is designed to find a cut that maximizes a decomposition function, effectively separating graph components based on edge frequency.
The intermediate level, governed by the DAA, orchestrates the alternation of divisive and agglomerative stages. The process starts with the initial graph, which is dichotomized into two classes, forming the first essential classification D2. The larger of the two resulting subgraphs is then subjected to another dichotomy, yielding a classification D3 into three classes. This iterative divisive process continues for a maximum number of k dichotomies, producing a sequence of essential classifications Dj for j=2,3,…,k+1. Following each divisive step, the agglomerative stage is initiated. For a given essential classification Dj, the algorithm constructs a series of adjoint classifications Cjj,Cj−1j,…,C2j by successively merging the most densely connected subsets, which is achieved by joining components connected by the maximum number of edges. This agglomerative process generates a family of classifications that are complementary to the divisive ones.
The external level of the algorithm addresses the stochastic nature of the process by executing multiple independent runs of the DAA. Due to the random selection of vertex pairs in the internal dichotomy stage, different runs can produce varying sets of classifications. The final output is determined by collecting all distinct classifications generated across all runs and selecting the unique ones. This step is crucial for identifying stable, consistent classifications that are not artifacts of random initialization. The framework's design ensures that even when individual runs yield different results, the repetition allows for the extraction of a reliable and robust solution set, which is then analyzed for stability and other criteria to determine the most meaningful classification.
Experiment
The study evaluates legislative behavior across the second, third, and fourth Russian State Dumas by modeling deputy voting records as vectors and applying a classification algorithm to track political coordination over time. Experiments validate the proposed method's parameter robustness and compare its classification stability against the K-means algorithm, demonstrating that the new approach consistently produces more reliable and coherent deputy groupings. Qualitatively, the analysis reveals that classification complexity serves as an effective indicator of systemic legislative incoordination, with measurable fluctuations aligning with major political realignments. Ultimately, the findings confirm that the metric captures overarching dynamics of collective decision-making rather than isolated voting outcomes, establishing its value as a stable analytical tool for political science research.
The authors analyze voting patterns in the Russian State Duma across multiple terms, using a method that measures the complexity of classifications derived from deputies' voting behavior. The complexity metric, calculated based on dissimilarity between deputies' voting vectors, varies over time and is influenced by the parameters of the algorithm used. The analysis reveals that classifications generated by the proposed method are more stable and consistent than those obtained using the K-means method, particularly in capturing large, coherent groups of deputies. The complexity of voting-based classifications varies over time and is influenced by algorithm parameters such as the number of dichotomies and runs. Classifications generated by the proposed method are more stable and consistently form larger, coherent groups compared to those from the K-means method. The complexity metric reflects the inconsistency and incoordination in political decision-making, not just the outcome of individual votes.
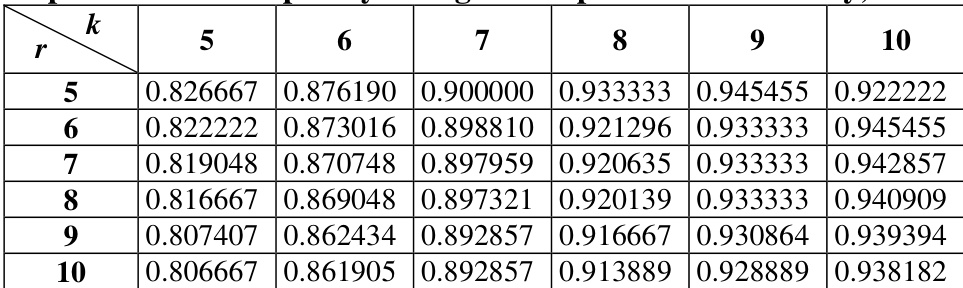
The authors analyze voting patterns in the Russian State Duma across multiple legislative periods using a complexity measure derived from classification methods. Results show that the complexity of voting classifications varies significantly between different Dumas, with Duma 2 exhibiting the highest complexity and Duma 3 the lowest, while Duma 4 shows intermediate values. The analysis suggests that complexity reflects the level of inconsistency or incoordination in political decision-making. Complexity of voting classifications is highest in Duma 2 and lowest in Duma 3, with Duma 4 showing intermediate values. The complexity measure captures the inconsistency or incoordination in political decision-making across different legislative periods. The method used produces more stable classifications compared to K-means, particularly in identifying large, cohesive groups of deputies.

The authors analyze voting patterns in the Russian State Duma across multiple legislative terms, using a mathematical model to assess the complexity of classifications derived from deputies' voting behavior. The analysis reveals variability in complexity over time, with some periods showing higher instability in voting alignments, and compares the stability of classifications generated by different clustering methods. The complexity metric is interpreted as a measure of political inconsistency or incoordination, reflecting the overall structure of decision-making rather than individual vote outcomes. Complexity of voting classifications varies across different periods, indicating shifts in political alignment and coordination. The proposed method produces more stable classifications compared to K-means, with larger and more consistent groups of deputies. Complexity is interpreted as a measure of political incoordination, influenced by the overall voting patterns rather than individual votes.
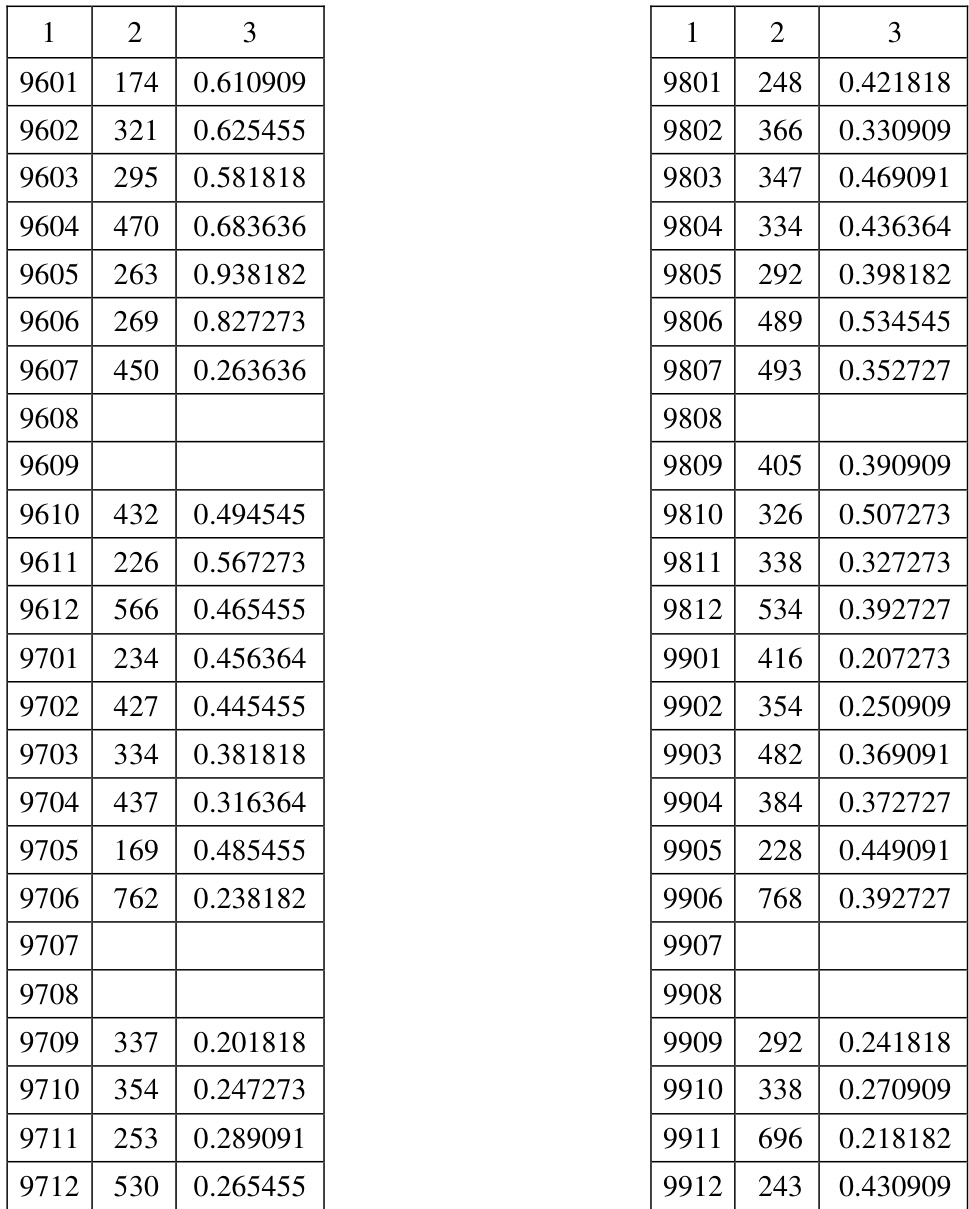
The authors analyze voting patterns in the Russian State Duma across multiple terms, using a method that measures the complexity of classifications derived from deputy voting behavior. The analysis reveals variability in complexity over time, with some periods showing lower complexity indicating more consistent voting behavior, while others exhibit higher complexity suggesting greater inconsistency or incoordination among deputies. The method is compared to K-means clustering, demonstrating greater stability in the classifications produced by the proposed approach. Complexity of voting classifications varies across different periods, with lower values indicating more consistent voting behavior among deputies. The proposed method produces more stable classifications compared to K-means clustering, particularly in cases where large, dominant groups are present. Complexity is interpreted as a measure of inconsistency or incoordination in political decision-making, rather than being determined by individual vote outcomes.
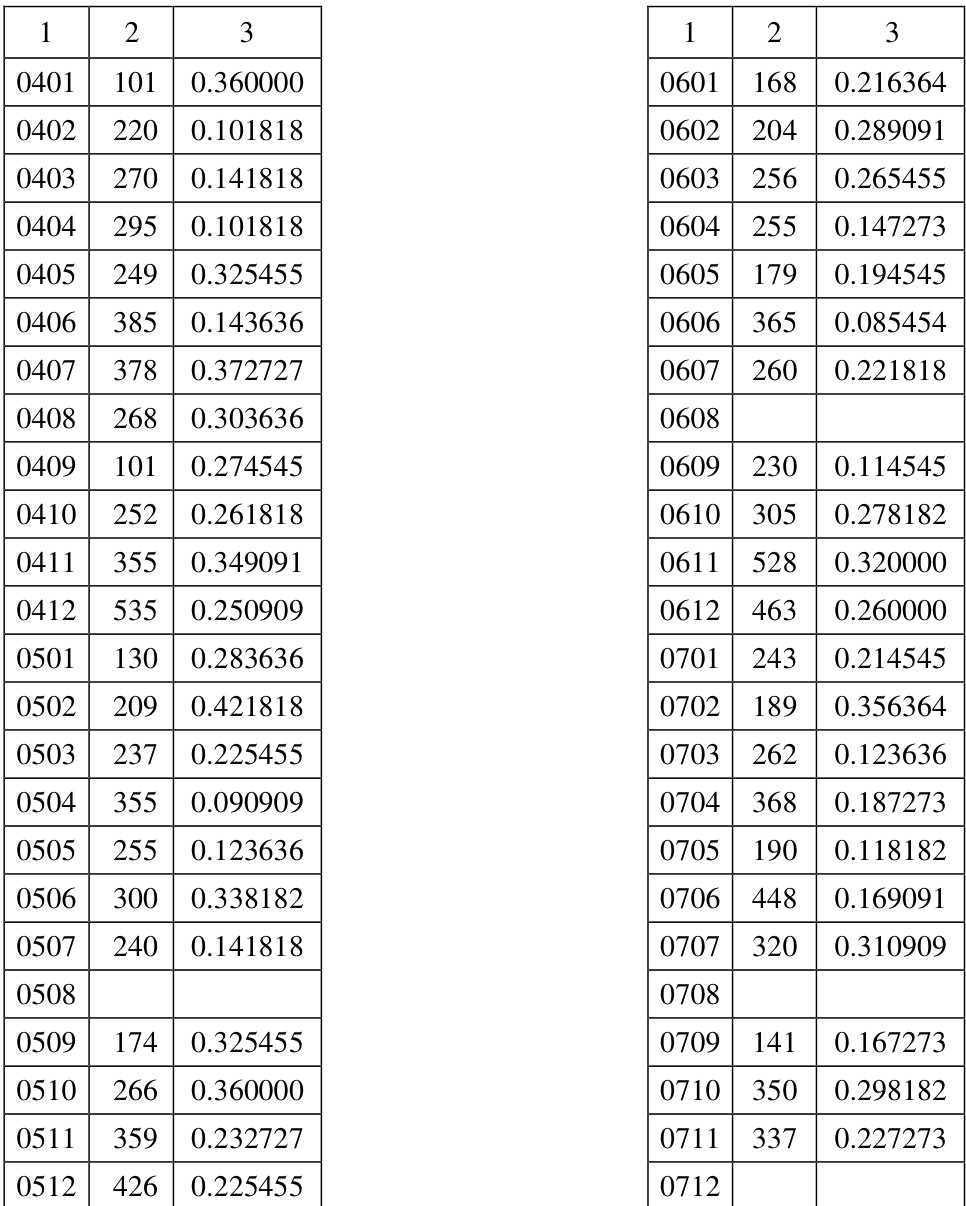
The authors analyze the complexity of classifications derived from voting patterns in the Russian State Duma across multiple legislative periods, using a method based on dissimilarity matrices and consecutive dichotomies. The complexity values vary over time and are influenced by the parameters of the algorithm, with some classifications showing greater stability than others, particularly when compared to K-means clustering. The complexity is interpreted as a measure of political inconsistency or incoordination, reflecting the overall structure of voting behavior rather than individual vote outcomes. Complexity of voting classifications varies across different legislative periods, with noticeable trends observed in smoothed data. The suggested method produces more stable classifications than K-means, especially in cases where large, distinct groups of deputies are present. Complexity is interpreted as a measure of political incoordination, influenced by the overall voting pattern rather than individual votes.
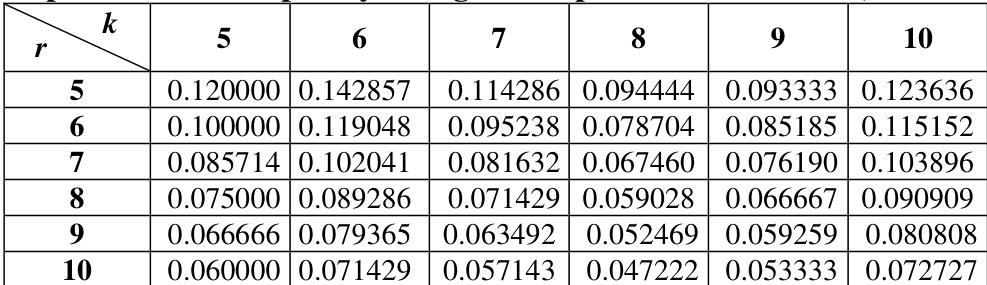
The study evaluates voting patterns across multiple Russian State Duma legislative terms by applying a complexity metric derived from classification algorithms that measure dissimilarities in deputy voting behavior. This experimental framework validates that classification complexity fluctuates across periods, functioning as a qualitative indicator of political coordination versus inconsistency in legislative decision-making. Overall, the findings demonstrate that the proposed approach consistently yields more stable and coherent deputy groupings than traditional K-means clustering, confirming its reliability for tracking structural shifts in political alignment.