Command Palette
Search for a command to run...
Movie Recommendation System Using TensorFlow
Abstract
One-sentence Summary
The authors apply an Artificial Immune System to Collaborative Filtering for a movie recommendation system, employing Kendall tau and Weighted Kappa affinity measures to calculate correlation coefficients, with testing indicating that Weighted Kappa is more suitable than Kendall tau for this application.
Key Contributions
- Integrates Artificial Immune System (AIS) principles into collaborative filtering to construct a movie recommendation engine that leverages adaptive, immune-inspired models for user preference matching.
- Implements Kendall tau and Weighted Kappa affinity measures to compute correlation coefficients between users, providing a structured approach to quantifying preference similarity.
- Demonstrates through comparative testing that the Weighted Kappa algorithm outperforms Kendall tau, establishing it as the more effective affinity measure for movie recommendation tasks.
Introduction
Recommendation systems address a common real-world challenge by helping users make informed choices when personal experience is lacking, with collaborative filtering serving as a widely adopted technique that predicts preferences based on similar users. Traditional collaborative filtering approaches often struggle to accurately identify optimal user clusters and compute robust similarity metrics, which can limit recommendation precision and adaptability. To overcome these hurdles, the authors integrate Artificial Immune Systems into the collaborative filtering framework and systematically evaluate Weighted Kappa and Kendall tau correlation methods to determine which approach more effectively measures user similarity and enhances prediction accuracy.
Dataset

- Dataset Composition and Sources: The authors use a publicly available movie rating collection originally distributed by Compaq Research (formerly DEC Research). The full corpus contains 2,811,983 ratings from 72,916 users across 1,628 movies and has been widely adopted in collaborative filtering studies.
- Key Subset Details: Rather than dividing the data into separate training or validation subsets, the authors treat the entire collection as a unified dataset. They apply a pairwise filtering rule that discards any rating combination where one value is zero and the other is non-zero. Only identical zero pairs or mutually non-zero pairs are retained for analysis.
- Model Usage: The filtered ratings power an artificial immune system based recommendation engine. The authors compute concordance and discordance counts between user pairs, derive a concordance probability ratio, and use this metric to estimate the likelihood of future rating agreement across commonly viewed films.
- Processing and Pairwise Handling: The dataset undergoes a concordance scoring pipeline instead of conventional training and testing splits. The authors extract user interactions, classify them as concordant or discordant, and apply a mathematical transformation to calculate the expected proportion of matching versus mismatching ratings for any given number of shared movie views.
Method
The proposed recommendation system integrates Artificial Immune System (AIS) technology with Collaborative Filtering (CF) to generate movie recommendations. The overall framework operates as a two-stage process: first, AIS identifies a group of users with similar preferences to the target user, and then CF computes recommendations based on this selected group. The system begins with a database storing users' movie preferences, which are represented as vote scores for various movies. When a user inputs their preferences for a subset of movies, the system treats this user as an antigen and the database users as candidate antibodies. The AIS framework is applied to select a subset of antibodies—users whose preferences are most similar to the antigen—based on affinity measures between the antigen and antibodies, as well as between antibodies themselves.
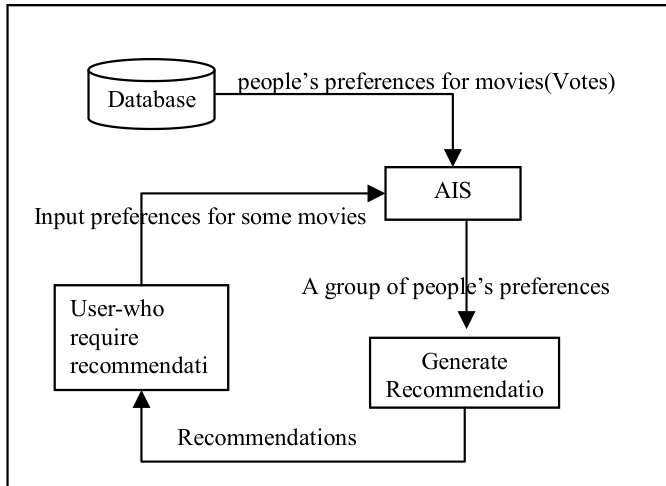
As shown in the figure below, the AIS module processes the user's input and the database to extract a group of users with similar preferences. This group is then passed to the CF module, which computes a weighted average of their movie ratings to generate recommendations. The weights assigned to each selected user are derived from their affinity to the antigen and their mutual affinities with other users in the group. The final recommendation is generated by aggregating these weighted scores.
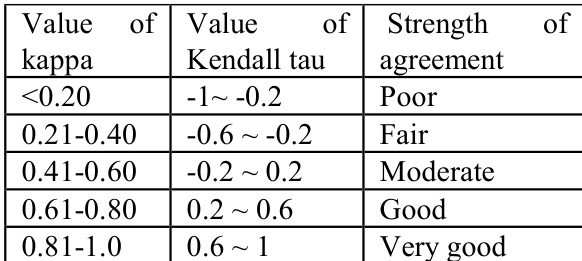
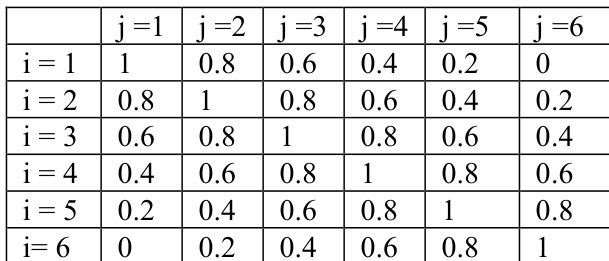
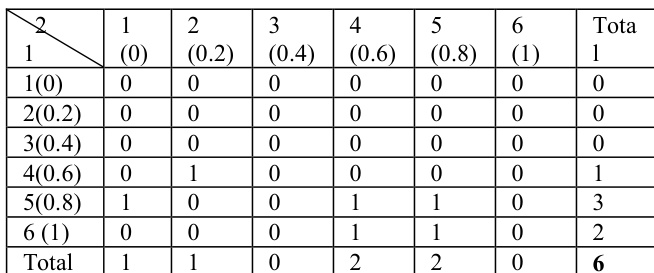
Two affinity measure algorithms are employed to quantify similarity: Weighted Kappa and Kendall tau. Weighted Kappa evaluates agreement between two users based on observed and expected agreement frequencies, with weights assigned according to the magnitude of rating differences. The weight for a cell (i,j) in the agreement matrix is defined as wij=1−g−1∣i−j∣, where g is the number of rating categories (six in this case: 0, 0.2, 0.4, 0.6, 0.8, 1). The observed agreement po(w) is computed as n1∑i=1g∑j=1gwijfij, where n is the number of common movies and fij is the count of agreements in rating category i and j. Since no chance agreement is expected in this context, pe(w)=0, and the weighted kappa simplifies to kw=po(w).
Kendall tau, on the other hand, assesses concordance between paired observations. For a pair of movies, if the relative ranking of two users is consistent, the pair is concordant; otherwise, it is discordant. The affinity is calculated as τ^=n(n−1)2S, where S=C−D, C is the number of concordant pairs, D is the number of discordant pairs, and n is the number of common movies. This measure ranges from −1 to +1, with higher values indicating stronger agreement.
The recommendation generation step computes a prediction for an unrated movie using a weighted average of the ratings from the selected group of users. The prediction formula is given by:
prediction=∑i=1100(weighti×1)∑i=1100(weighti×VoteScorei)Here, weighti corresponds to the concentration of the i-th antibody (user) for the movie, which reflects both the user's similarity to the target and the similarity of the user to others in the group. VoteScorei is the rating given by the i-th user to the movie. This weighting scheme ensures that users with higher affinity and stronger consensus within the group contribute more significantly to the recommendation.
Experiment
The study evaluates a movie recommendation system by assessing predictive accuracy and correlation stability across a user dataset using both Kendall tau and Weighted Kappa methods. These experiments validate how each algorithm manages sparse rating data, demonstrating that Kendall tau discards significant information and yields unstable correlation values due to its sensitivity to zero-value pairs. Conversely, the Weighted Kappa approach proves more reliable and better adapted to the categorical nature of movie ratings. Despite the theoretical drawbacks of Kendall tau, both methods ultimately deliver comparable prediction performance, indicating a complex relationship between correlation stability and actual recommendation accuracy that requires further exploration.
The authors compare the performance of Kendall tau and Weighted Kappa correlation methods in a movie recommendation system, analyzing their ability to handle zero values and prediction accuracy. Results indicate that while Kendall tau may ignore significant information and produce inconsistent results, Weighted Kappa consistently yields higher correlation values and slightly better prediction accuracy, suggesting it is more suitable for the given recommendation task. Weighted Kappa produces consistently higher correlation values compared to Kendall tau, which can be negative or low in some cases. Kendall tau ignores a large portion of data, leading to potential loss of information, whereas Weighted Kappa avoids this issue. Despite the theoretical advantages of Weighted Kappa, both methods yield similar prediction accuracy, indicating a need for further investigation into the discrepancy.
The authors compare the performance of Kendall tau and Weighted Kappa methods in a movie recommendation system, analyzing correlation values and prediction accuracy. Results show that while Kendall tau ignores a significant portion of data due to zero values, both methods yield similar prediction accuracy, with Kappa producing consistently higher correlation values. The authors conclude that Kappa is more suitable for movie recommendation problems due to its ability to handle ties and avoid issues with zero values. Kendall tau method ignores a substantial amount of data due to zero values, leading to potential information loss. Prediction accuracy is similar for both Kendall tau and Weighted Kappa methods, despite differences in correlation values. Weighted Kappa produces consistently higher correlation values and is considered more suitable for movie recommendation systems.
The authors analyze the performance of correlation methods in a movie recommendation system, comparing Kendall tau and Weighted Kappa. Results show that while Kendall tau ignores a significant portion of data due to zero values, both methods yield similar prediction accuracy, suggesting Kappa may be more suitable despite the lack of expected performance differences. The comparison of correlations between methods reveals that Kappa consistently produces higher values, whereas Kendall can yield negative or low values. Kendall tau ignores a large portion of data due to zero values, which may affect its reliability. Prediction accuracy is similar between Kendall tau and Weighted Kappa, despite theoretical advantages of Kappa. Weighted Kappa produces consistently higher correlation values compared to Kendall tau, indicating better stability.
This study evaluates Kendall tau and Weighted Kappa correlation methods within a movie recommendation system to assess their handling of zero-value data, correlation stability, and predictive performance. The analysis reveals that Kendall tau discards substantial information due to its treatment of zero values, often resulting in inconsistent or low correlation scores, whereas Weighted Kappa effectively manages ties and sparse data to deliver consistently higher and more reliable correlations. Although both methods achieve comparable prediction accuracy, Weighted Kappa demonstrates superior stability and data retention, making it the more suitable metric for recommendation tasks.