Command Palette
Search for a command to run...
Online Tutorial | Massive Modification With a Single SIM Card: MiniCPM-V-4.6, 1.3B Open Source Model Supports Image Understanding/Video Understanding/OCR/Multi-turn Multimodal Dialogue (using Wallfacer and Other open-source libraries).

In the past few years, the entire AI industry has been almost entirely shrouded in the narrative of Scaling Law. The larger the parameters and the more training data, the closer the model seems to be to "general intelligence." From hundreds of billions to trillions of parameters, large models have continuously refreshed people's imagination of reasoning ability and world knowledge, and have also made "piling up computing power and scaling up" the industry's default development path.
But as AI truly begins to be applied in industry, a real problem gradually emerges:Not all scenarios require supermodels to be deployed in cloud data centers.High inference costs, uncontrollable network latency, and increasingly sensitive data privacy risks are causing bottlenecks in the "large and comprehensive" model approach. The "impossible triangle" between performance, timeliness, and cost has become a problem that AI democratization must address.
Thus, a seemingly counterintuitive trend began to emerge: models with smaller parameters were demonstrating higher efficiency and cost-effectiveness in an increasing number of real-world scenarios, especially in edge devices and high-concurrency industrial environments.Lightweight models are taking on fundamental tasks such as OCR, image question answering, and intent recognition.They can run offline on mobile devices at millisecond speeds, and also handle routing and cost reduction within the RAG system, becoming a crucial infrastructure for the true implementation of AI applications.
Recently, Facewall Intelligence, Tsinghua University, and OpenBMB jointly open-sourced the next-generation edge multimodal model MiniCPM-V 4.6. This model has only about 1.3B parameters, but it supports image understanding, video understanding, OCR and multi-turn multimodal dialogue capabilities, and has surpassed other models of the same level in multiple evaluations.
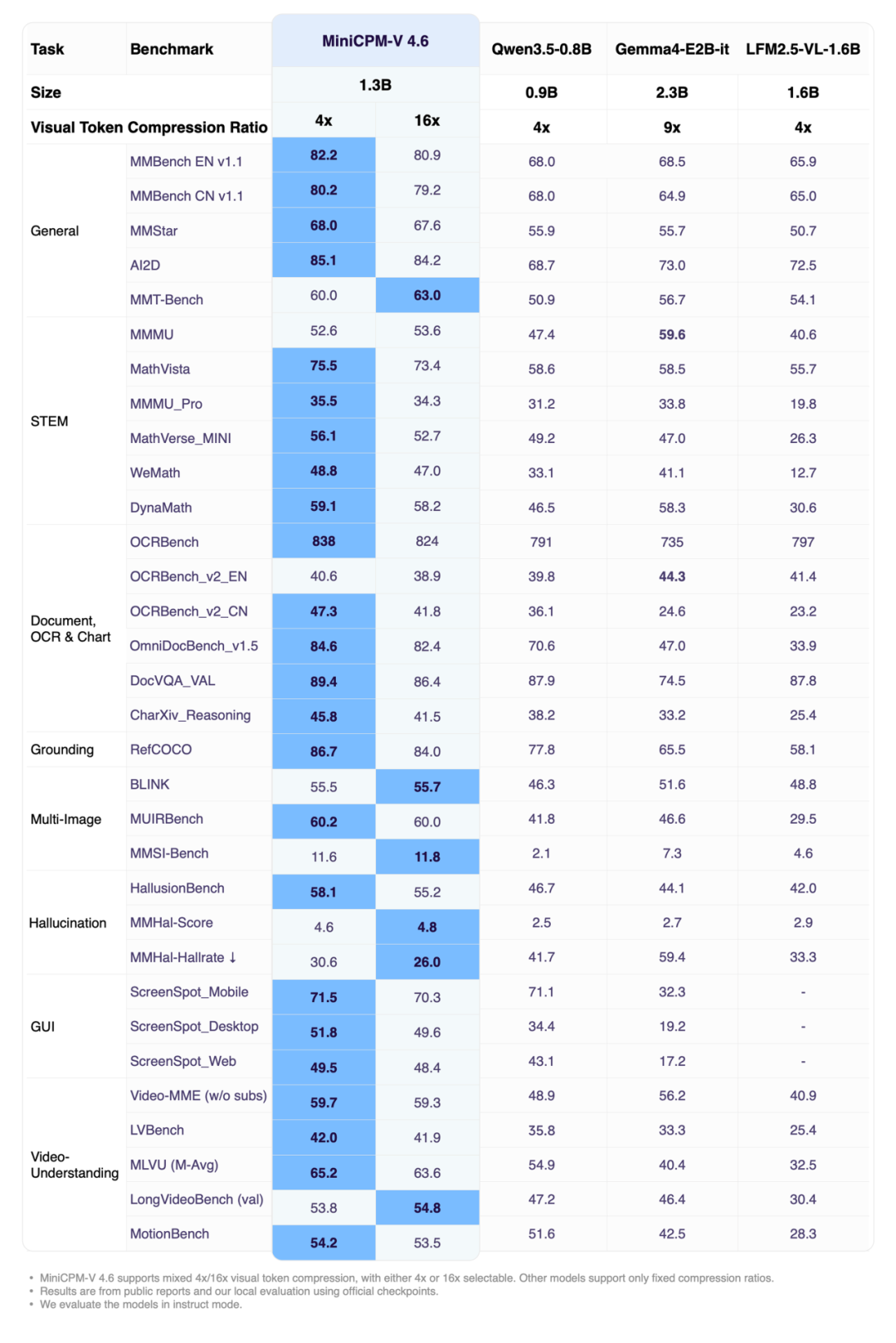
It is worth noting that the official Model Card provides an AutoProcessor and AutoModelForImageTextToText inference solution based on Transformers, which is suitable for rapid verification and application prototyping in a single GPU environment.
To facilitate rapid experience of this lightweight model for global developers, HyperAI has launched "MiniCPM-V-4.6: Efficient Multimodal Visual Language Model for Edge Applications". Environment configuration is complete, and online deployment of the model can be easily achieved.
Run online:https://go.hyper.ai/GVDmw
View related research papers:
https://hyper.ai/papers/2605.08985
More online tutorials:
Welcome to visit our official website for more information:
Demo Run
1. After entering the hyper.ai homepage, select the "Tutorials" page, or click "View More Tutorials", select "MiniCPM-V-4.6: Efficient Multimodal Visual Language Model for Devices", and click "Run this tutorial".
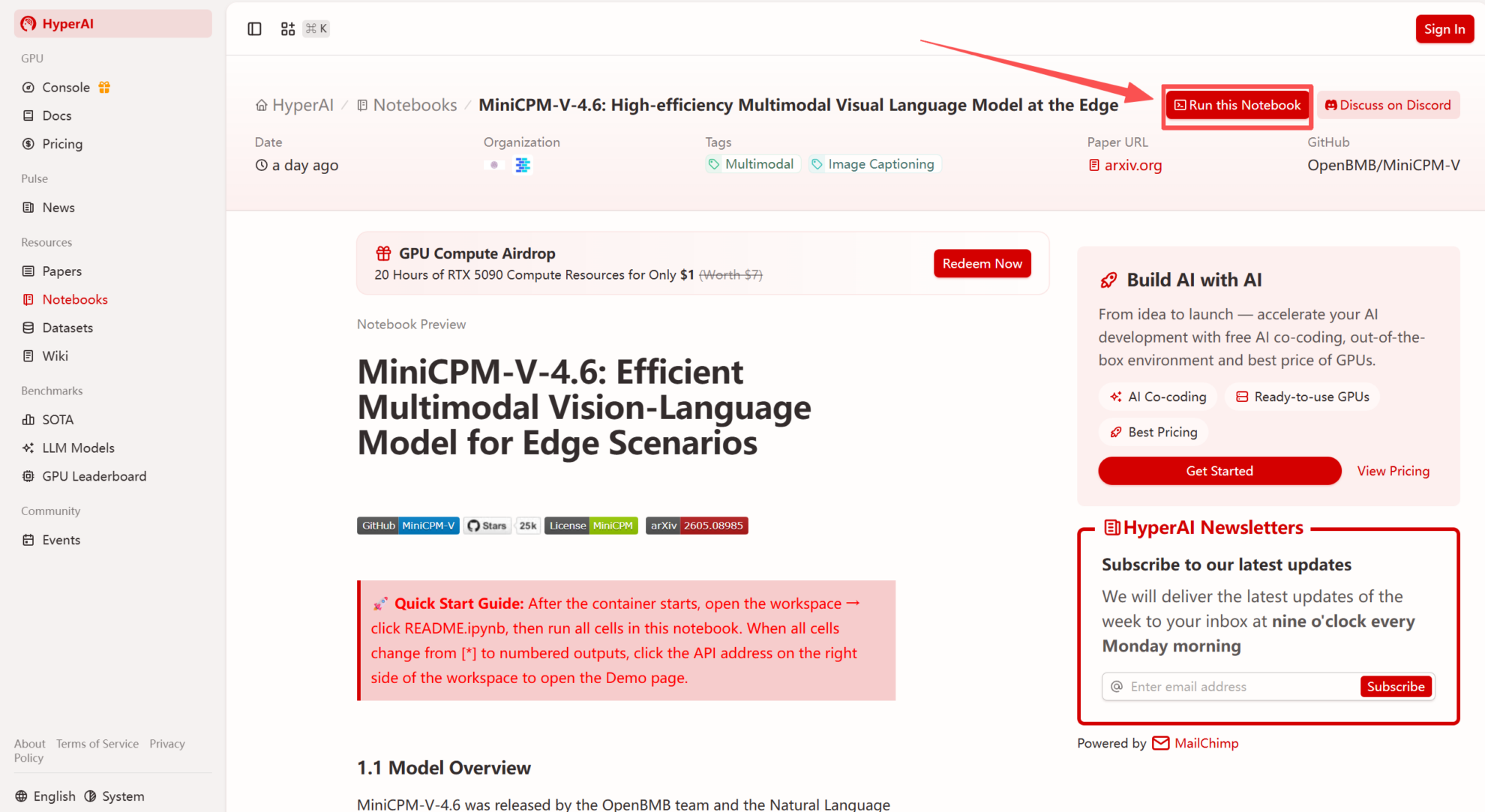
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
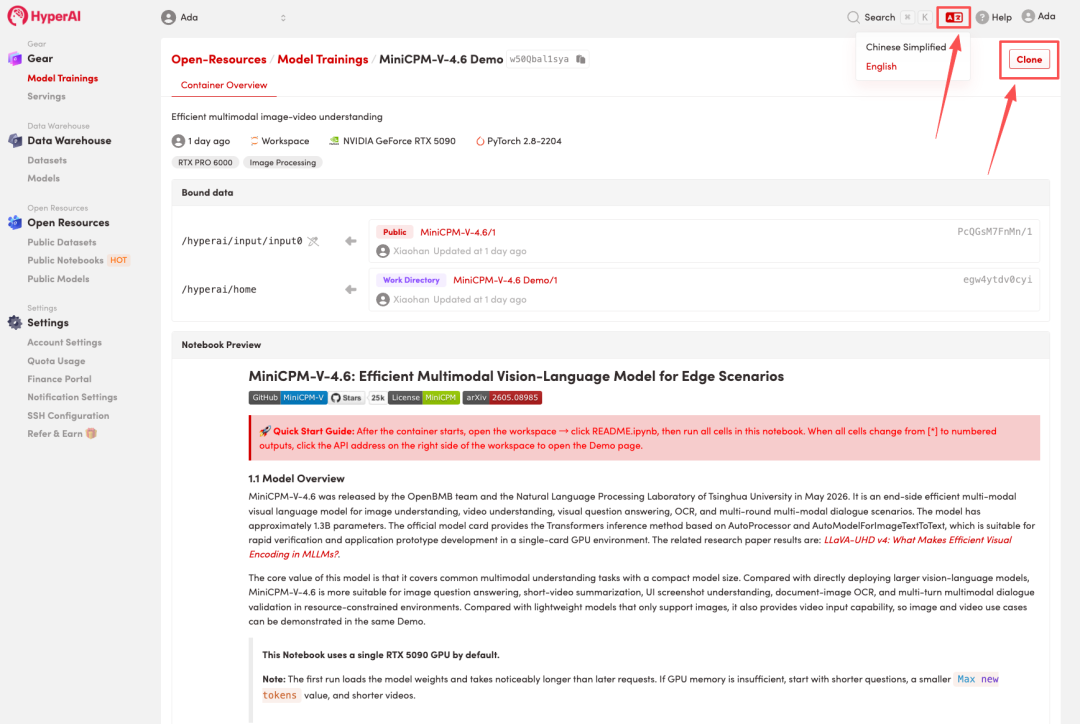
3. Select the "NVIDIA RTX 5090" and "PyTorch" images, and click "Continue job execution".
HyperAI is offering a registration bonus for new users: for just $1, you can get 20 hours of RTX 5090 computing power (originally priced at $7), and the resources are valid indefinitely.
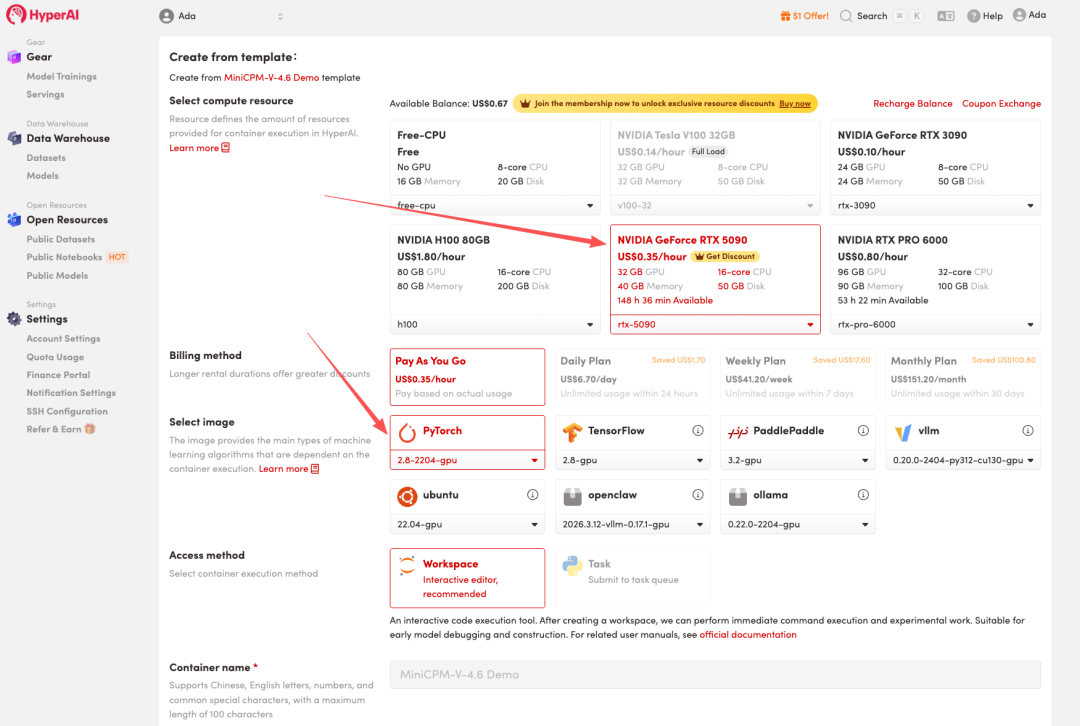
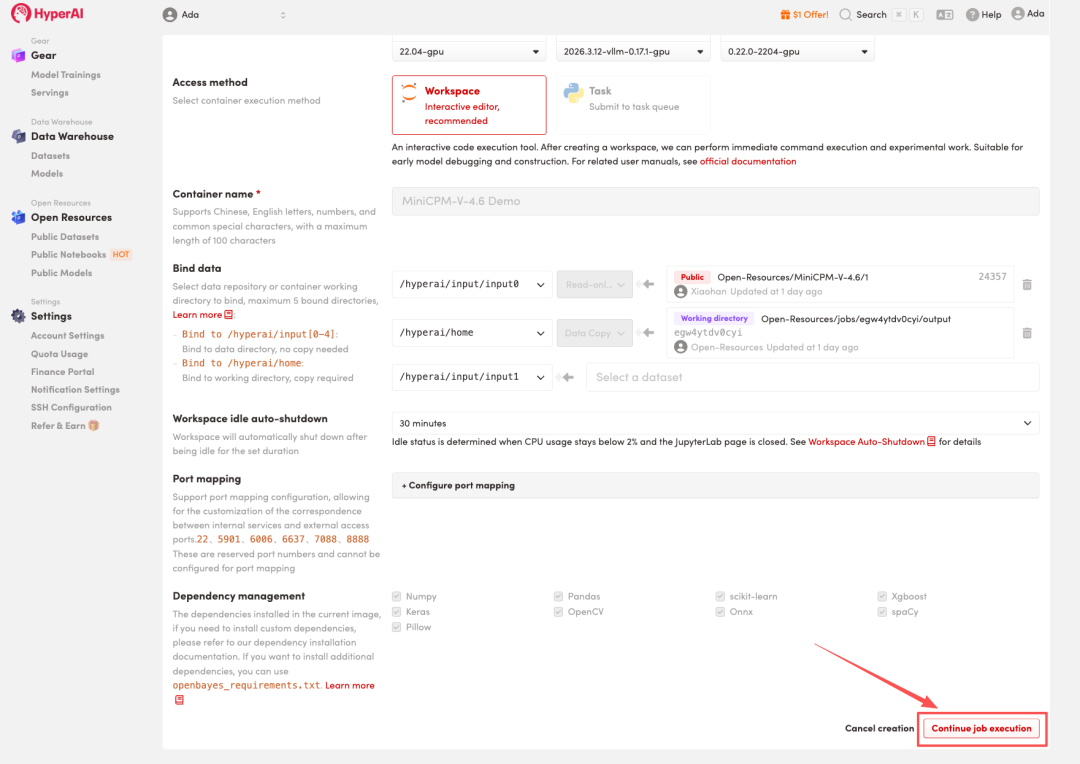
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
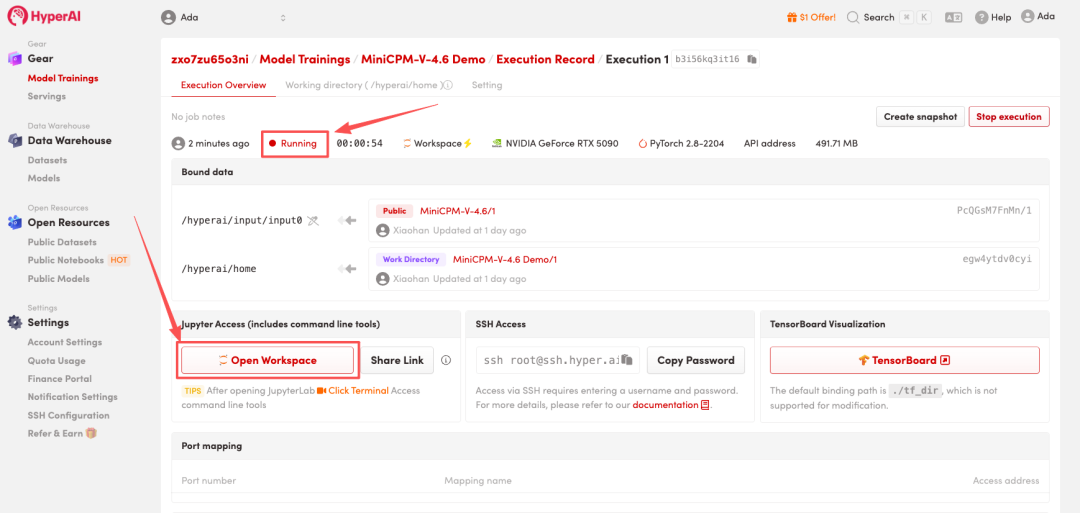
Effect display
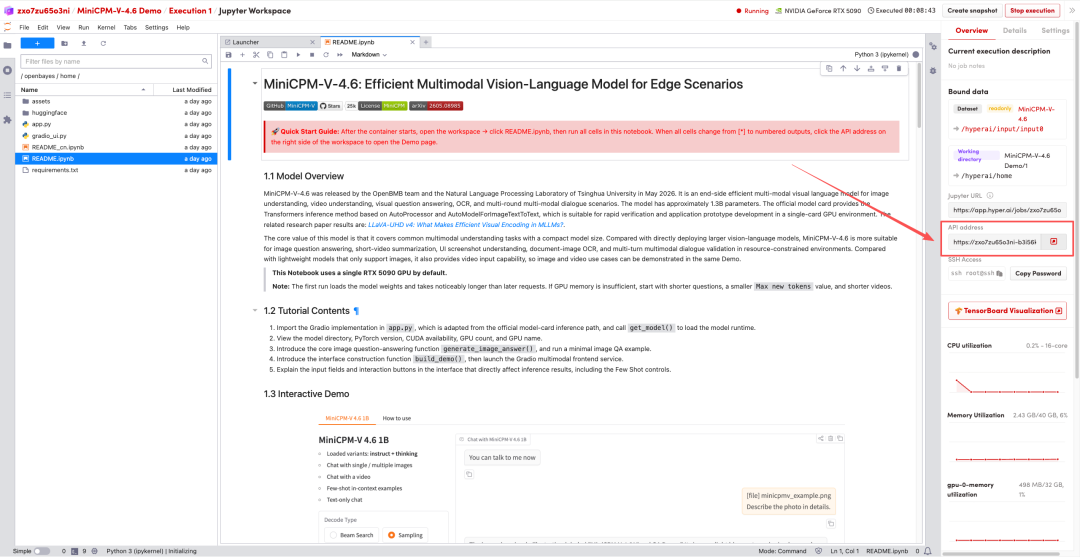
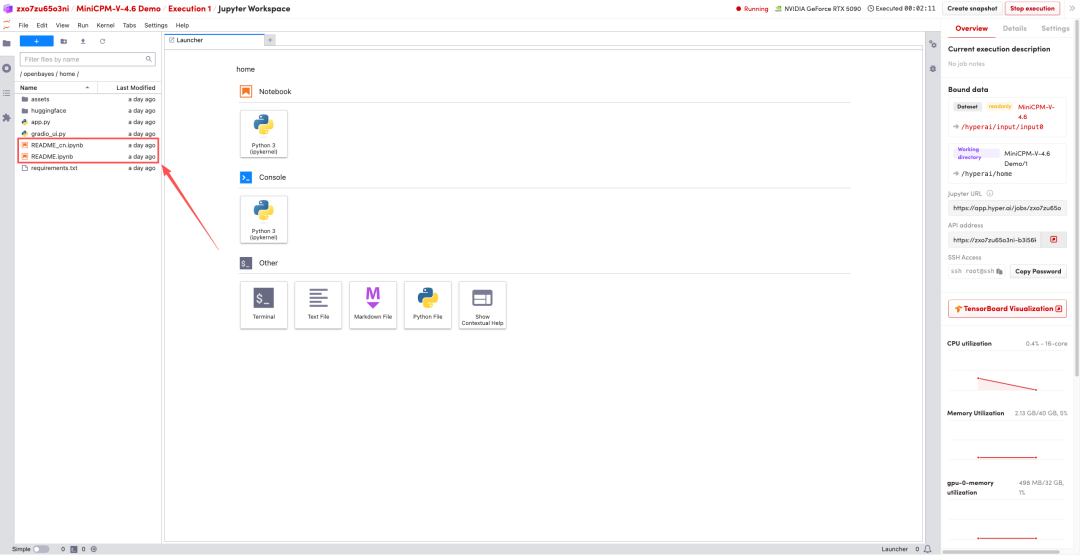
1. After the page redirects, click on the README file on the left, and then click on Run at the top.
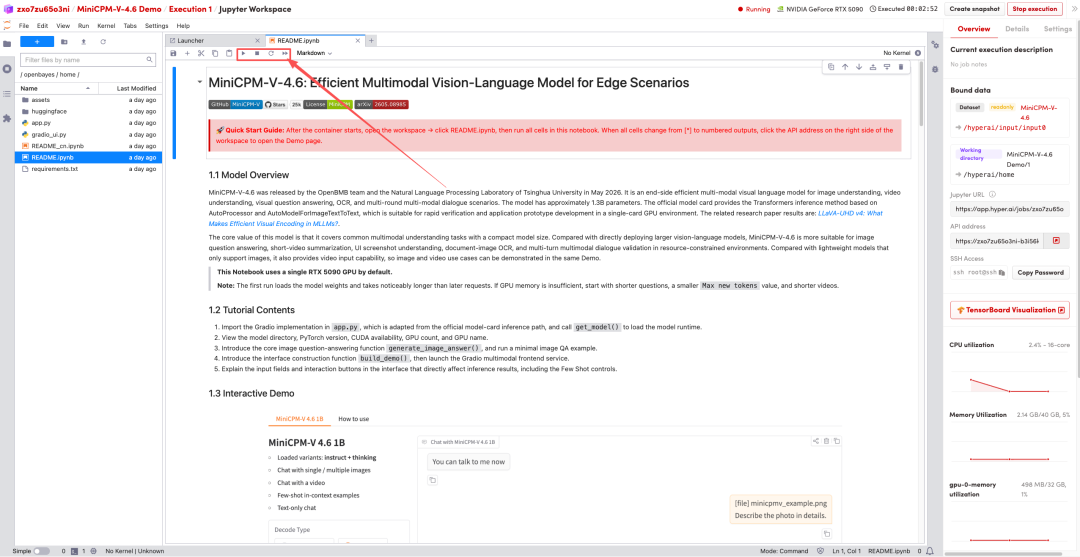
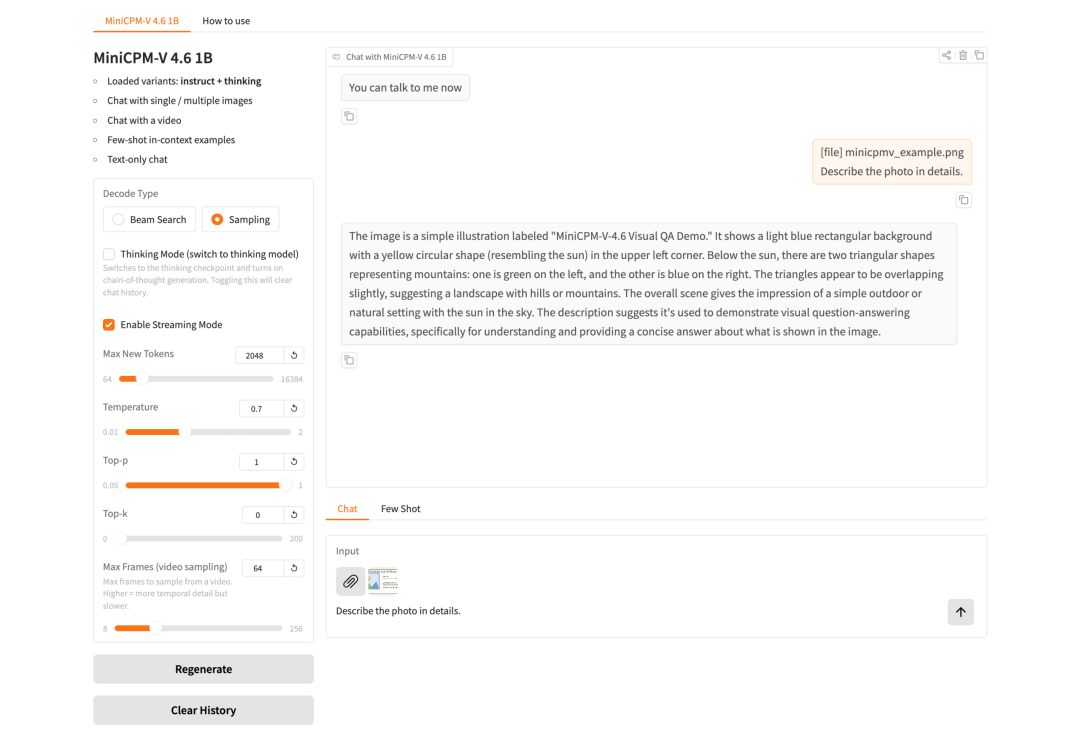
2. Once the process is complete, click the API address on the right to jump to the demo page.