Command Palette
Search for a command to run...
Based on Gemini, Which Processes News From 150 Countries, Google Has Released the open-source Flood Dataset Groundsource, Covering Over 2.6 Million Historical records.
Among various natural disasters worldwide, floods are one of the few types that combine high frequency of occurrence with immense destructive power, thus they have long been a core issue of concern in the fields of hydrology, climate science, and disaster management. From improving hydrological forecasting models and analyzing the impact of climate change on flood evolution, to assessing future flood risks and improving disaster prevention and mitigation systems,Almost all related studies rely on the same fundamental condition—high-quality historical flood data.These data serve as a key reference for verifying the reliability of the model and as an important basis for supporting risk assessment and policy decisions.
Traditional hydrological and meteorological observation stations are sparsely distributed, and the data quality varies, making it difficult to support the collection of large-scale, high-precision flood information. Currently, truly comprehensive flood datasets are few and far between. Although the Storm Events Database maintained by the U.S. National Center for Environmental Information is a typical example, such systematic records remain rare globally, and many countries have not yet established long-term flood event databases. Therefore, existing global flood datasets generally suffer from deficiencies in coverage and record completeness.
It is worth noting that a large amount of information about flood events has long been scattered within unstructured texts such as news reports and government documents. While past research has attempted to extract data from these sources, limitations in text standardization and high manual processing costs have hindered large-scale implementation. Recent advancements in generative artificial intelligence have offered a new breakthrough path for addressing this issue.
Recently, Google Research open-sourced the Groundsource flood dataset, which extracts validated ground information from unstructured data, enabling the mapping of historical disaster footprints with unprecedented accuracy.Researchers automated the processing of over 5 million news reports from more than 150 countries, ultimately compiling over 2.6 million records of historical flood events.It provides an unprecedented scale and coverage of data for global flood research.
at present,「The Groundsource Global Flood Events Dataset is now available on the HyperAI website (hyper.ai) in the datasets section.Online use:

Paper address:
https://eartharxiv.org/repository/view/12083/
Follow our official WeChat account and reply "Groundsource" in the background to get the full PDF.
Based on 5 million news articles, more than 2.6 million flood reports were sifted through.
The Groundsource dataset was built following a standardized, automated process. During the global data collection and entity recognition phases, the research team utilized some of Google's infrastructure, such as the WebRef named entity recognition system and the Read Aloud tool. However, the data extraction logic, the large language model suggestion framework, and the spatiotemporal aggregation rules are all publicly documented. Therefore, this process can still be reproduced in different technical environments after being replaced with open-source algorithms or other language models.
Data construction begins with the collection of news information.The research team used web crawlers to collect publicly available news reports published since 2000 and used WebRef to calculate a flood-themed relevance score for each article.The researchers set the threshold at 0.6.Preliminary screeningApproximately 9.5 million web pagesHowever, manual sampling revealed that only about half of them actually reported on the flood events, while the rest were merely mentioned in the background.
Then comes the text extraction stage.The system automatically removes advertisements and navigation elements from web pages, retaining only the article text and publication date, and filters out unparsed languages or inaccessible websites.The final number of usable articles was approximately 7.5 million.All non-English text will be translated into English, and the geographical location names will be extracted through entity recognition to form a candidate location database.
Identifying specific flood events from news texts is the most complex part of the entire process. Reports often contain multiple locations and vague time expressions, such as "yesterday" or "last week." Therefore,The research team designed a structured suggestion framework for the Gemini large language model and tested it using 250 manually annotated articles.The model used Google Read Aloud to extract raw text from 80 languages and then normalized it to English via the Cloud Translation API. The model then performed four tasks sequentially: determining whether the article described a real flood event, extracting and normalizing the event time, identifying specific locations affected by the flood, and matching place names to standard geographic identifiers.
Under this process,Of the 7.5 million articles, approximately 5 million were identified as containing real flood events.Based on manually labeled samples, the precision of event recognition is approximately 75%, and the recall is approximately 90%. The accuracy of date and location extraction is slightly lower, but it still provides effective spatiotemporal clues.
To locate these events on the map, the system also geocodes the locations: if an existing geographic entity can be matched, its spatial boundary is directly invoked; if no match can be found, the place name is converted into coordinates through a geocoding service, and a small buffer zone is generated if necessary for spatial analysis.
Finally, based on geographic identifiers and temporal information, the research team merged consecutively reported records into single flood events and performed quality control, removing records that were too broad in scope or had anomalous timing. After this series of processes,The results yielded over 2.64 million unique records, each corresponding to a flood observation captured in news reports at a specific time and location.
Dataset Evaluation: The 82% event has analytical value; its street-level precision fills a gap in small-scale disaster records.
To assess the reliability of the Groundsource dataset, thisThe study analyzes the data from three aspects: accuracy, spatiotemporal distribution, and consistency with external databases.It was compared with two major databases: the Global Disaster Alerts and Coordination System (GDACS) and the Dartmouth Flood Observatory (DFO).
In the accuracy assessment, researchers randomly selected 400 records and traced back to the original news sources to verify the time and location information. The results showed that the records that were strictly "accurate" accounted for 60% (95% confidence interval ± 5%).If records with slight biases but still of analytical value are included, approximately 82% of events can still be used for subsequent analysis.The remaining approximately 18% errors mainly stem from spatial positioning errors caused by ambiguity in place names, as well as misreading of relative time expressions such as "yesterday" and "last week".
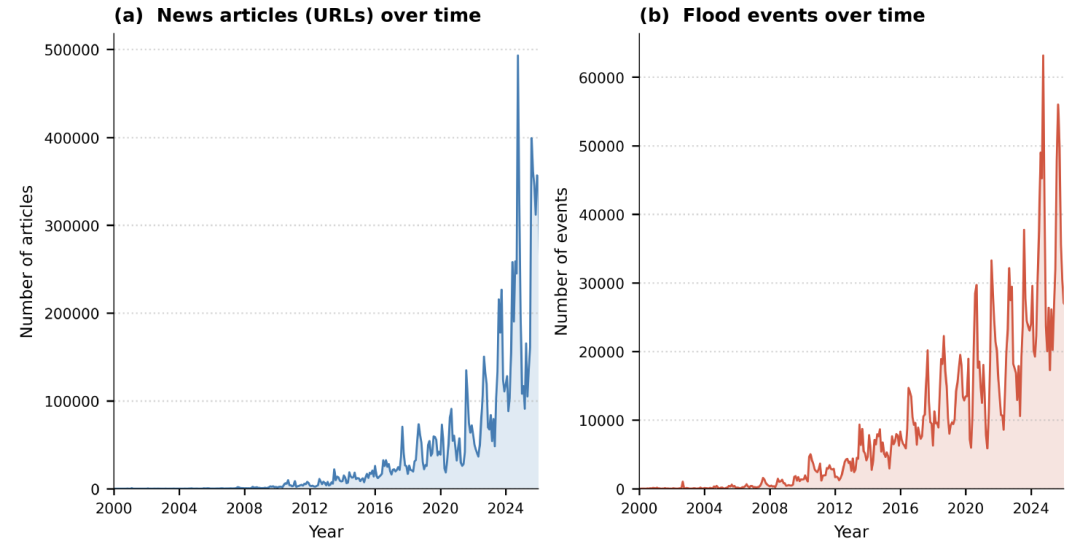
In terms of spatiotemporal distribution, the dataset exhibits a clear "recent bias".As shown in the figure below, approximately 641 TP3T of records are concentrated between 2020 and 2025, with 151 TP3T recorded in 2025 alone. This trend is more likely to reflect the rapid growth of digital news media than an increase in flood events themselves.
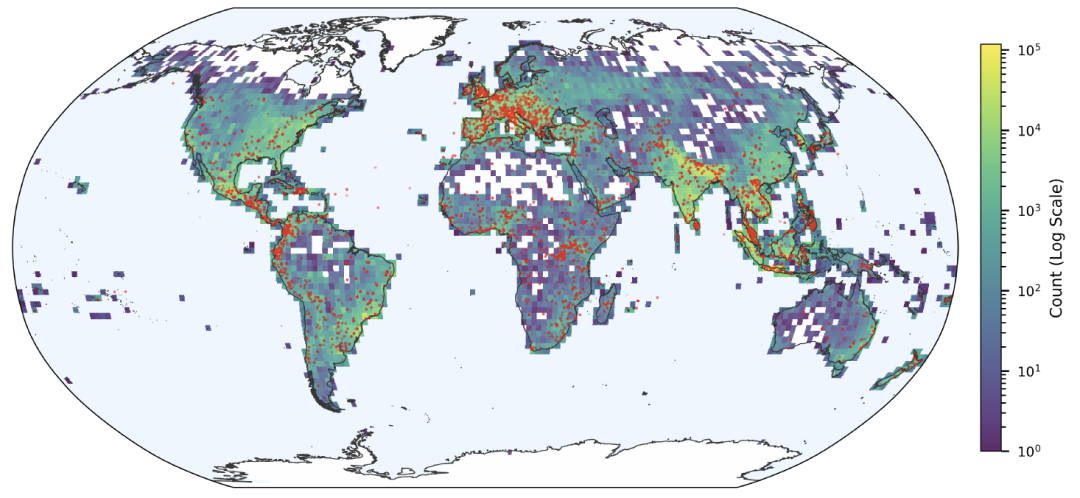
Spatial distribution is also influenced by the media ecosystem, with more events recorded in areas with intensive news coverage, and lower representativeness in areas with scarce digital news or insufficient language support. However, the data still clearly shows high-flood-prone areas such as Europe, South Asia, and Southeast Asia.Its spatial distribution is highly consistent with the locations of major floods recorded by GDACS.
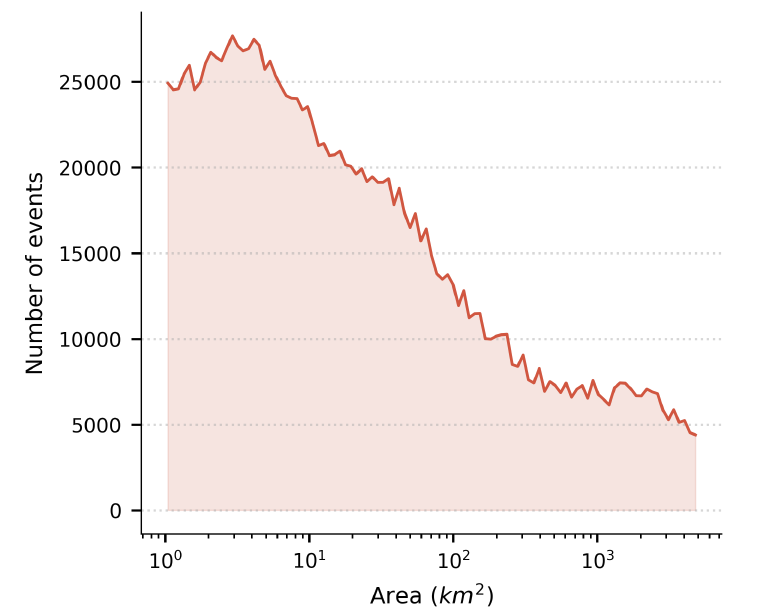
Despite reporting biases, Groundsource performs exceptionally well in terms of spatial resolution.Statistics show that the average coverage of extracted events is 142 square kilometers, of which 82% records are less than 50 square kilometers. Many events can be refined to the block or community scale, thus capturing localized floods that are often overlooked by traditional global disaster databases.
In the integrity assessment, the study compared Groundsource with the Global Disaster Alert and Coordination System (GDACS) and the Dartmouth Flood Observatory (DFO) through spatiotemporal matching. The results showed that since 2020, the recall rate for GDACS events ranged from 851 TP3T to 1001 TP3T; in regions with well-developed media infrastructure, such as the United States, the matching rates reached 961 TP3T (GDACS) and 911 TP3T (DFO), respectively. Furthermore,Recall rates are significantly correlated with the severity of disaster impact: recall rates for major flood events are close to or exceed 90%.
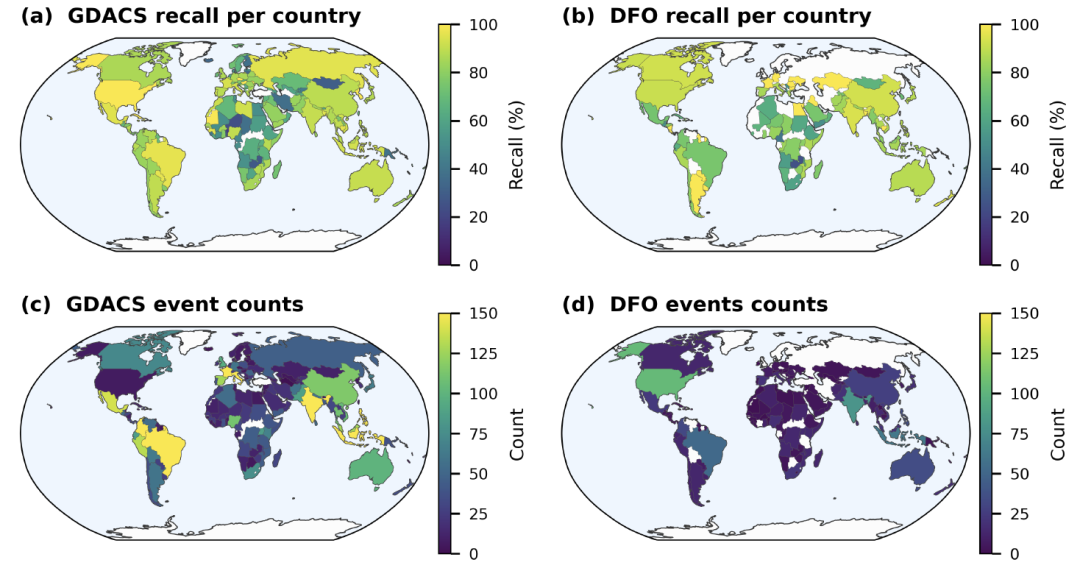
Overall, while Groundsource cannot provide perfectly balanced global coverage,However, with over 2.6 million records and high spatial resolution, it compensates for the shortcomings of traditional disaster databases in recording small-scale and localized flood events.This provides a new data source for global flood research.
AI-driven flood data research
Extracting standardized flood event information from unstructured text using large language models is gradually becoming an important method in the field of flood research.
In academia, many research teams have been continuously exploring this direction. Researchers at MIT have proposed an improved cue word strategy and context association method to address the temporal ambiguity and place name ambiguity problems commonly encountered by large language models in flood event extraction.By fine-tuning the model using historical hydrological observation data, the team improved the accuracy of flood event date extraction to over 80% and developed a multilingual adaptation module, enabling the model to handle news text in different languages more stably, thereby constructing a flood event dataset covering multiple regions.
Paper Title: Generating Physically-Consistent Satellite Imagery for Climate Visualizations
Paper link:
https://ieeexplore.ieee.org/document/10758300
The research team from the National University of Singapore has further expanded the application boundaries of their research.The team combined historical flood events extracted from news reports by AI with urban drainage network data and high-precision topographic information to establish an urban-scale flood risk assessment model.By analyzing the relationship between the frequency and extent of flooding in different regions and urban infrastructure, researchers are able to more clearly identify potential risk areas and provide more targeted references for urban flood control planning. They also attempt to assess the changing trends of future flood risks under extreme climate conditions.
Paper Title: Forecasting fierce floods with transferable AI in data-scarce regions
Paper link:
https://www.cell.com/the-innovation/fulltext/S2666-6758(24)00090-0
The progress of related research has also begun to extend to the industry.Microsoft Research has partnered with NASA to develop Hydrology Copilot, an AI-driven flood risk prediction platform.This system integrates flood event data extracted from news reports, satellite remote sensing information, and real-time hydrological monitoring data, using machine learning models to predict the probability of flood occurrence and the potential scope of impact. Currently, the platform is being piloted in the United States and several other countries to support local emergency management departments in improving their flood warning and response processes.
Overall, automatically extracting flood event information from news texts is gradually becoming an important source of supplementary traditional observational data. With the continuous improvement of model capabilities and data scale, this type of method is expected to provide a richer and higher-resolution data foundation for global flood risk research.
Reference Links:
1.https://www.geekwire.com/2025/microsoft-nasa-ai-hydrology-copilot-floods








