Command Palette
Search for a command to run...
WenetSpeech-Chuan Sichuan-Chongqing Dialect Speech Dataset
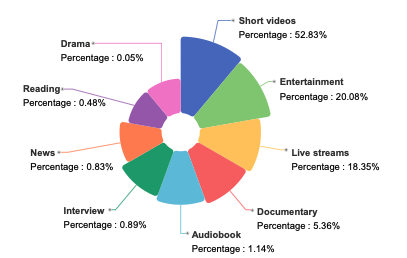
WenetSpeech-Chuan is a large-scale Sichuan-Chongqing dialect speech dataset released in 2025 by Northwestern Polytechnical University in collaboration with Hillbeak, China Telecom Artificial Intelligence Research Institute, and other institutions. The related research paper is titled "WenetSpeech-Chuan: A Large-Scale Sichuanese Corpus with Rich Annotation for Dialectal Speech Processing". This dataset contains 10,013 hours of authentic Sichuan and Chongqing dialect speech, including 3,714 hours of strongly labeled data and 6,299 hours of weakly labeled data. The data covers nine real-world scenarios, with short videos accounting for 52.831 TP3T, and the remainder including entertainment, live streaming, audiobooks, documentaries, interviews, news, reading, and TV dramas, presenting a highly diverse and realistic speech distribution. All speech is accompanied by rich annotation information, such as text content, confidence level, voice quality score, speaker's gender and age, and emotion tags.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.