Command Palette
Search for a command to run...
BRIGHT Text Retrieval Benchmark Dataset
Date
Size
Publish URL
Paper URL
* This dataset supports online use.Click here to jump.
This dataset is a new text retrieval benchmark launched in 2024 by the University of Hong Kong, Princeton University, University of Washington, and Google Cloud AI Research.BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval".
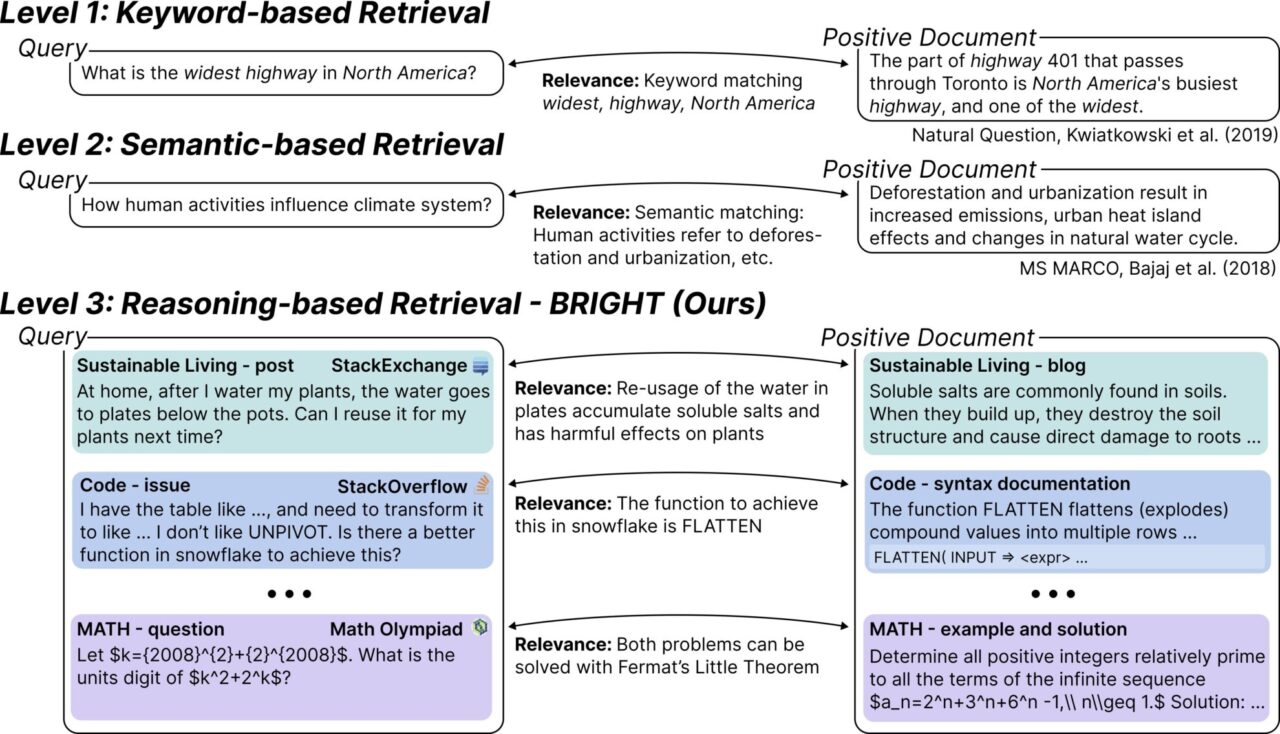
BRIGHT is the first text retrieval benchmark that requires deep reasoning to retrieve relevant documents. The research team collected 1,385 real queries from different fields (StackExchange, LeetCode, and math competitions), all of which are from real artificial data. The team paired these queries with web pages linked in StackExchange answers and theorems marked in Mathematical Olympiad problems.
It is specifically designed to evaluate and challenge the performance of retrieval systems when handling complex queries. These queries require not only keyword matching, but also deep reasoning capabilities to identify relevant documents. Simply put, BRIGHT tests whether the retrieval system can "understand" the logic and context behind the query, not just the surface text. For example, an economist wants to find documents about "how human activities affect the climate system." This question is not just about keyword matching, but requires understanding the relationship between human activities (such as deforestation and urbanization) and climate change.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.