Command Palette
Search for a command to run...
LinCE Language Conversion Dataset
Date
Publish URL
Paper URL
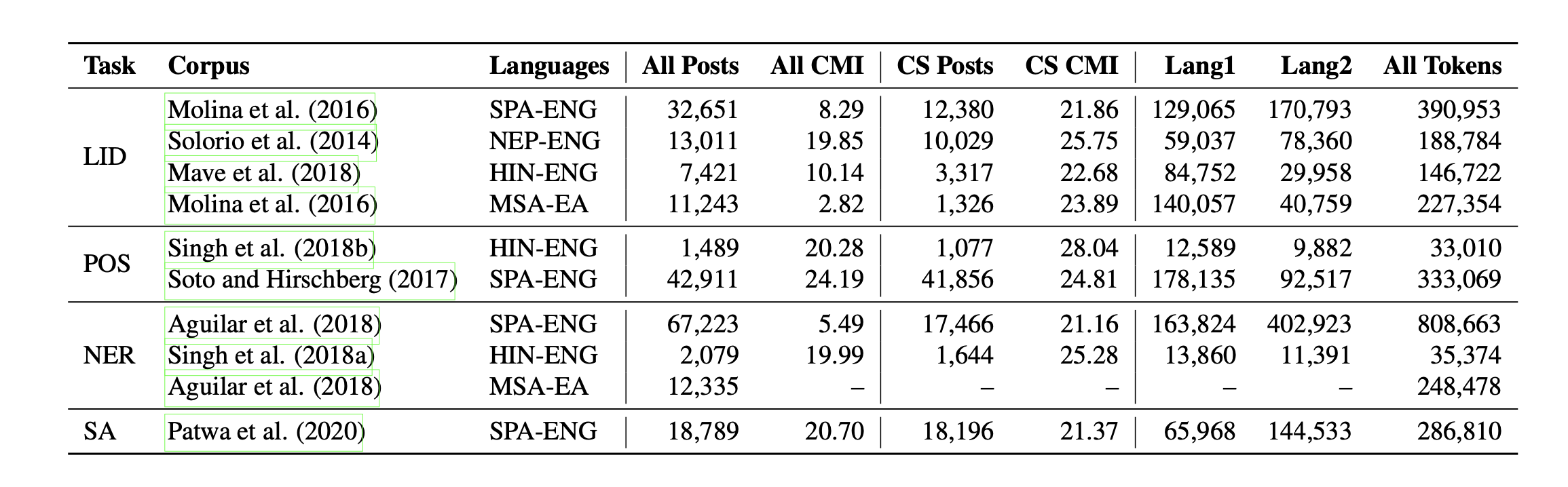
LinCE stands for Linguistic Code-switching Evaluation Dataset, which is a language code switching evaluation dataset. The dataset combines ten corpora covering four different code switching language pairs (Spanish-English, Nepali-English, Hindi-English, and Modern Standard Arabic-Egyptian Arabic). The dataset completes four tasks, namely language identification, named entity recognition, part of speech labeling, and sentiment analysis. The dataset also provides scores for different popular models, including LSTM, ELMo, and multilingual BERT, so that the NLP community can compare with the most advanced systems.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.