Command Palette
Search for a command to run...
Visual Genome Densely Annotated Dataset
Date
Size
Organization
Publish URL
Paper URL
License
CC BY 4.0
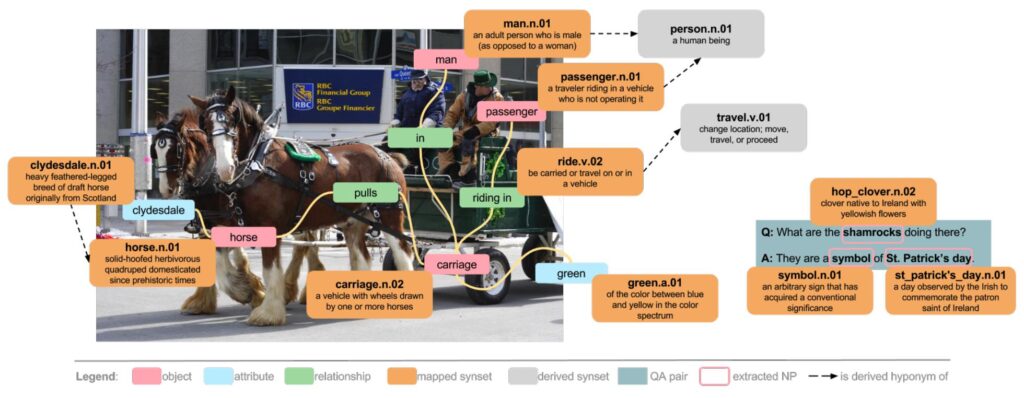
The Visual Genome Dataset is a dataset that connects language and vision through crowdsourced dense image annotation, including Visual Question Answering data in a multiple-choice environment. The dataset consists of 1.7 million QA pairs for 101,174 MSCOCO images, with an average of 17 questions per image. Compared to the Visual Question Answering dataset, the Visual Genome dataset has a more balanced distribution of six types of questions: What, Where, When, Who, Why, and How. In addition, Visual Genome also displays 108,000 images densely annotated with targets, attributes, and relationships.
Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.